Abstract
这篇文章提出了一种将目标检测视为集合预测问题的新方法。
该方法简化了目标检测流程,有效地消除了对许多手工设计的组合的需求,如非极大值抑制过程或 Anchor 生成,这些过程或 Anchor 生成明确编码了对该任务的先验知识。
新框架的主要成分称为 DEtection TRansformer 或 DETR,是基于集合的全局损失,其通过二分匹配和Transformer码器解码器结构进行预测。
给定一组固定的学习目标 query,DETR对目标的关系和全局图像上下文进行推理,直接并行输出最终的预测集合。
与许多其他现代目标检测器不同,新模型在概念上很简单,不需要专门的库。
DETR在COCO目标检测数据集上展示了与高度优化的 Faster R-CNN 基线相当的准确性和运行时间性能。
此外,DETR可以很容易地泛化,以统一的方式产生全景分割。
The DETR model
Object detection set prediction loss
DETR 推断出一组固定大小的 $N$ 个预测,只需通过解码器,其中 $N$ 被设置为明显大于图像中的目标数量。训练的主要困难之一是根据真实目标(类别、位置、大小)进行评分。所提出的损失在预测和真实目标之间产生最佳的二分匹配,然后优化特定目标(边界框)损失。
用 $y$ 表示一组真实目标, $\hat y = {\hat y_i}_{i=1}^N$ 表示一组 $N$ 个预测。 假设 $N$ 在图像中比目标数量大, 将 $y$ 视作用 $\emptyset$ 填充的大小为 $N$ 的集合。为了找到这两个集合之间的二分匹配,我们以最低的成本搜索 $N$ 个元素 $\sigma \in \mathcal{G}_N$ 的排列 :
\[\hat \sigma = \mathop{argmin}_{\sigma \in \mathcal{G}_N} \sum_i^N L_{match} (y_i, \hat y_{\sigma(i)})\]其中 $L_{match}(y_i, \hat y_{\sigma(i)})$ 是真实标签和索引 $\sigma(i)$ 的一个预测的 pair-wise matching cost。 之前的工作使用匈牙利算法有效地计算了这个最优分配。
匹配成本既考虑了类别预测,也考虑了预测和真实边界框的相似性。真实集合的每个元素 $i$ 可以被视为 $y_i = (c_i, b_i)$, 其中 $c_i$ 是目标类别标签(可能是 $\emptyset$) , $b_i \in [0, 1]^4$ 是一个向量, 其定义了真实边界框相对比图像大小的中心坐标以及高和宽。对于索引 $\sigma(i)$ 的预测, 定义类别 $c_i$ 的概率为 $\hat p_{\sigma(i)}(c_i)$ 和预测的边界框为 $\hat b_{\sigma(i)}$。 定义 $L_{match}(y_i, \hat y_{\sigma(i)})$ 为 $-\mathbb{1}{c_i \neq \emptyset} \hat p{\sigma(i)}(c_i) + \mathbb{1}{c_i \neq \emptyset} L{box}(b_i, \hat b_{\sigma(i)})$。
