Abstract
现有的深度卷积神经网络(CNNs)需要固定大小的输入图像(例如 $224 \times 224$ )。
这个需要是人工的并且可能会减少任意大小的图像的识别准确率。
在这项工作中,作者为网络配备了另一种池化策略——空间金字塔池化,以消除上述要求。
该网络结构叫做 SPP-net, 无论图像的大小多少, 其都能够生成固定长度的表征。
Pyramid pooling 对于物体形变也是有效的。
基于这些优势,SPP-net 应该在总体上改进所有基于 cnn 的图像分类方法。
在ImageNet 2012数据集上,作者证明了SPP-net提高了各种CNN架构的准确性,尽管它们的设计不同。
在Pascal VOC 2007和Caltech101数据集上,SPP-net使用单一的全图像表示,无需微调,就能获得最先进的分类结果。
SPP-net在目标检测方面的能力也很重要。使用SPP-net,只从整个图像计算一次特征图,然后在任意区域(子图像)中汇集特征来生成固定长度的表示,用于训练检测器。该方法避免了重复计算卷积特征。在处理测试图像中,该方法比 R-CNN 方法快 24-102x 倍,同时在Pascal VOC 2007上取得更好或相当的精度。
在2014年的ImageNet大尺度视觉识别挑战赛(ILSVRC)中,该方法在所有38个团队中在目标检测和图像分类方面排名第2和第3。
DEEP NETWORKS WITH SPATIAL PYRAMID POOLING
The Spatial Pyramid Pooling Layer
卷积层接受任意输入大小,但它们产生可变大小的输出。分类器(SVM/softmax)或全连接层需要固定长度的向量。此类向量可以通过将特征汇集在一起的词袋(BoW)方法[16]生成。空间金字塔池[14],[15]改进了BoW,因为它可以通过在局部空间中池化来保留空间信息。这与之前深度网络[3]的滑动窗口池形成鲜明对比,[3]滑动窗口的数量取决于输入大小。
为了采用任意大小的图像的深度网络,作者将最后一个池化层(例如,在最后一个卷积层之后的 pool5 )替换为空间金字塔池层。图3说明了该方法。在每个空间 bin 中,作者池化每个卷积核的响应(这篇文章使用最大池化)。空间金字塔池的输出是 $kM$ 维向量,bin 数量表示为 $M$(k是最后一个卷积层中的卷积核数量)。固定维向量是全连接层的输入。
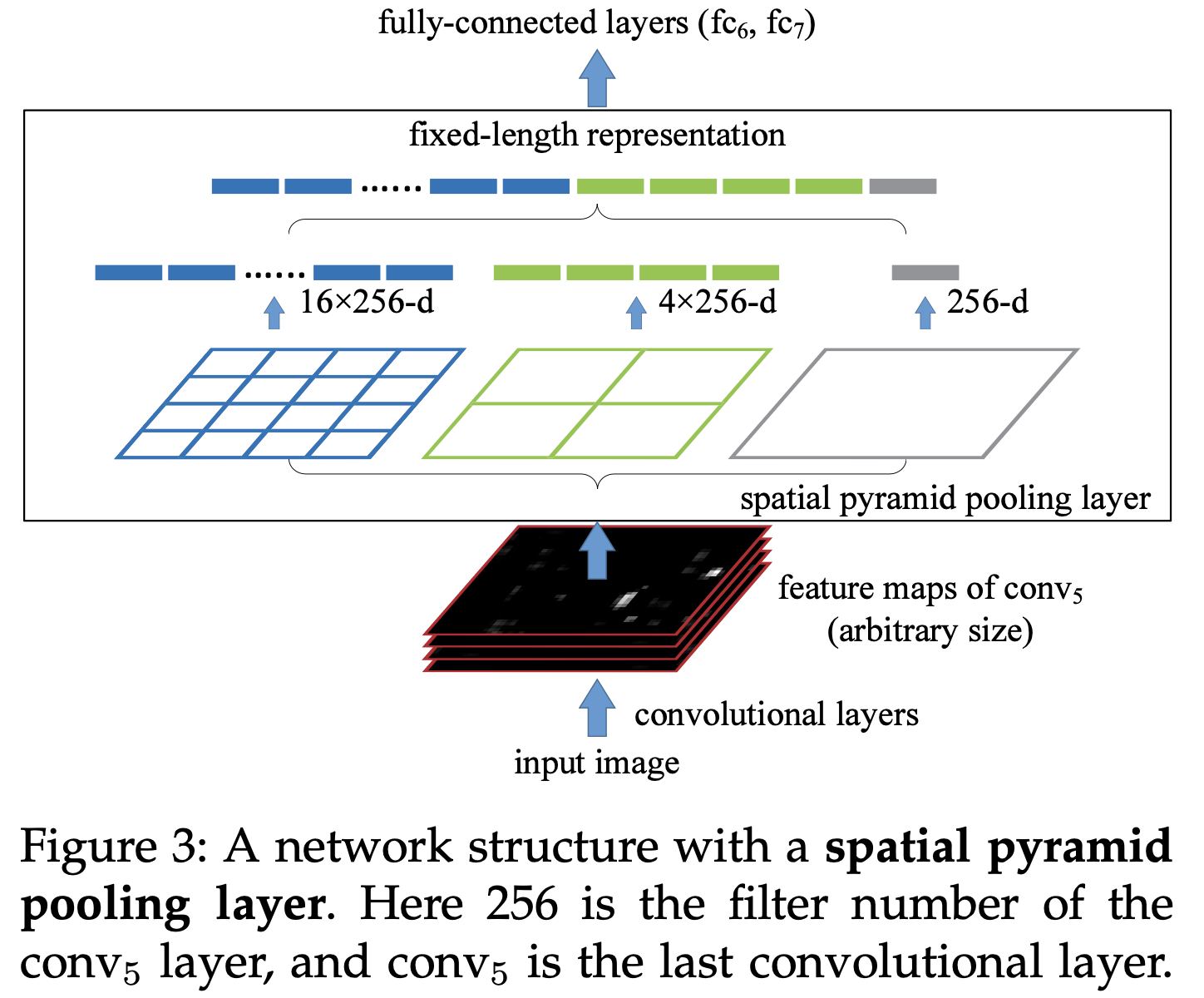
使用空间金字塔池,输入图像可以是任何大小。这不仅允许任意宽高比,还允许任意尺度。可以将输入图像的大小调整到任何比例(例如,$min(w,h)=180, 224, …$ ),并应用相同的深度网络。当输入图像处于不同尺度时,网络(具有相同的卷积核大小)将提取不同尺度的特征。尺度在传统方法中起着重要作用,例如,SIFT向量通常在多个尺度[29]、[27](由 patch 和高斯滤波器的大小决定)上提取。作者表明,尺度对深度网络的准确性也很重要。
有趣的是,最粗糙的金字塔级别只有一个覆盖整个图像的 bin。这实际上是一个“全局池化”操作,也在几个工作中进行了研究。
Conclusion
SPP是一种灵活的解决方案,可以处理不同的尺度、大小和纵横比。
这些问题在视觉识别中很重要,但在深度网络中却很少得到考虑。
作者提出了一种方法来训练一个具有 spatial pyramid pooling 层的深度网络。
SPP-net 在分类/检测任务上展现出强大的性能,同时大幅提升了 DNN-base 检测的速度。
-
Previous
【深度学习】YOLOX: Exceeding YOLO Series in 2021 -
Next
【深度学习】DeepLabV3+:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation