Abstract
我们提出了一种全卷积的单阶段目标检测器(FCOS),以逐像素预测方式解决目标检测问题,类似于语义分割。
几乎所有最先进的目标检测器,如RetinaNet、SSD、YOLOv3 和 Faster R-CNN,都依赖于预定义的先验框。
相比之下,作者提出的检测器 FCOS 是无先验框的,也是无提议区域的。
通过消除预先定义的先验框,FCOS完全避免了与先验框相关的复杂计算,例如在训练期间计算重叠。
更重要的是,我们还避免了与先验框相关的所有超参数,先验框通常对最终检测表现非常敏感。
凭借唯一的后处理非极大值抑制(NMS),使用 ResNeXt-64x4d-101 的FCOS在单模型和单尺度测试中实现了44.7%的AP,超过了之前的单阶段探测器,其优点是简单得多。
作者首次演示了一个更简单、更灵活的检测框架,提高了检测精度。
作者希望提出的 FCOS 框架可以作为许多其他实例级任务的简单而强大的替代品。
Approach
在这篇文章中,作者首先以每像素预测的方式重新制定目标检测。接下来,作者展示了如何利用多级预测来改进召回并解决重叠边界框导致的模糊。最后,作者提出了 “centerness” 分支,它有助于抑制低质量检测到的边界框,并大大提高整体性能。
Fully Convolutional One-Stage Object Detector
令 $F_i \in \mathbb{R}^{H \times W \times C}$ 表示一个主干 CNN 第 $i$ 层的特征图, $s$ 为直到该层的总步长。对于输入图像的真实边界框定义为 ${B_i}$, 其中 $B_i = (x_0^{(i)}, y_0^{(i)}, x_1^{(i)}, y_1^{(i)}, c^{(i)}) \in \mathbb{R}^4 \times {1, 2, …, C}$。 这里 $(x_0^{(i)}, y_0^{(i)})$ 和 $(x_1^{(i)}, y_1^{(i)})$ 表示边界框的左上角和右下角的坐标。$c^{(i)}$ 是边界框所属的类别。$C$ 是总类别数, 在 MS-COCO 数据集中是 80 类。
对于在特征图 $F_i$ 上每个 $(x, y)$ 位置, 我们可以将其映射回输入图像 $(\lfloor \frac{s}{2} \rfloor + xs, \lfloor \frac{s}{2} \rfloor + ys )$, 其离位置 $(x, y)$ 的感受野中心近。 与基于先验框的检测器不同,基于先验框的检测器将输入图像上的位置作为(多个)先验框的中心,并以这些先验框作为参考回归目标边界框,我们直接在该位置回归目标边界框。换句话说,作者的检测器直接将位置视为训练样本,而不是基于先验框的检测器中的先验框,这与用于语义分割的FCN相同。
