Abstract
在这份报告中,作者介绍了PP-YOLOE,一种高性能和友好部署的工业最先进的目标检测器。
作者在之前PP-YOLOv2的基础上进行优化,使用 Anchor-free 范式,更强大的 backbone 和 neck, 使用了cspresstage, ET-head和动态标签分配算法 TAL。
结果,PP-YOLOE-l在COCO test-dev 上实现了51.4 mAP,在 Tesla V100上实现了 78.1 FPS,与之前最先进的工业型PP-YOLOv2 和 YOLOX 相比,分别取得了(+1.9 AP,+ 13.35%加速)和(+1.3 AP,+24.96%加速)的显著提升。
此外,加上TensorRT和fp16, PP-YOLOE推理速度达到149.2 FPS。
Method
A Brief Review of PP-YOLOv2
PP-YOLOv2的整体架构包括带有可形变卷积[34]的ResNet50-vd[10] Backbone、带有SPP层和DropBlock[7]的PAN neck以及 lightweight IoU aware head。 在PP-YOLOv2中,Backbone 使用 ReLU 激活函数,neck 使用 mish 激活函数。和YOLOv3一样,PP-YOLOv2只为每个真实目标分配一个 anchor。除了分类损失、回归损失和 objectness loss 外,PP-YOLOv2还使用 IoU loss 和 IoU aware loss 来提高性能。详情请参考[13]。
Improvement of PP-YOLOE
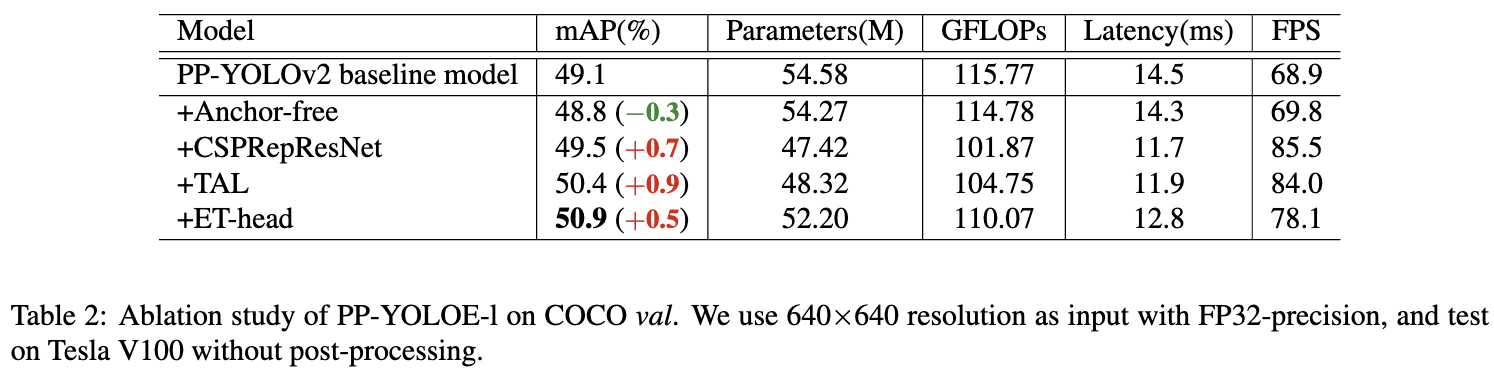
Anchor-free. 如上所述,PP-YOLOv2[13]以一种基于 Anchor 的方式标记 ground truths。 然而,Anchor 机制引入了大量的超参数,并依赖于手工设计,这可能不能很好地泛化到其他数据集。基于上述原因,作者在PP-YOLOv2中引入了Anchor-free 方法。按照FCOS[25]在每个像素上 tiles 一个 anchor point,为三个 detection heads 设置 upper bounds 和 lower bounds,将ground truth分配给对应的feature map。