这种查找匹配的过程与现代检测器中用于匹配提议或先验框与真实目标的启发式分配规则的作用相同。主要区别在于,DETR 需要找到一对一的匹配,用于没有重复的直接集合预测。
第二步是计算损失函数,即上一步匹配的所有对的匈牙利损失。作者定义的损失与普通目标检测器的损失相似,即用于类预测的负对数似然和稍后定义的边界框损失的线性组合:
\[L_{Hungarian}(y, \hat y) = \sum_{i=1}^N [-\log \hat p_{\hat \sigma}(c_i) + \mathbb{1}_{c_i \neq \emptyset} L_{box}(b_i, \hat b_{\sigma}(i))]\]其中 $\hat \sigma$ 是第一步计算的最优分配。为了类别平衡, 实际中, 对于 $c_i = \emptyset$ 的对数概率项将其权重缩小10倍。这类似于 Faster R-CNN 训练程序如何通过子采样来平衡正/负提议。注意, 目标和 $\emptyset$ 之间的匹配成本不依赖于预测, 这意味着成本为常数。在匹配成本中, 作者使用概率 $\hat p_{\hat \sigma(i)}(c_i)$, 而不是对数概率。这使得类别预测项和 $L_{box}(·, ·)$ 相当, 并且观察到了更好的实验表现。
Bounding box loss. 匹配成本和匈牙利损失的第二部分是 $L_{box}(·)$,它为边界框打分。与许多将边界框预测作为一些初始猜测进行的检测器不同,DETR直接进行边界框预测。虽然这种方法简化了实现,但它带来了损失相对尺度的问题。最常用的 $\ell_1$ 损失对小边界框和大边界框有不同的尺度,即使它们的相对误差相似。为了缓解这个问题, 作者使用 $\ell_1$ 损失和 GIoU 损失的线性组合。这两种损失由批量中的目标数量归一化。
DETR architecture
整体DETR架构出人意料地简单,如图2所示。它包含三个主要组件,在下面描述:用于提取紧凑特征表示的CNN主干,编码器-解码器 Transformer,以及进行最终检测预测的简单前向网络(FFN)。
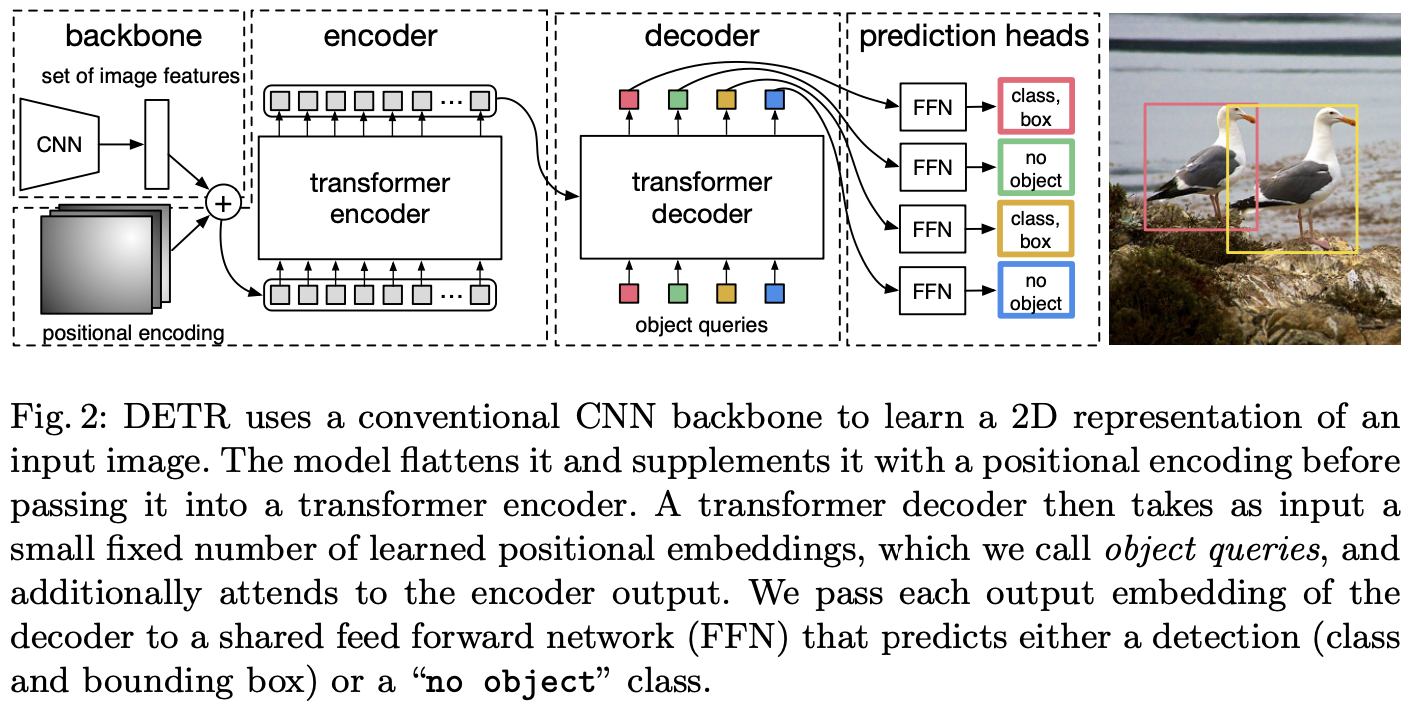 与许多现代检测器不同,DETR可以在任何深度学习框架中实现,该框架提供通用CNN主干和仅几百行的 Transformer 原型结构实现。DETR的推理代码可以在PyTorch中以不到50行实现。
与许多现代检测器不同,DETR可以在任何深度学习框架中实现,该框架提供通用CNN主干和仅几百行的 Transformer 原型结构实现。DETR的推理代码可以在PyTorch中以不到50行实现。
Backbone. 从初始图像 $x_{img} \in \mathbb{R}^{3 \times H_0 \times W_0}$, 一个传统的 CNN 主干生成一个低分辨率特征图 $f \in \mathbb{R}^{C \times H \times W}$。 通常值设置为 $C = 2048$, $H, W = \frac{H_0}{32}, \frac{W_0}{32}$。