特别地, 位置 $(x, y)$ 如果落在真实边界框并且类别标签 $c^$ 是真是边界框的类别标签, 那么其被考虑为正样本。否则的话, 它是负样本。除了用于分类的标签, 还有一个 4D 的真实向量 $t^ = (l^, t^, r^, b^)$ 作为定位的回归目标。这里 $l^, t^, r^, b^$ 是定位点到边界框的四个边的距离, 如图1左所示。如果一个位置落入多个边界框中,则被视为模糊的样本。只需选择最小面积的边界框作为其回归目标。在下一节中,作者表明,通过多级预测,模糊样本的数量可以显著减少,因此它们几乎不会影响检测性能。形式上,如果位置$(x,y)$ 与边界框 $B_i$ 相关联,则该位置的训练回归目标可以表述为:
\[l^* = x - x_0^{(i)}, \quad t^* = y - y_0^{(i)} \\ r^* = x_1^{(i)} - x, \quad b^* = y_1^{(i)} - y \tag{1}\] 值得注意的是,FCOS可以利用尽可能多的真实样本来训练回归器。它与基于先验框的检测器不同,先验框检测器仅将和真实边界框有足够高的交并比的先验框视为正样本。作者认为,这可能是FCOS表现优于其基于先验框的方法的原因之一。
值得注意的是,FCOS可以利用尽可能多的真实样本来训练回归器。它与基于先验框的检测器不同,先验框检测器仅将和真实边界框有足够高的交并比的先验框视为正样本。作者认为,这可能是FCOS表现优于其基于先验框的方法的原因之一。
Network Outputs. 对应于训练目标,网络的最后一层预测一个80维的类别向量 $p$ 和一个 4D 向量 $t = (l, t, r, b)$ 边界框坐标。相比于训练一个多类别的分类器, 作者训练 $C$ 个二分类器。作者在骨干网络的特征映射后分别添加了四个卷积层,用于分类分支和回归分支。此外,由于回归目标总是正的,作者在回归分支使用 $exp(x)$ 将任意实数映射到 $(0, \infty)$。值得注意的是,与每个位置有9个先验框的基于先验框的检测器相比,FCOS的网络输出变量少 9 倍。
Loss Function. 作者定义训练损失函数为:
\[L({p_{x, y}}, {t_{x, y}}) = \frac{1}{N_{pos}} \sum_{x, y} L_{cls} (p_{x, y}, c^*_{x, y}) \\ + \frac{\lambda}{N_{pos}} \sum_{x, y} \mathbb{1}_{c^*_{x, y} > 0} L_{reg}(t_{x, y}, t^*_{x, y}) \tag{2}\]其中 $L_{cls}$ 是 focal loss, $L_{reg}$ 是 UnitBox 中的 IoU loss。 $N_{pos}$ 表示正样本的数量, $\lambda$ 为 1 为 $L_{reg}$ 平衡权重。总和是在特征图上的所有位置上计算的 $F_i · \mathbb{1}_{c^_i > 0}$ 是指示函数, 如果 $c_i^ > 0$ 为 1 否则为0。