然后计算 bbox 的中心,选择距离最近的像素作为正样本。和YOLO系列一样,预测一个4D向量(x, y, w, h)进行回归。此修改使模型速度稍快,损失0.3 AP,如表2所示。虽然根据PP-YOLOv2的 Anchor 尺寸精心设置了上界和下界,但基于 Anchor 和 Anchor-free 的赋值结果仍存在一些小的不一致,可能导致精度下降。
Backbone and Neck. Residual 连接[9,29,11]和 Dense 连接[12,15,20]在现代卷积神经网络中得到了广泛的应用。残差连接引入 shortcut 来解决梯度消失问题,也可以看作是一种模型集成方法。Dense 连接聚合具有不同感受野的中间特征,在目标检测任务中表现出良好的性能。CSPNet[27]利用 cross stage dense connections,在不损失精度的情况下降低了计算负担,在YOLOv5[14]、YOLOX[6]等有效的目标检测器中很受欢迎。VoVNet[15]和随后的TreeNet[20]在目标检测和实例分割方面也表现出了优越的性能。受这些作品的启发,作者提出了一种新的 RepResBlock,通过结合 Residual 连接和 Dense 连接,它被用于 Backbone 和 neck。
来自TreeBlock[20],RepResBlock 在训练阶段如图3(b)所示,在推断阶段如图3(c)所示。首先,作者对原始的TreeBlock进行简化(图3(a))。然后,我们将 concatenation 操作替换为 element-wise add 操作(图3(b)),因为 RMNet[19] 在一定程度上显示了这两个操作的近似。因此,在推断阶段,可以以 RepVGG[4] 的方式重新参数化的ResNet-34使用的一个基本的残差块(图3(c))。
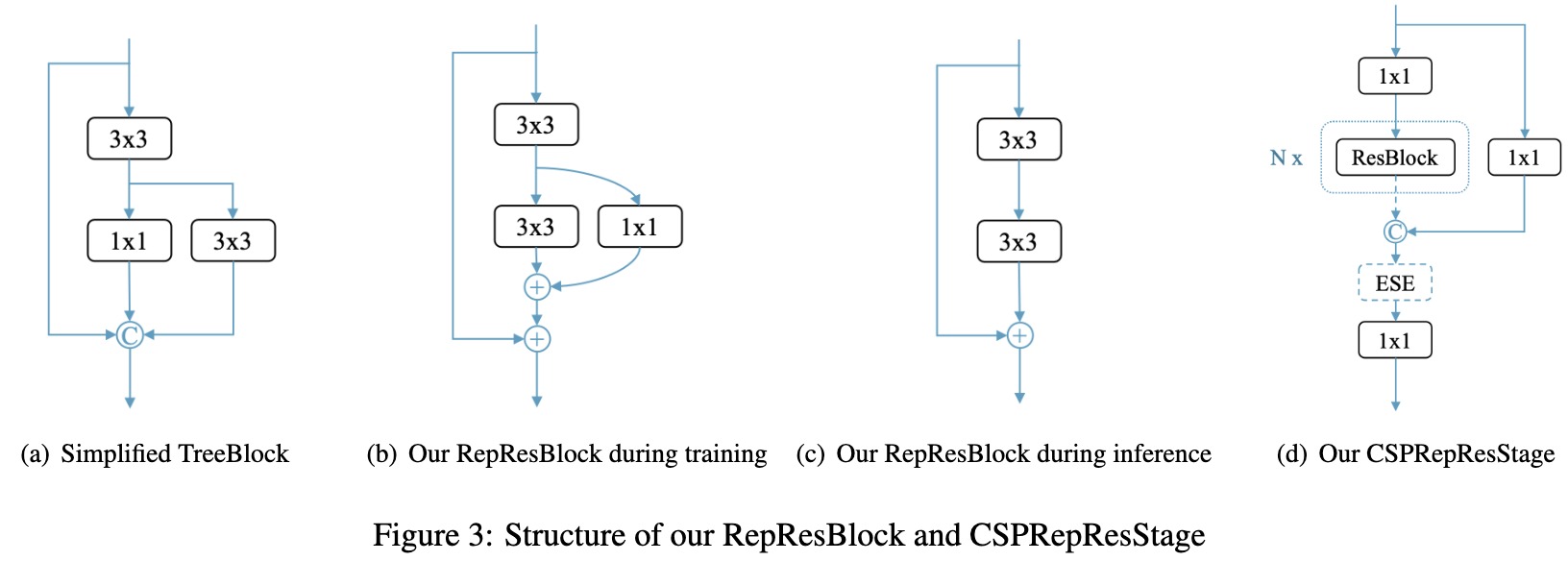 作者使用提出的 RepResBlock来构建 backbone 和 neck。与ResNet类似,我们的主干名为CSPRepResNet,它包含一个stem,其由三个卷积层和 RepResBlock 堆叠的四个后续阶段组成,如图3(d)所示。每一级采用 cross stage partial connections ,避免了大量的 $3 \times 3$ 卷积层带来的大量参数和计算负担。