Abstract
实际应用对语义分割方法有很高的要求。
虽然语义分割随着深度学习取得了显著的飞跃,但实时方法的性能并不令人满意。
这篇文章提出了一种用于实时语义分割任务的轻量级模型PP-LiteSeg。
具体地说,作者提出了一种灵活的轻量级解码器(FLD),以减少以前解码器的计算开销。
为了加强特征表示,作者提出了一种统一注意融合模块(UAFM),该模块利用空间注意力和通道注意力产生一个权值,然后将输入的特征与权值融合。
此外,作者提出了一种简单金字塔池化模块(SPPM),以较低的计算成本聚合全局上下文。
广泛的评估表明,与其他方法相比,PP-LiteSeg实现了精度和速度之间的优越权衡。
Method
Flexible and Lightweight Decoder
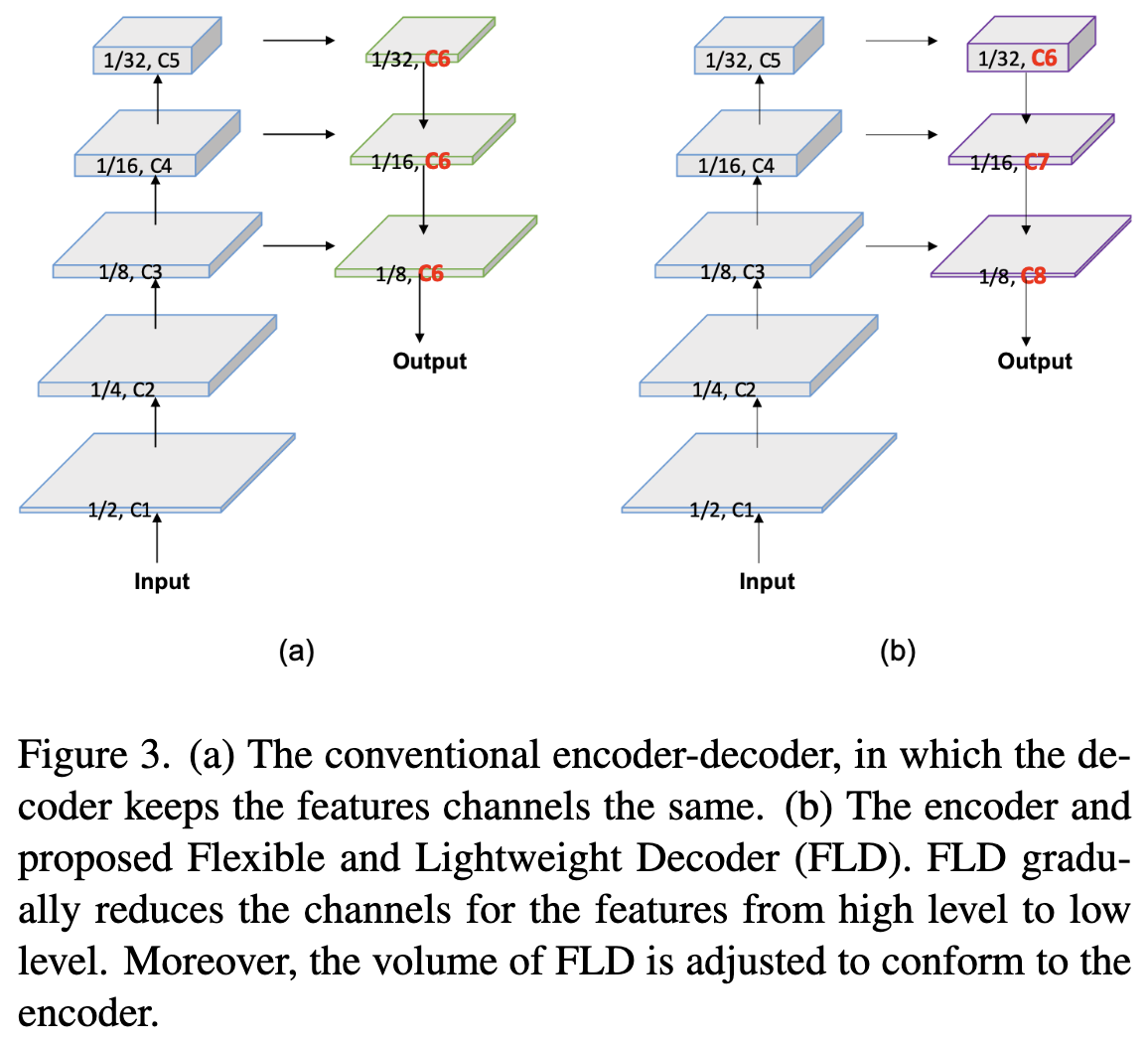
编码器-解码器结构已被证明是有效的语义分割。一般来说,编码器利用一系列的层分组成几个阶段来提取层次特征。从低层到高层特征,通道数量逐渐增加,特征空间大小逐渐减小。该设计平衡了各级的计算成本,保证了编码器的效率。解码器也有几个阶段,负责融合和上采样特征。尽管特征的空间大小从高阶到低阶不断增加,但在最近的轻量级模型中,解码器在所有级别中保持特征通道相同。因此,浅层阶段的计算成本远远大于深层阶段,导致了浅层阶段的计算冗余。为了提高解码器的效率,作者提出了一种 Flexible and Lightweight Decoder (FLD)。如图3所示, FLD 从 hight level 到 low level 逐渐减少特征的通道数。FLD可以很容易地调整计算成本,以实现编码器和解码器之间更好的平衡。虽然FLD中的特征通道减少了,但实验表明,PP-LiteSeg方法取得了与其他方法相媲美的精度。
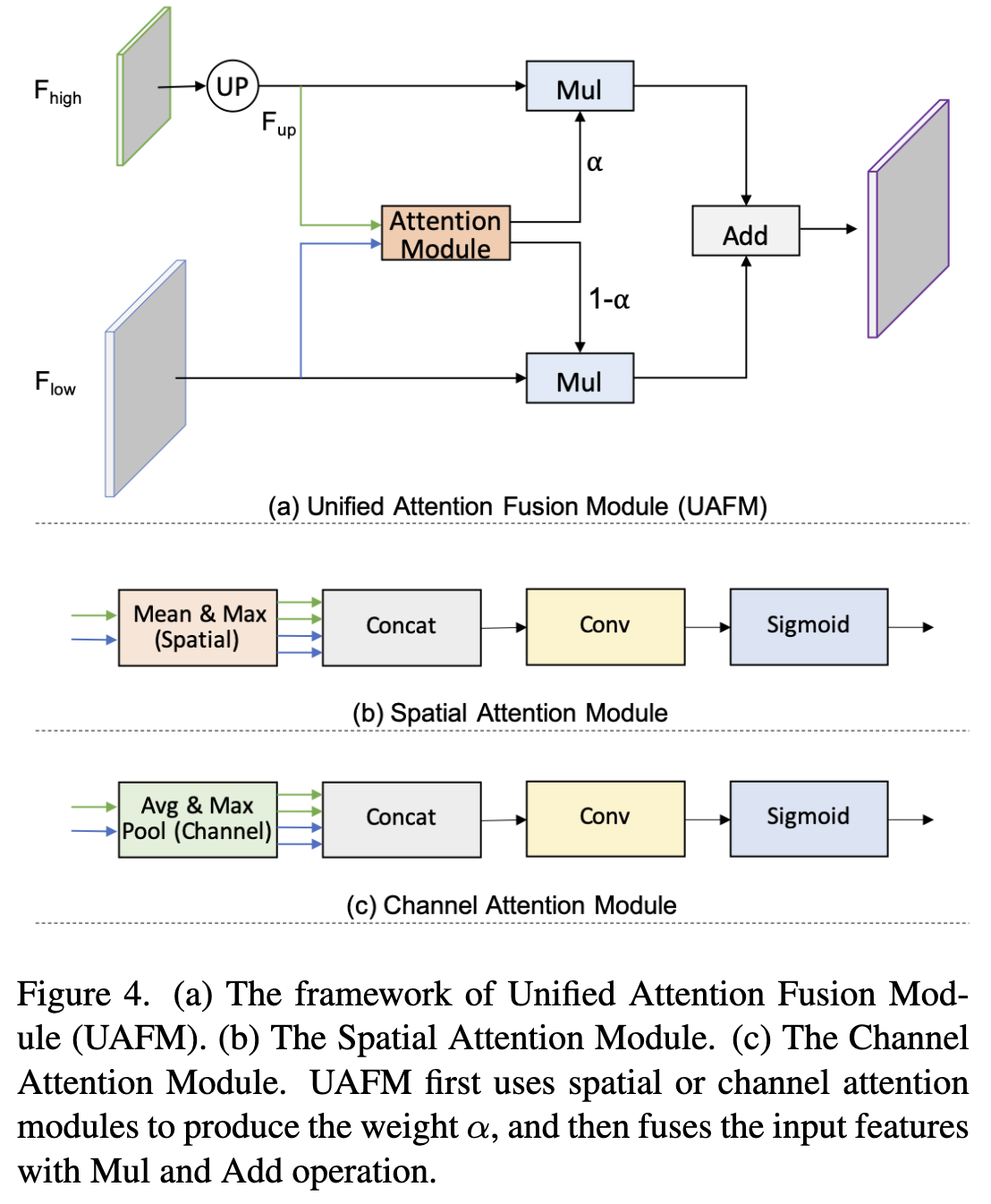
Unified Attention Fusion Module
如前所述,融合多层次特征是实现高分割精度的关键。除了 element-wise addition 和 concatenation 方法,研究者还提出了几种方法,如SFNet[15]、FaPN[11]和AttaNet[25]。在这项工作中,作者提出了一种Unified Attention Fusion Module(UAFM),应用通道和空间注意力来丰富融合的特征表示。
UAFM Framework. 如图4 (a)所示,UAFM利用注意力模块产生权重 $\alpha$,并将输入特征与 $\alpha$ 通过 Mul 和 Add 操作融合。细节上, 输入特征表示为 $F_{high}$ 和 $F_{low}$。$F_{high}$ 是更深模块的输出, $F_{low}$ 是编码器的 counterpart。注意,它们具有相同的通道。UAFM首先利用双线性插值运算将上采样 $F_{high}$ 上采样到和 $F_{low}$ 相同大小,上采样特征记为 $F_{up}$。 然后,注意力模块以 $F_{up}$ 和 $F_{low}$ 为输入,产生权重 $\alpha$。 注意,注意力模块可以是插件,比如空间注意力模块、通道注意力模块等。然后,作者分别对 $F_{up}$ 和 $F_{low}$ 应用 element-wise Mul 运算来获得注意力加权特征。最后,UAFM对注意力加权特征进行元素加法并输出融合后的特征。
Spatial Attention Module. 空间注意力模块的动机是利用空间间关系产生一个权重,它代表输入特征中每个像素的重要性。如 图4(b) 所示, 给定输入特征,例如 $F_{up} \in R^{C \times H \times W}$ 和 $F_{low} \in R^{C \times H \times W}$, 首先在通道上计算均值和方差生成四个特征, 其维度为 $R^{1 \times H \times W}$。 之后这四个特征拼成一个特征 $F_{cat} \in R^{4 \times H \times W}$。 对这个拼接的特征使用卷积和 sigmoid 得到输出 $\alpha \in R^{1 \times H \times W}$。 空间注意力模块的公式如等式 (2) 所示。 此外,空间注意模块可以是灵活的,例如去掉max操作以降低计算成本。
\(F_{cat} = Concat(Mean(F_{up}), Max(F_{up}), Mean(F_{low}), Max(F_{low})) \\ \alpha = Sigmoid(Conv(F_{cat})) \tag{2}\) Channel Attention Module. 通道注意力模块的关键概念是利用通道间的关系来生成一个权重,该权重表示每个通道在输入特征中的重要性。 如 图4 (b) 所示,提出的通道注意力模块利用平均池化和最大池化操作来压缩输入特征的空间维度。这个过程生成了四个具有维度为 $R^{C \times 1 \times 1}$ 的特征。 然后,它沿着通道轴将这四个特征连接起来,并进行卷积和 sigmoid 操作来产生一个权值 $\alpha \in R^{C \times 1 \times 1}$。 简而言之,通道注意力模块的过程可以表述为等式 3。
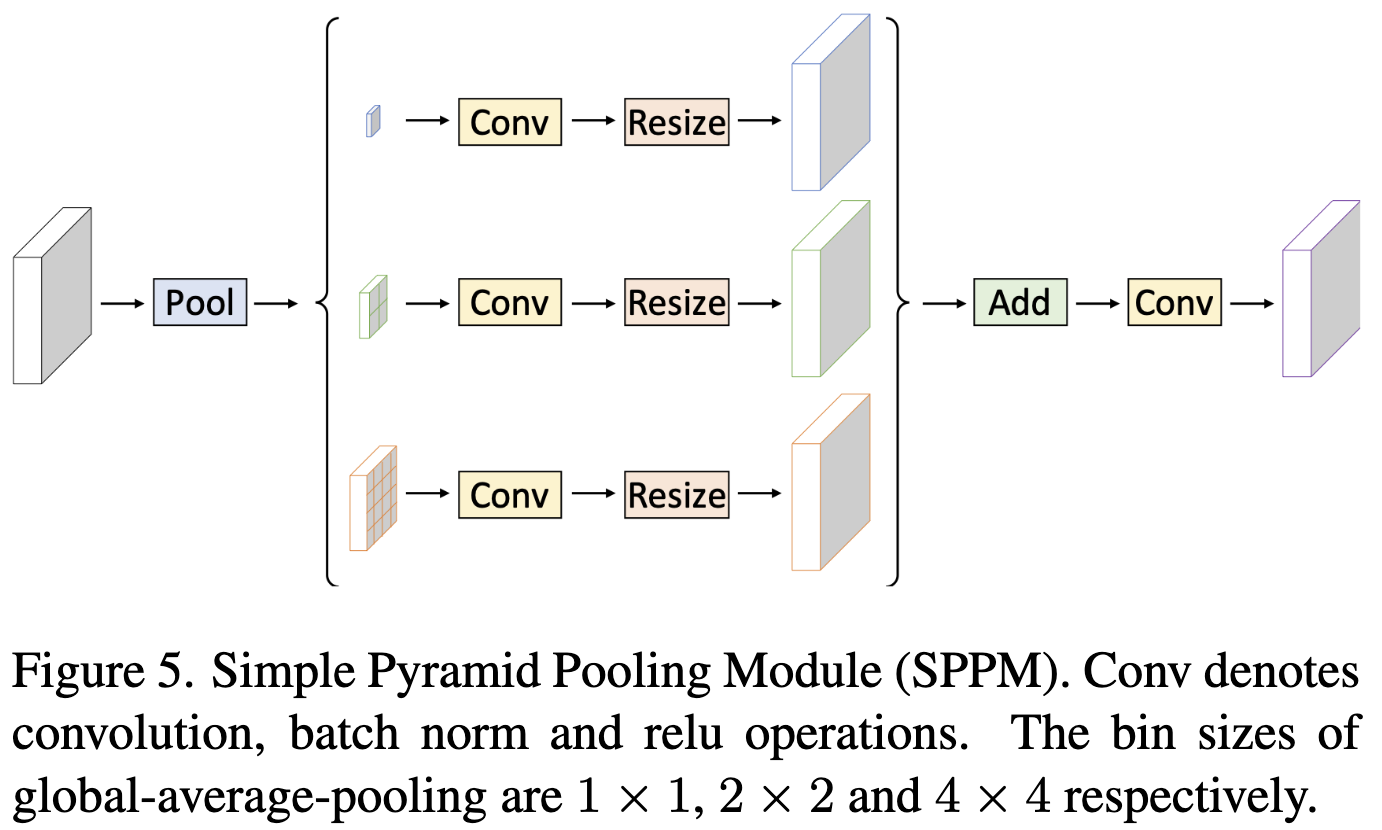
Simple Pyramid Pooling Module
如 图5 所示, 作者提出 Simple Pyramid Pooling Module(SPPM)。 其首先利用 pyramid pooling 模块融合输入特征。 pyramid pooling 模块有三个 全局平均池化操作 并且 bin size 分别是 $1 \times 1$, $2 \times 2$ 和 $4 \times 4$。然后对输出特征进行卷积和上采样操作。对于卷积运算,kernel 大小为 $1 \times 1$,输出通道小于输入通道。最后,将这些上采样特征加起来,并应用卷积运算产生 refine 特征。 与原始PPM相比,SPPM减少了中间和输出通道,消除了 short-cut,用加法操作取代了 concat 操作。因此,SPPM方法更有效,更适用于实时模型。
Network Architecture
所提出的 PP-LiteSeg 的架构如图2所示。PP-LiteSeg主要由三个模块组成: encoder, aggregation 和 decoder. 。
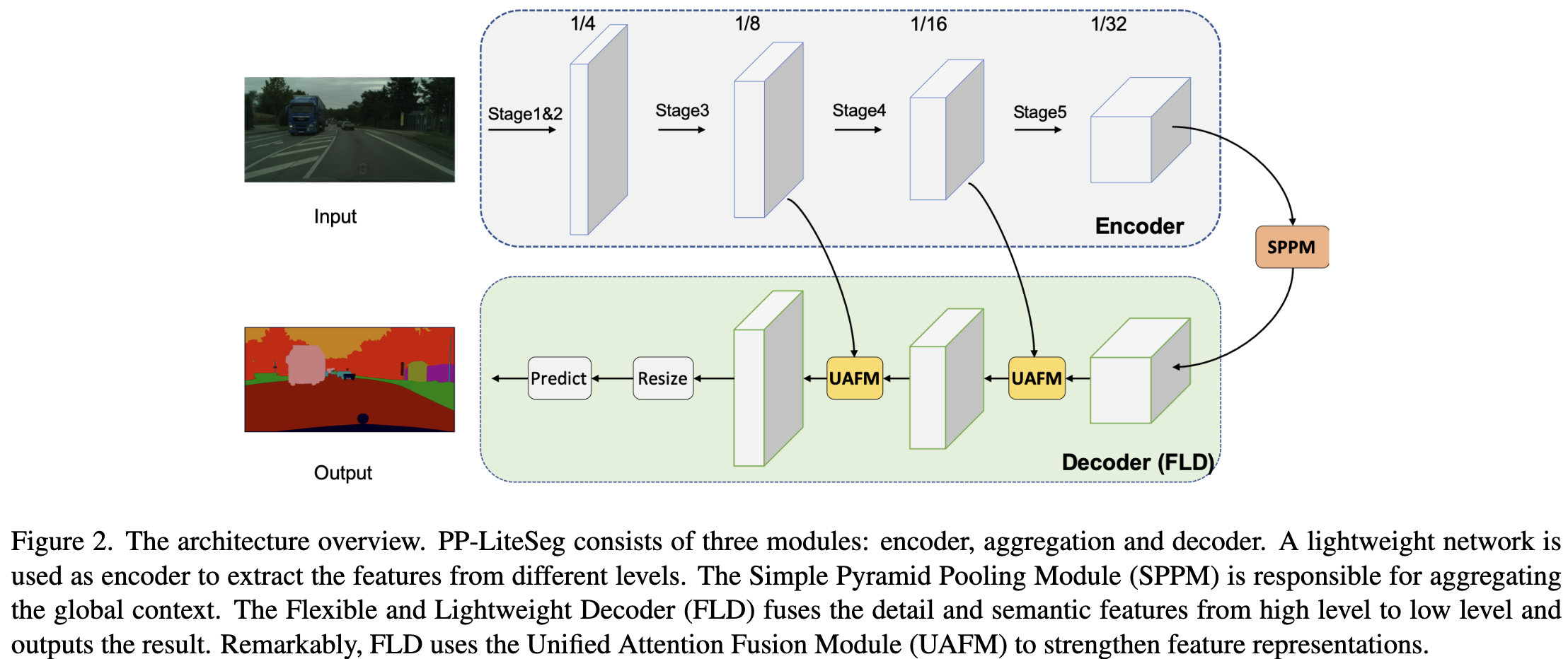 首先,给定一个输入图像,PP-Lite利用一个通用的轻量级网络作为编码器来提取层次特征。具体来说,作者选择STDCNet[8]。 STDCNet 有 5 个 stage, 每个 stage 的步长为 2,因此最终的特征大小为输入图像的 $1/32$。 如表1所示,作者提出了两个版本的PP-LiteSeg,分别是 PP-LiteSeg-T 和 PP-LiteSeg-B,编码器分别为STDC1和STDC2。 PP-LiteSeg-B具有更高的分割精度,而PP-LiteSeg-T的推理速度更快。值得注意的是,作者将SSLD[7]方法应用到编码器的训练中,得到了增强的预训练权值,这有利于分割训练的收敛。
首先,给定一个输入图像,PP-Lite利用一个通用的轻量级网络作为编码器来提取层次特征。具体来说,作者选择STDCNet[8]。 STDCNet 有 5 个 stage, 每个 stage 的步长为 2,因此最终的特征大小为输入图像的 $1/32$。 如表1所示,作者提出了两个版本的PP-LiteSeg,分别是 PP-LiteSeg-T 和 PP-LiteSeg-B,编码器分别为STDC1和STDC2。 PP-LiteSeg-B具有更高的分割精度,而PP-LiteSeg-T的推理速度更快。值得注意的是,作者将SSLD[7]方法应用到编码器的训练中,得到了增强的预训练权值,这有利于分割训练的收敛。
其次,PP-LiteSeg采用SPPM对远程依赖关系进行建模。SPPM以编码器的输出特征为输入,生成包含全局上下文信息的特征。