Inference. FCOS的推理很简单。给定输入图像,通过网络前向它,并获得特征图 $F_i$ 上每个位置的分类分数 $p_{x,y}$ 和回归预测 $t_{x,y}$ 。和RetinaNet一样,作者选择 $p_{x,y} > 0.05$ 的位置作为正样本,并反推等式(1)以获得预测的边界框。
Multi-level Prediction with FPN for FCOS
在这里,作者展示了如何通过 FPN 的多级预测来解决所提的FCOS的两个可能问题。1)CNN中最终特征图的大步长(例如16×)可能导致相对较低的最大可能召回(BPR)。对于基于先验框的检测器,由于大步长而导致的低召回率可以通过降低正先验框所需的 IoU 分数来补偿。对于FCOS,乍一看,人们可能会认为BPR可能比基于先验框的检测器低得多,因为由于大步长,无法召回最终特征图上没有编码的物体。在这里,作者从实验中表明,即使大步长,基于FCN的FCOS仍然能够产生良好的BPR,在 Detectron 官方实现中,它甚至可以比基于先验框的检测器 RetinaNet 的BPR更好(参见表1)。因此,BPR实际上不是FCOS的问题。此外,通过多级FPN预测,BPR可以进一步改进,以匹配基于先验框的 RetinaNet 可以实现的最佳BPR。2)真实边界框的重叠会导致不可避免的模糊问题,例如在重叠回归中哪个边界框应该被定位?这种模糊性导致基于 FCN 的检测器性能下降。在这项工作中,作者表明,模糊性可以通过多级预测大大解决,与基于先验框的检测器相比,基于FCN的检测器可以获得同等的性能,有时甚至更好。

根据FPN[14],作者在不同层级的特征图上检测到不同大小的目标。具体来说,作者使用五级特征图,定义为 ${P_3, P_4, P_5, P_6, P_7}$。 $P_3, P_4$ 和 $P_5$ 由主干 CNN 的特征图 $C_3, C_4, C_5$ 后接一个带有自顶向下的连接的 $1 \times 1$卷积层得到, 如图2所示。$P_6$和 $P_7$ 通过在 $P_5$ 和 $P_6$ 上分别使用步长为2的一个卷积层得到。最终,特征层级 $P_3, P_4, P_5, P_6, P_7$ 步长分别为 $8, 16, 32, 64, 128$。
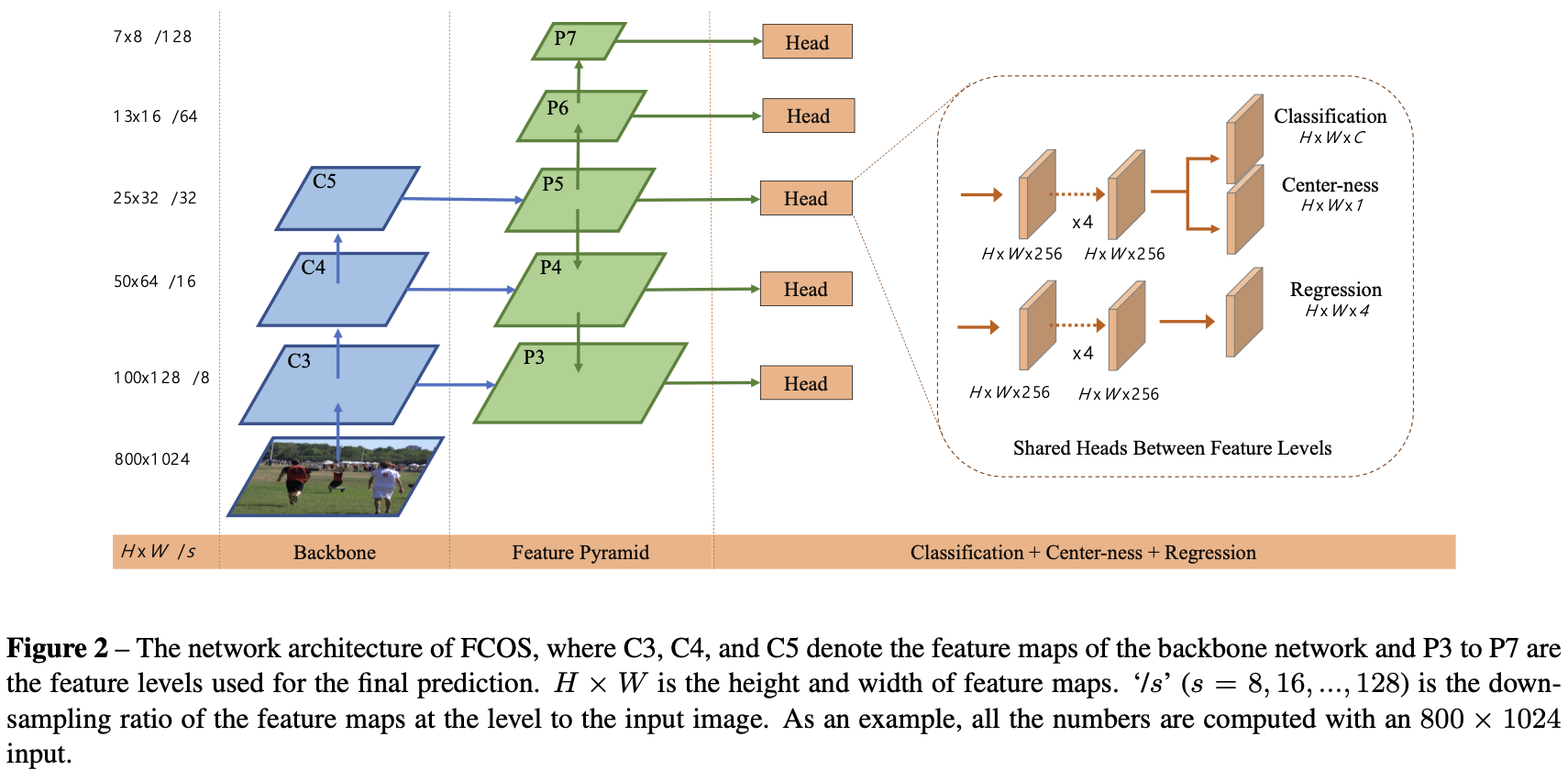