在构建主干时,还使用了ESE (Effective Squeeze and extraction)层在每个 CSPRepResBlock 中施加通道注意力。和PP-YOLOv2[13]一样,使用提出的RepResBlock和CSPRepResStage 构建 neck。与backbone不同的是,在 neck 去除了 RepResBlock中的shortcut和CSPRepResStage中的 ESE 层。
作者使用提出的 RepResBlock来构建 backbone 和 neck。与ResNet类似,我们的主干名为CSPRepResNet,它包含一个stem,其由三个卷积层和 RepResBlock 堆叠的四个后续阶段组成,如图3(d)所示。每一级采用 cross stage partial connections ,避免了大量的 $3 \times 3$ 卷积层带来的大量参数和计算负担。在构建主干时,还使用了ESE (Effective Squeeze and extraction)层在每个 CSPRepResBlock 中施加通道注意力。和PP-YOLOv2[13]一样,使用提出的RepResBlock和CSPRepResStage 构建 neck。与backbone不同的是,在 neck 去除了 RepResBlock中的shortcut和CSPRepResStage中的 ESE 层。
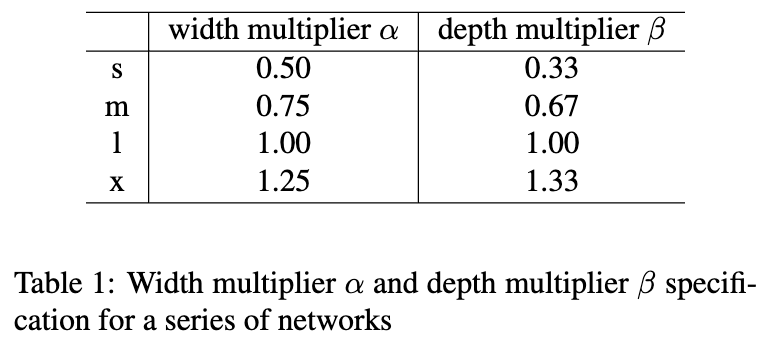
作者使用 width multiplier $\alpha$ 和 depth multiplier $\beta$ 来共同缩放基本的 backbone 和 neck,就像YOLOv5[14]。由此,我们可以得到一系列不同参数、不同计算量的检测网络。基本 backbone 的 width 设定为 [64, 128, 256, 512, 1024]。 除 stem 外,基本 backbone 的深度设置为[3,6,6,3]。基本 neck 的 width 和 depth 分别设定为 [192, 384, 768] 和 3。 表1给出了不同的 width multiplier 和 depth multiplier的规格。这种修改可以获得 0.7% 的AP性能提升性能提升,如表2所示。
