Abstract
effective 和 efficient 是实用的目标检测器的基本要求。
为了满足这两个问题,作者综合评估了一系列现有的改进,以提高PP-YOLO的性能,同时几乎保持推理时间不变。
这篇文章将分析一系列改进措施,并通过增量消融研究,实证评估它们对最终模型性能的影响。
通过结合多种有效的改进,作者将PP-YOLO在COCO2017 test-dev 中的性能从45.9% mAP提升到49.5% mAP。
由于已经取得了显著的性能提升,作者提出PP-YOLOv2。
在速度方面,PP-YOLOv2以68.9FPS和640x640输入大小运行。
采用TensorRT、FP16-precision和 batchsize = 1 的 Paddle inference 引擎,进一步提高了PP-YOLOv2的推理速度,达到106.5 FPS。
这样的性能超过了现有的具有大致相同数量参数的目标检测器(即YOLOv4-CSP, YOLOv5l)。
Method
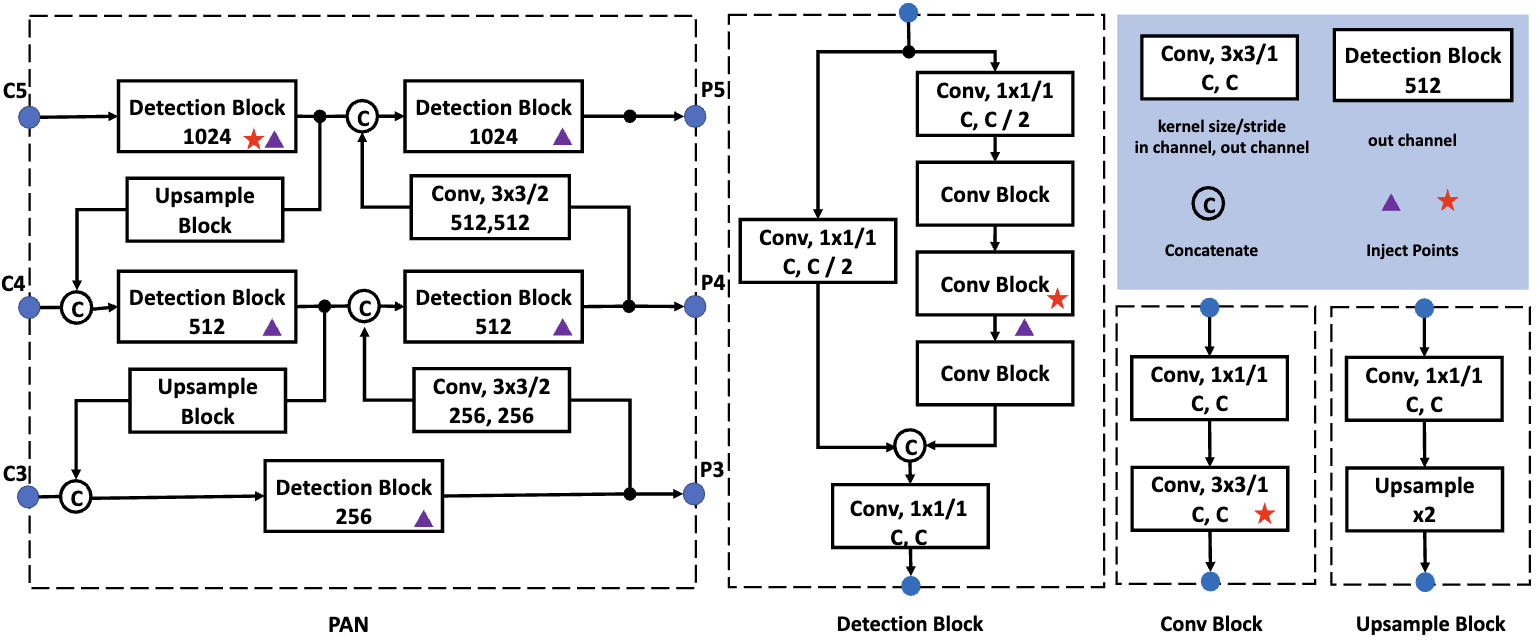
Path Aggregation Network. 不同尺度的目标检测是目标检测的一个基本问题。在实践中,作者开发了一个 detection neck,用于在所有尺度上构建高级语义特征映射。PP-YOLO中采用FPN组成自下而上的路径。最近, FPN变体已被提出以增强金字塔表示的能力。如:BiFPN[24]、PAN[14]、RFP[19]等。作者按照PAN的设计从上到下进行信息聚合。PAN的详细结构如图2所示。
Mish Activation Function. Mish激活函数[18]在YOLOv4和YOLOv5等检测器中被证明是有效的。它们在 backbone 中采用mish激活函数。然而,作者更喜欢使用预训练的参数,因为作者有一个强大的模型,在ImageNet上达到82.4%的top-1精度。为了保持 backbone 不变,作者在 detection neck 使用 mish 激活函数。
Larger Input Size. 增加输入尺寸会扩大目标的面积。因此,目标的小尺度信息将比以前更容易保留。但是,更大的输入占用更多的内存。要应用这个技巧,我们需要减小批处理大小。更具体地说,作者将批处理大小从每个GPU 24个图像减少到每个GPU 12个图像,并将最大输入大小从608扩展到768。输入大小均匀地从[320、352、384、416、448、480、512、544、576、608、640、672、704、736、768]中采样。
IoU Aware Branch. 在PP-YOLO中,IoU aware loss 是用 soft weight 形式计算的,这与初衷不符。 因此, 作者应用 soft label 形式。 下面是 IoU aware loss:
\(loss = -t * \log (\sigma(p)) - (1 - t) * \log(1 - \sigma(p)) \tag{1}\) 其中 $t$ 表示 anchor 和 它匹配的真实 bbox 之间的 IoU, $p$ 是 IoU aware 分支的原始输出, $\sigma(·)$ 表示 sigmoid 激活函数。注意,只有具有 IoU aware 的正样本才会计算损失。通过替换损失函数,IoU aware 分支比以前工作得更好。
Conclusion
这篇文章介绍了PP-YOLO的一些更新,它形成了一个高性能的目标检测器PP-YOLOv2。
PP-YOLOv2比其他著名的检测器,如YOLOv4和YOLOv5,在速度和精度之间取得了更好的平衡。
这篇文章作者探索了一堆技巧,并展示了如何在PP-YOLO检测器上结合这些技巧,并演示了它们的有效性。