与基于先验框的检测器不同,基于先验框的检测器将不同尺寸的先验框分配给不同的特征层级,作者直接限制了每个层级的边界框回归范围。更具体地, 首先在所有特征层级上为为每个位置计算回归目标 $l^, t^, r^, b^$。 然后, 如果一个位置满足 $\max(l^, t^, r^, b^) > m_i$ 或者 $\max(l^, t^, r^, b^) < m_{i-1}$, 它被设置为负样本,因此不再需要回归边界框。这里 $m_i$ 是特征称呼 $i$ 需要回归的最大距离。 在这篇文章中, $m_2, m_3, m_4, m_5, m_6, m_7$ 分别设置为 $0, 64, 128, 256, 512, \infty$。 由于不同大小的目标被分配到不同的特征层级,大多数重叠发生在不同大小的目标之间。如果一个位置,即使使用多级预测,仍然分配给多个真实框,只需选择面积最小的真实框作为目标。正如实验所示,多级预测可以在很大程度上缓解上述歧义,并将基于FCN的检测器提高到相同水平的基于先验框的检测器。
最后,在 RetinaNet 一样,在不同的特征层级之间共享 head,这不仅使检测器参数高效,而且提高了检测效果。然而,作者观察到,需要不同的特征层级才能回归不同的尺寸范围(例如,P3的大小范围为[0,64],P4的大小范围为[64,128]),因此对不同的特征层级使用相同的 head 是不合理的。因此,作者没有使用标准的 $exp(x)$,而是使用带有可训练标量 $s_i$ 的 $exp(s_i x)$来自动调整特征层级 $P_i$ 的指数函数基数,这略微提高了检测性能。
Center-ness for FCOS
在FCOS中使用多级预测后,FCOS和基于先验框的检测器之间仍然存在性能差距。作者观察到,这是由于许多由远离物体中心的地方产生的低质量的预测边界框。
作者提出了一个简单而有效的策略来抑制这些低质量检测到的边界框,而无需引入任何超参数。具体来说,作者添加了一个单层分支,与分类分支并行(如图2所示),以预测位置的 “center-ness” 。 center-ness 描述了从位置到目标中心的归一化距离,如图3所示。给定一个位置的回归目标 $l^,t^, r^, b^$, center-ness 目标被定义为:
\(\text{centerness}^* = \sqrt{\frac{\min(l^*, r^*)}{\max(l^*, r^*)} \times \frac{\min(t^*, b^*)}{\max(t^*, b^*)}} \tag{3}\)*
 作者使用 sqrt 来减慢 cneter-ness 的衰减。center-ness 从 0 到 1 不等,因此训练有二分类交叉熵(BCE)损失。损失被添加到等式 (2) 中的损失中。在测试时,最终分数(用于对检测到的边界框进行排名)是通过将预测的 center-ness 乘以相应的分类分数来计算的。因此,center-ness 可以降低远离物体中心的边界框的分数。因此,这些低质量的边界框可能会被最终的非最大抑制(NMS)过程过滤掉,从而显著提高检测性能。