Task Alignment Learning(TAL). 为了进一步提升准确率, 标签分配是需要考虑的另一个方面。标签分配是需要考虑的另一个方面。YOLOX使用SimOTA作为标签分配策略来提高性能。然而,为了进一步克服分类和定位的 misalignment,在TOOD[5]中提出了task alignment learning(TAL),该学习由 dynamic label assignment 和任务对齐损失组成。Dynamic label assignment 意味着 prediction/loss aware。 根据预测结果,为每个标签分配动态数量的 positive anchors。 通过明确对齐两个任务,TAL可以同时获得最高的分类分数和最精确的边界框。
对于任务对齐损失, TOOD 使用一个标准化的 $t$,即 $\hat t$ 来替换 loss 中的目标。它采用每个实例中最大的 IoU 归一化。 分类的 Binary Cross Entropy(BCE) 可以重写为:
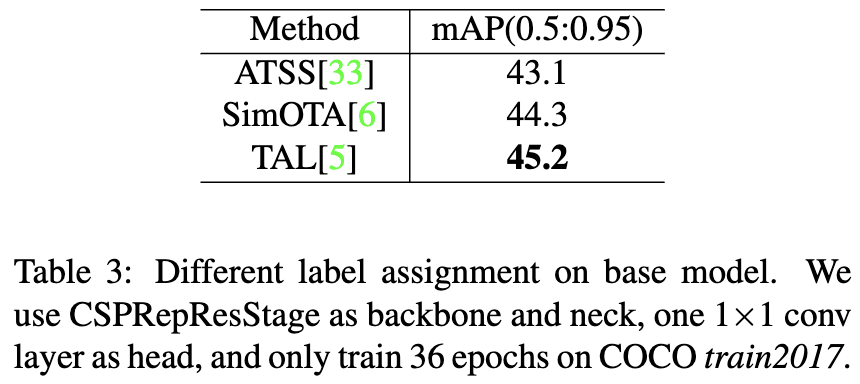
\[L_{cls-pos} = \sum_{i=1}^{N_{pos}} BCE(p_i, \hat t_i)\]作者使用不同的标签分配策略来研究其性能。作者在上述修改后的模型上进行了实验,该模型以 CSPRepResNet 为 backbone。为了快速得到验证结果,作者只在COCO train2017 上进行了 36 个 epoch 的训练,并在COCO val上进行了验证。如表3所示,TAL取得了最好的45.2%的AP性能。作者使用 TAL 代替 FCOS 的标签分配,取得了 0.9% AP的提高,如表2所示。
Efficient Task-aligned Head (ET-head). 在目标检测中,分类与定位之间的任务冲突是一个众所周知的问题。许多文献[5,32,16,30]都提出了相应的解决方案。YOLOX的 decoupled head 吸取了大多数 one-stage 和 two-stage 检测器的经验,成功地应用于YOLO模型,提高了精度。然而,decoupled head 可能使分类和定位任务分离和独立,缺乏 task specific learning。基于 TOOD, 作者改进了 head,提出了ET-head,目标是兼顾速度和准确性。如图2所示,作者使用 ESE 代替 TOOD 中的 layer attention,将分类分支的对齐简化为shortcut,将回归分支的对齐替换为 distribution focal loss(DFL)层[16]。 通过以上改动,ET-head在V100上增加了0.9ms。