最后,PP-LiteSeg利用提出的FLD逐步融合多层次特征并输出结果图像。具体来说,FLD 由两个UAFM和一个 segmentation head 组成。为了提高效率,在UAFM中采用了空间力注意模块。每个UAFM都有两个特征作为输入,一个是由编码器各阶段提取的低级特征,一个是由SPPM或深度融合模块产生的高级特征。后面的 UAFM 输出融合下采样率为 $1/8$ 的特征。在 Segmentation head 中, 使用 Conv-BN-ReLU 操作减少 $1/8$ 下采样特征的通道数为类别的数量。 然后进行上采样操作将特征大小扩大到输入图像的大小,并通过argmax操作预测每个像素的标签。cross entropy loss 使用 Online Hard Example Mining 优化模型。
Conclusion
在本文中,作者重点设计了一种新的实时语义分割网络。
首先,作者提出了灵活轻量级解码器(FLD),以提高现有解码器的效率。
然后,作者提出了一种统一的注意力融合模块(UAFM),该模块能够有效地增强特征表示。
在此基础上,作者提出了一种简单金字塔池化模块(SPPM),用于全局上下文的聚合,计算成本低。
在此基础上,作者提出了一种实时语义分割网络PP-LiteSeg。
-
Previous
【深度学习】HarDNet: A Low Memory Traffic Network -
Next
【深度学习】Segmentation Transformer(OCRNet): Object-Contextual Representations for Semantic Segmentation