Abstract
迄今为止,精度最高的目标检测器基于 R-CNN 推广的两阶段方法,其中分类器应用于一组稀疏的候选目标定位。
相比之下, 密集采样的单阶段探测器有可能更快、更简单,但到目前为止,已经落后于两阶段检测器的准确性。
这篇文章调查了为什么会这样。
作者发现,在训练密集检测器时遇到的前景-背景类不平衡是核心原因。
作者提出通过重塑标准交叉熵损失,降低分配给分类良好的样本的损失的权重,来解决这种类不平衡。
作者提出的 focal loss 将训练重点放在一组稀疏的困难样本上,并防止大量容易的样本在训练期间压倒检测器。
为了评估损失的有效性,作者设计并训练了一种称为 RetinaNet 的简单密集检测器。
该结果表明,当对 focal loss 进行训练时,RetinaNet能够匹配之前单阶段检测器的速度,同时超过所有现有最先进的两阶段检测器的准确性。
RetinaNet Detector
Classification Subnet: 分类子网络在每个空间位置为A个先验框预测目标出现的概率和 $K$ 个目标类别。该子网络是连接到每个FPN 层级的小型 FCN;该子网络的参数在所有金字塔层级共享。它的设计很简单。从给定金字塔层级获取带有 $C$ 个通道的输入特征图,子网络应用了四个 $3 \times 3$ 卷积层,每个层都有 $C$ 卷积核,每个层后跟 ReLU 激活,然后是带有 $K A$ 个卷积核的 $3 \times 3$ 卷积层。最后,每个空间位置使用 sigmoid 激活, 输出 $KA$ 二分类预测, 如图3c所示。在实验中使用 $C = 256$ 和 $A = 9$。
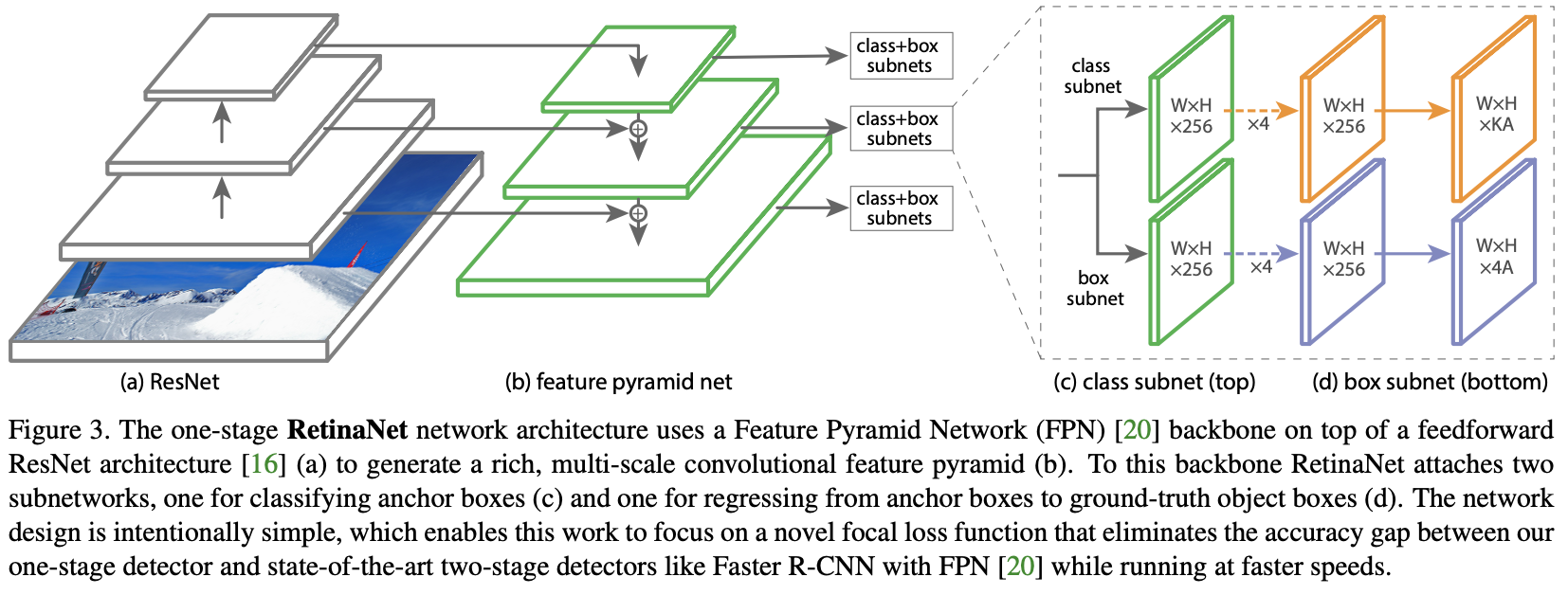 与 RPN [28] 相比,作者的目标分类子网络更深,仅使用 $3 \times 3$ convs,并且不与 box 回归子网络共享参数(接下来描述)。作者发现这些更高级别的设计决策比超参数的特定值更重要。
与 RPN [28] 相比,作者的目标分类子网络更深,仅使用 $3 \times 3$ convs,并且不与 box 回归子网络共享参数(接下来描述)。作者发现这些更高级别的设计决策比超参数的特定值更重要。
Box Regression Subnet: 与目标分类子网络平行,作者在每个金字塔层级附加另一个小FCN,以便将每个先验框的偏移量回归到附近的真实边界框(如果有的话)。边界框回归子网络的设计与分类子网路相同,只是它在空间位置的输出 $4A$ 个值,见图3d。对于每个空间位置的 $A$ 个先验框,这 4 个输出预测了先验框和真实框之间的相对偏移量。作者注意到,使用与类别无关的边界框回归器,该回归器使用较少的参数量,作者发现它同样有效。目标分类子网络和边界框回归子网络虽然共享结构,但使用独立的参数。
Conclusion
在这项工作中,作者将类别不平衡确定为阻止单阶段目标检测器超越性能最佳的两阶段方法的主要障碍。
为了解决这个问题,作者提出了 focal loss,该损失将加权项应用于交叉熵损失,以便将学习重点放在困难负样本上。
该方法简单且非常有效。
作者通过设计一个全卷积的单阶段检测器来证明其有效性,并报告扩展实验分析表明它实现了最先进的准确性和速度。