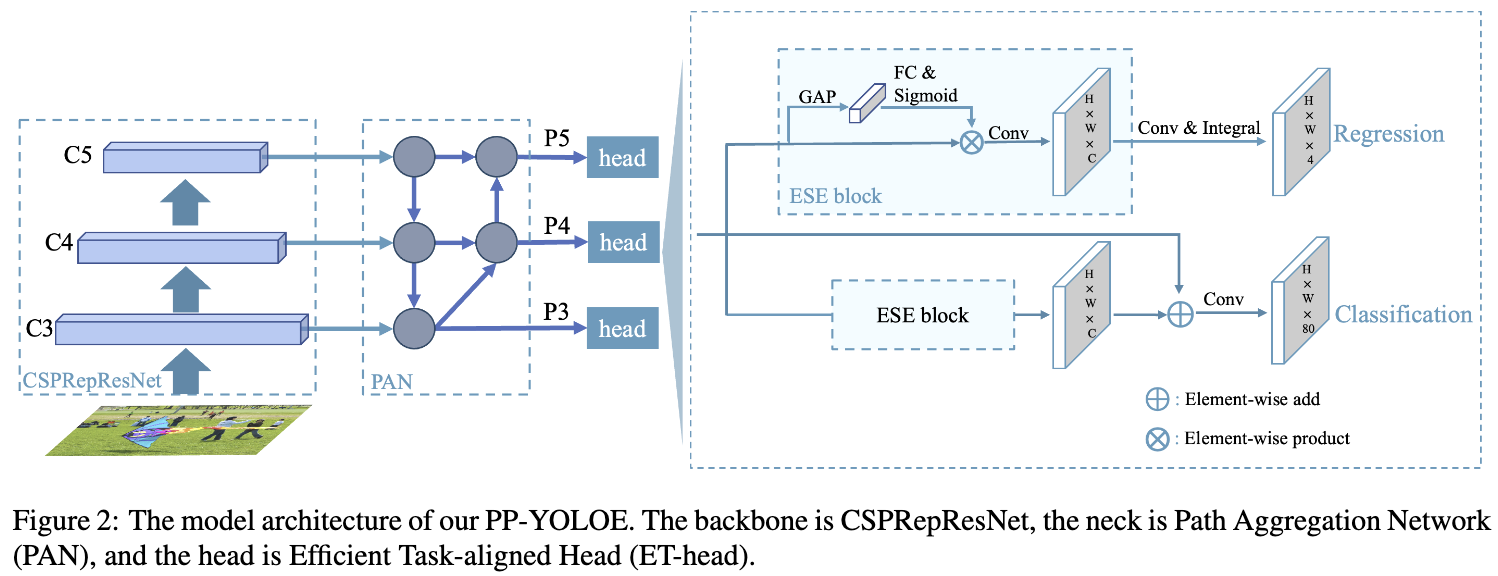
对于分类和定位任务的学习,作者分别选择了varifocal loss (VFL)和distribution focal loss (DFL)。PP-Picodet[31]成功地将VFL和DFL应用于目标检测器中,性能得到了提高。对于[32]的VFL,不同于[16]的 quality focal loss(QFL), VFL使用目标评分来加权正样本的损失。 这使得 IoU 的正样本对损失的贡献相对较大。这也使得模型在训练时更加关注高质量的样本而不是低质量的样本。同样的,两者都以 IoU-aware classification score (IACS) 为目标进行预测。该方法可以有效地学习分类分数和定位质量估计的联合表示,实现训练和推理的高度一致性。对于DFL,为了解决边界框表示不灵活的问题,[16]提出使用 general distribution 来预测边界框。最终模型的损失函数为:
\(Loss = \frac{\alpha · loss_{VFL} + \beta · loss_{G_{IoU}} + \gamma · loss_{DFL}}{\sum_i^{N_{pos}} \hat t}\) 其中 $\hat t$ 表示规范化后的目标分数, 见等式 (1)。
Conclusion
这份报告介绍了PP-YOLOv2的几个更新,包括 scalable backbone-neck 结构,高效的 task aligned head,先进的 label assignment strategy 和精细的目标损失函数,形成了一系列高性能的目标探测器称为PP-YOLOE。
此外, 作者提供了 s/m/l/x 模型以覆盖不同的实际场景。
此外,这些模型可以顺利过渡到部署,有PaddlePaddle官方支持。
-
Previous
【深度学习】DIP:Deep Image Prior -
Next
【深度学习】PP-YOLO: An Effective and Efficient Implementation of Object Detector