作者使用 sqrt 来减慢 cneter-ness 的衰减。center-ness 从 0 到 1 不等,因此训练有二分类交叉熵(BCE)损失。损失被添加到等式 (2) 中的损失中。在测试时,最终分数(用于对检测到的边界框进行排名)是通过将预测的 center-ness 乘以相应的分类分数来计算的。因此,center-ness 可以降低远离物体中心的边界框的分数。因此,这些低质量的边界框可能会被最终的非最大抑制(NMS)过程过滤掉,从而显著提高检测性能。
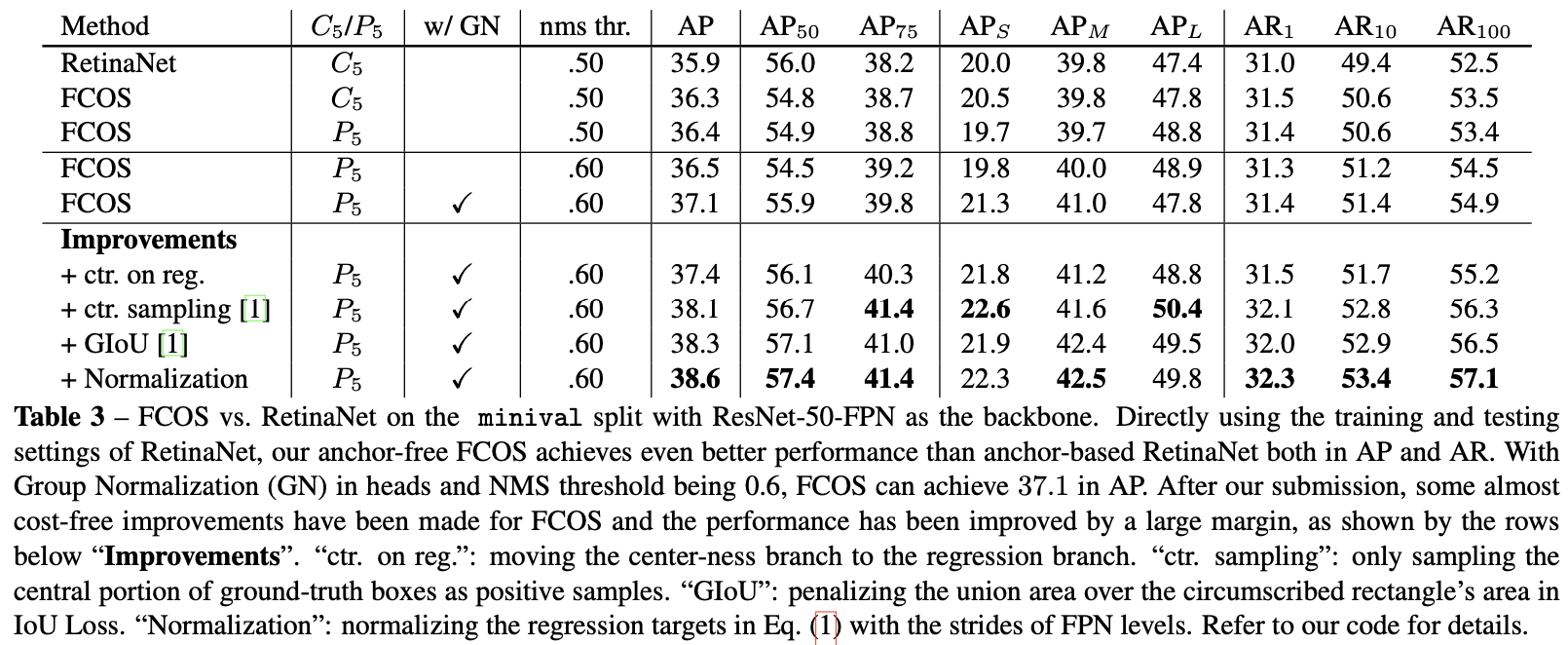
center-ness 的另一种选择是仅使用真实边界框的中心部分作为正样本,价格为一个额外的超参数,如工作[12, 33]所示。在提交后,[1]表明这两种方法的组合可以实现更好的性能。实验结果见表3。
Conclusion
作者提出了一种无先验框和无提议的单阶段检测器FCOS。
如实验所示,与流行的基于先验框的单阶段检测器(包括 RetinaNet、YOLO和SSD)相比,FCOS表现良好,但设计复杂性要小得多。
FCOS完全避免了与先验框框相关的所有计算和超参数,并以逐像素的预测方式解决目标检测,类似于语义分割等其他密集预测任务。
FCOS还在单阶段检测器中实现了最先进的性能。
作者还表明,FCOS可以在两阶段检测器 Faster R-CNN 中用作RPN,并表现大幅优于其RPN。
鉴于其有效性和效率,作者希望 FCOS 可以成为基于先验框的主流检测器的强大而简单的替代品。
Reference
- https://github.com/yqyao/FCOS_PLUS,2019.
- Lichao Huang, Yi Yang, Yafeng Deng, and Yinan Yu. Densebox: Unifying landmark localization with end to end object detection. arXiv preprint arXiv:1509.04874, 2015.
- Xinyu Zhou, Cong Yao, He Wen, Yuzhi Wang, Shuchang Zhou, Weiran He, and Jiajun Liang. EAST: an efficient and accurate scene text detector. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., pages 5551–5560, 2017.
-
Previous
【深度学习】USRNet:Deep Unfolding Network for Image Super-Resolution -
Next
【深度学习】ViTDet:Exploring Plain Vision Transformer Backbones for Object Detection