Abstract
最近提出的目标检测剔除了许多手工设计的组件,同时展示了良好的性能。
然而,由于Transformer注意模块在处理图像特征映射时的局限性,导致其收敛速度慢,特征空间分辨率有限。
为了缓解这些问题,这篇文章提出了 Deformable DETR,其注意力模块只关注参考点周围的一小组关键采样点。
Deformable DETR 比 DETR(特别是在小物体上)可以在少10x 训练时间的情况下获得更好的性能。
在COCO基准上的大量实验证明了该方法的有效性。
Revisiting Transformers and DETR
Multi-Head Attention in Transformers. Transformers(Vaswani等人,2017年)是一种基于机器翻译注意力机制的网络架构。给定一个 query element(例如,输出句子中的目标单词)和一组 key elements(例如输入句子中的源词),多头注意力模块根据测量 query-key pairs 兼容性的注意权重自适应地聚合关键内容。为了允许模型专注于来自不同表示子空间和不同位置的内容,不同注意力头的输出线性地聚合了可学习的权重。
Method
Deformable Transformers for End-to-End Object Detection
Deformable Attention Module. 在图像上应用 Transformer attention特征图的核心问题是,它将查看所有可能的空间位置。为了解决这个问题, 作者提出 deformable attention 模块。受启发与 deformable convolution, deformable attention 模块只关注参考点周围的一小部分关键采样点,无论特征图的空间大小如何,如图2所示。通过只为每个 query 分配少量固定的 key,可以缓解收敛和特征空间分辨率的问题。
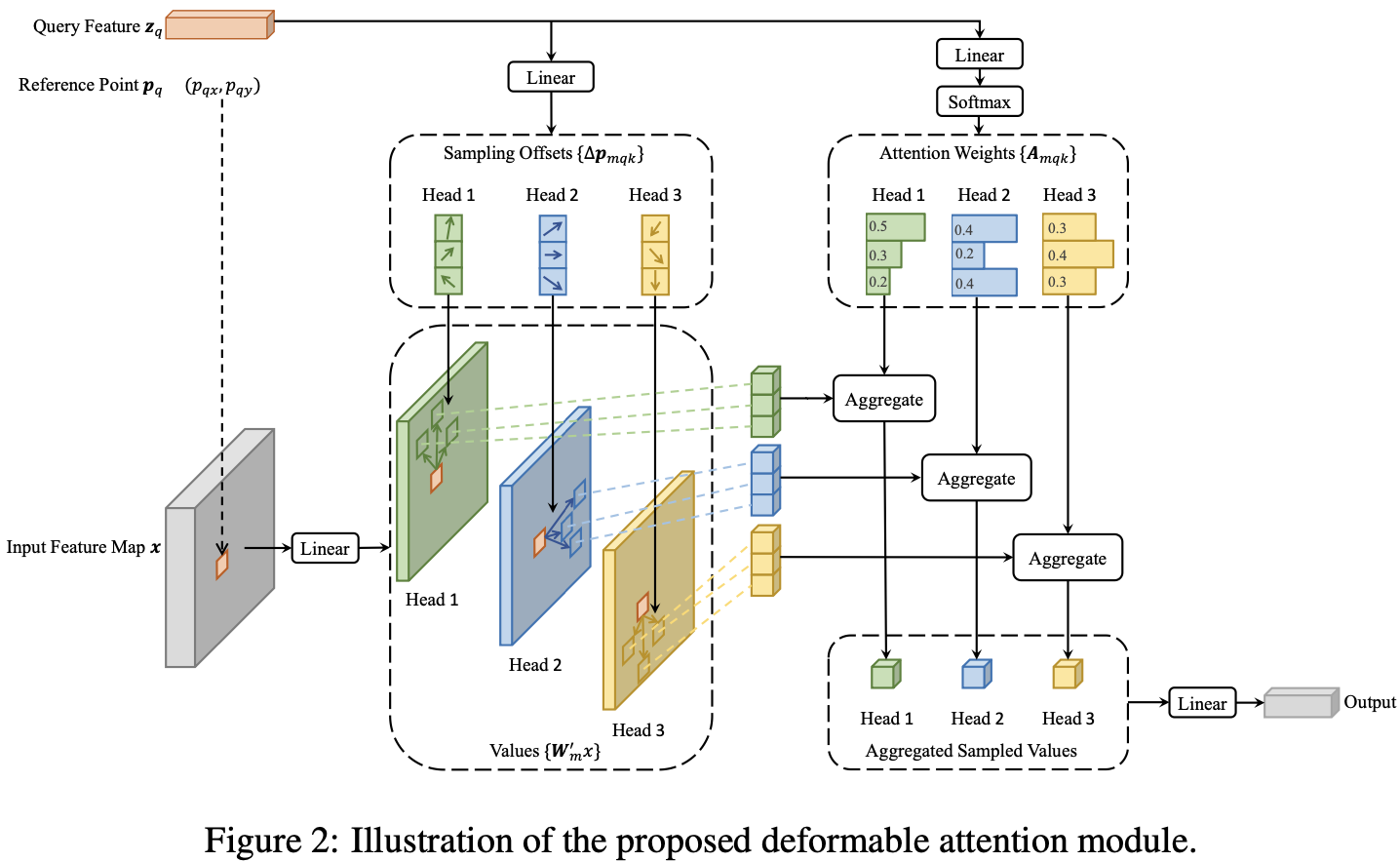
给定输入特征图 $x \in \mathbb{R}^{C \times H \times W}$, 令 $q$ 索引 content feature $z_q$ 的 query element 和 一个 2-d reference point $p_q$, deformable attention feature的计算如下:
\(\text{DeformAttn}(z_q, p_q, x) = \sum_{m=1}^M W_m [\sum_{k=1}^K A_{mqk} · W_m' x(p_q + \Delta p_{mqk})]\) $m$ 索引 attention head, $k$ 索引采样的 key,并且 $K$ 是总采样的键值数量($K « HW$)。$\Delta p_{mqk}$ 和 $A_{mqk}$ 分别表示第 $m^{th}$ 个 attention head 中的第 $k^{th}$ 个采样点的采样偏移量和注意力权重。scalar attention weight $A_{mqk}$ 的值域在 [0, 1] 之间, 由 $\sum_{k=1}^K A_{meqk} = 1$ 规范化。$\Delta p_{mqk} \in \mathbb{R}^2$ 是无约束范围的 2-d 实数。
Conclusion
Deformable DETR 是一种高效、快速收敛的端到端目标检测方法。
它使我们能够探索更有趣和更实用的端到端物体探测器。
Deformable DETR 的核心是多尺度的 deformable attention 模块,它是处理图像特征图的一种有效的注意力机制。
-
Previous
【深度学习】MIMO-UNet:Rethinking Coarse-to-Fine Approach in Single Image Deblurring -
Next
【深度学习】GAP-TV:GENERALIZED ALTERNATING PROJECTION BASED TOTAL VARIATION MINIMIZATION FOR COMPRESSIVE SENSING