Transformer encoder. 首先, 一个 $1 \times 1$ 卷积减少高层特征图 $f$ 的通道维度 $C$ 为一个更小的维度 $d$。 创建一个新的特征图 $z_0 \in \mathbb{R}^{d \times H \times W}$。 编码器期望一个序列作为输入,因此将 $z_0$ 的空间维度拉成一维, 得到一个 $d \times H W$ 的特征图。每个编码器有一个标准的结构并且有一个多头注意力模块(MSA)和前向网络(FFN) 组成。由于 Transformer 架构是 permutation-invariant 的,作者用固定位置编码[31,3]来修复它,这些编码添加到每个注意力层的输入中。
Transformer decoder. 解码器遵循 Transformer 的标准架构,使用多头自注意力和编码器和解码器注意力机制转换尺寸为 $d$ 的 $N$ 个嵌入。与原始 Transformer 的区别在于,该模型在每个解码器层并行解码 $N$ 个目标,而 Vaswani等人[47]使用自回归模型,一次预测一个元素的输出序列。由于解码器也是 permutation-invariant 的,N个输入嵌入必须不同才能产生不同的结果。这些放置嵌入是学习的位置编码,称之为 object queries,与编码器类似,将它们添加到每个注意力层的输入中。N个 object queries 由解码器转换为输出嵌入。然后,它们通过前向网络(在下一小节中描述)独立解码为框坐标和类标签,从而产生 $N$ 个最终预测。使用对这些嵌入的自编码器和解码器注意力,该模型使用它们之间的配对关系对所有目标进行全局推理,同时能够将整个图像用作上下文。
Prediction feed-forward networks (FFNs). 最终预测由具有ReLU激活函数和维度为 $d$ 的 $3$ 层感知器以及线性投影层计算得到。FFN预测边界框的归一化后的中心坐标、高度和宽度, 线性层使用 softmax 函数预测类别标签。因为作者预测固定大小的 $N$ 哥边界框, 其中 $N$ 通常大于图像中的目标数量, 一个额外的类别标签 $\emptyset$ 用于表示没有目标。 在标准目标检测方法中,该类的作用与“背景”类类似。
Auxiliary decoding losses. 在训练过程中,作者发现在解码器中使用辅助损失[1]是很有帮助的,特别是帮助模型输出每个类的目标的正确数量。作者在每个解码器层后添加预测 FFN 和匈牙利损失。所有预测FFN都共享其参数。作者使用额外的共享层规范化来规范化来自不同解码器层的预测FFN的输入。
Conclusion
这篇文章提出了DETR,这是一种基于 Transformer 和二分匹配损失的目标检测系统的新设计,用于直接集合预测。
该方法在 COCO数据集上实现了与优化的 Faster R-CNN 基线相当的结果。
DETR实现简单,具有灵活的架构,易于扩展为全景分割,并具有竞争性的结果。
此外,它在大型物体上的性能明显优于 Faster R-CNN,这可能要归功于对自注意力形成的全局信息的处理。
这种新的检测器设计也带来了新的挑战,特别是在训练、优化和小物体性能方面。
-
Previous
【深度学习】Spatial as Deep(SCNN): Spatial CNN for Traffic Scene Understanding -
Next
【深度学习】Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer