Abstract
由于缺乏全局视角和远程感知能力受到限制,自动驾驶面临巨大的安全挑战。
人们普遍认为,实现 L5 级自动驾驶需要车辆-基础设施合作。
然而,仍然没有来自真实场景的数据集可供计算机视觉研究人员研究与车辆-基础设施合作相关的问题。
为了加快车辆-基础设施合作自动驾驶(VICAD)的计算机视觉研究和创新,作者发布了 DAIR-V2X 数据集,这是VICAD真实场景中第一个大规模、多模态、多视图的数据集。
DAIR-V2X 由 71254 帧 LiDAR 数据和71254帧相机数据组成,所有帧都从真实场景中3D标注的。
作者介绍了车辆-基础设施合作3D目标检测问题(VIC3D),提出了使用车辆和基础设施的传感器输入协作定位和识别3D目标的问题。
除了解决传统的3D目标检测问题外,VIC3D的解决方案还需要考虑车辆和基础设施传感器之间的时间异步问题以及它们之间的数据传输成本。
此外,作者提出 Time Compensation Late Fusion(TCLF),这是VIC3D任务的后期融合框架,作为基于DAIR-V2X 的基准。
Task & Metrics
由于缺乏全局视角和远程感知能力受到限制,自动驾驶面临巨大的安全挑战。
由于3D目标检测是自动驾驶的关键感知任务之一,这篇文章专注于车辆-基础设施合作(VIC)3D目标检测任务,车辆接收和集成来自基础设施的信息,以定位和识别周围的物体。
与传统的多传感器3D目标检测任务相比,VIC3D目标检测具有以下替代特征:
- 传输成本。受物理通信条件的限制,从基础设施传输的数据应该减少,以减少带宽消耗、所有时间延迟,并满足实时要求。因此,VIC3D目标检测的解决方案需要平衡性能和传输成本之间的权衡。
- 时间异步。由于传输成本造成的异步触发和时间延迟,来自车辆传感器和基础设施传感器的数据时间戳是不同的,以产生时间空间误差。因此,在求解VIC3D时,应考虑时间同步化。
为了更好地制定 VIC3D 目标检测任务,作者将详细定义 VIC3D 目标检测,然后在本节中提供两个指标来测量检测性能和传输成本。
VIC3D Object Detection
VIC3D 目标检测可以表述为有效集成基础设施和车辆信息以定位和识别3D目标的优化问题,同时考虑到传输成本。在这里,作者讨论了VIC3D的输入和输出应该是什么。
Input. VIC3D的输入由来自车辆和基础设施的数据组成。
- 车端帧 $I_v(t_v)$: 捕获在时间 $t_v$ 以及它的相对位姿 $M_v(t_v)$, 其中 $I_v(·)$ 表示车端传感器的捕获函数。
- 设施段 $I_i(t_i)$: 捕获在时间 $t_i$ 以及它的相对位姿 $M_v(t_i)$, 其中 $I_i(·)$ 表示设施传感器的捕获函数。
注意 $t_i$ 应该早于 $t_v$ , 因为存在来自从基础设施到车辆的数据传输导致的时间延迟。考虑到物体在很小的时间间隔内移动非常小,以至于可以忽略空间偏移,将 $\mid t_v - t_i \mid \leq 10ms$ 视为同步(即 $t_v \approx t_i$)。此外, 允许使用更多之前的设施帧 $I_i(t_i)$ 解 VIC3D 以充分利用设施计算资源。
Ground Truth. VIC3D 目标检测的输出包含3D信息,如车辆周围物体的位置、类别和朝向。
VIC3D的相应真值是基础设施和车辆真值的融合结果,可以表述为:
\(GT = GT_v \cup GT_i\) 其中 $GT_v$ 是车辆传感器感知的真值, $GT_i$ 是基础设施传感器感知的真值。
VIC3D主要用于改善自动驾驶车辆的感知性能。 我们更关心在时间 $t_v$ 而不是时间 $t_i$ 的目标的3D信息。因此, $GT_v$ 和 $GT_i$ 应该都基于时间 $t_v$。 然而,从基础设施中捕获并从车辆捕获的输入帧的时间戳可能有所不同 $t_v \neq t_i$。 这不仅给在模型预测中融合结构内信息带来了挑战,而且在生成真值方面也造成了巨大的问题。这是因为在时间 $t_i$ 用基础设施帧标注的目标可能会在时间 $t_v$ 上移动到不同的位置,我们无法在时间 $t_v$ 上直截让基础设施帧进行标注。
为了应对这些困难,作者讨论了如何基于 DAIR-V2X 生成 VIC3D 的真值。
- 同步情况(例如 $t_v \approx t_i$)。 在这种情况下, 一个目标在车辆帧 $I_v(t_v)$ 应该与基础设施帧 $I_i(t_i)$ 出现在相同的空间位置。因此, 作者直接通过3.2节描述的半自动标注工具得到 车辆-设备联合 3D 标注
- 异步情况(例如 $t_v \neq t_i$)。 如果我们找到基础设施帧 $I_i(t_i’)$ 满足 $\mid t_v - t_i’ \mid \leq 10ms$, 我们能够使用 $I_i(t_i’)$生成真值。如果没有, 我们将估计在时间 $t_v$ 目标的 3D 状态来生成真值。在作者未来的工作中提供跟踪ID后,这项工作可以基于跟踪ID和运动学方程进行。
Benchmark
在本节中,作者在 DAIR-V2X 数据集上提供 VIC3D 目标检测基准和单视图(SV)3D目标检测基准,分析其特征,并提出未来研究的途径。
Benchmark for VIC3D object detection
作者为从 DAIR-V2X-C 提取的 VIC-Sync 数据集的 VIC3D 目标检测提供了一个基准,如第3.2节所示。
该数据集由 9311 对基础设施和车辆及其联合标注的组成。
此外,作者在基准中考虑了基础设施帧和车辆帧之间的时间异步性,这主要是由采样速率和传输延迟的差异造成的。
为了模拟时间异步现象,我们将 VIC-Sync 数据集中的每个基础设施帧替换为基础设施框架,该帧是原设施帧之前的第 k 帧,以构建基准的 VIC-Async-k 数据集。在实验中设置 $k=1, 2$。 作者将 VIC-Sync 和 VIC-Async-k 数据集分别划分为 5:2:3 作为训练/验证/测试集。我们使用联合标注来评估以车辆为中心的视图下的检测结果。
Baselines
在这里,我们提出了几种具有不同模式和融合方法的 VIC3D 目标检测基线。
LiDAR detection baseline with Late Fusion. 为了通过利用设施和车辆数据来证明性能的提高,作者实施了一个带有设施检测器和车辆检测器的后期融合框架。首先,作者选择 PointPillars 作为3D 检测器,并在 VIC-Sync 中分别用设施视图和车辆视图数据训练这两个检测器。然后,作者将设施预测转换为车辆激光雷达坐标系,并将预测结果基于欧几里得距离和匈牙利方法使用一个匹配器合并,以生成融合结果。
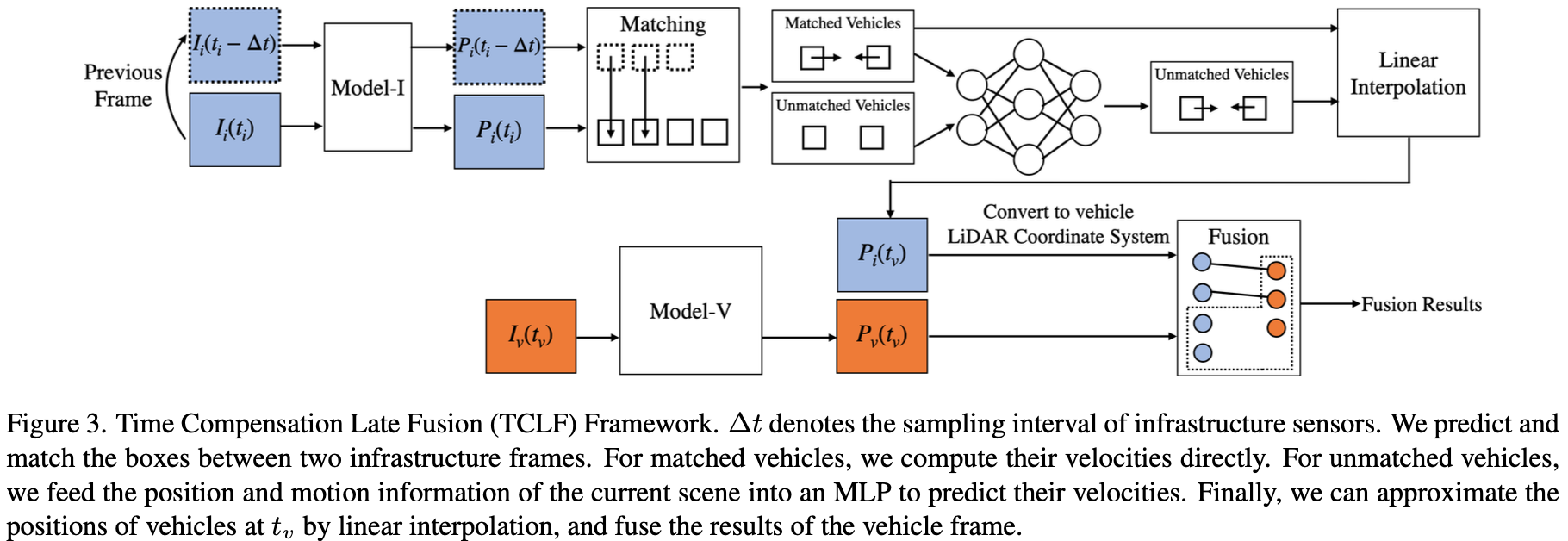
为了说明时间异步问题,作者还在 VIC-Async-k 数据集上实现了激光雷达检测后期融合基线。此外,基于跟踪和状态估计,作者提出了 Time Compensation Late Fusion(TCLF) 框架。TCLF主要由以下三个部分组成:
1) 估计具有两个相邻设施帧的目标的速度
2) 估计在时间 $t_v$ 设施目标的状态
3) 按照激光雷达后期融合基线的方式融合估计的设施预测和车辆预测
TCLF框架的细节见图3。
 请注意,作者还报告了仅设施数据和车辆数据的评估结果,这些数据分别命名为 Veh.-Only 和 Inf.-Only。评估结果显示在表3。
请注意,作者还报告了仅设施数据和车辆数据的评估结果,这些数据分别命名为 Veh.-Only 和 Inf.-Only。评估结果显示在表3。
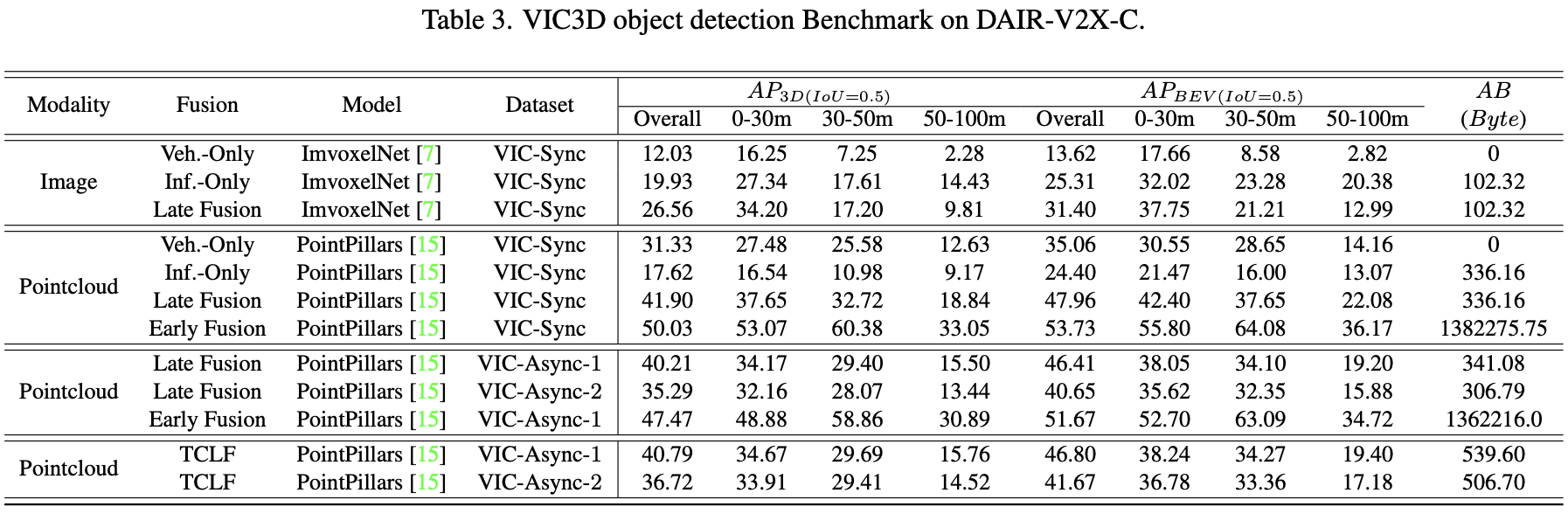
Image detection baseline with Late Fusion. 为了检查仅图像的 VIC3D 目标检测,作者还通过仅设施图像和车辆图像实现后期融合框架。作者选择 ImvoxelNet 作为3D检测器并且使用 VIC-Sync 训练数据的相应部分训练设施检测器以及车辆检测器。 作者实现了图像检测后期融合遵循激光雷达后期融合的方案。
LiDAR detection baseline with Early Fusion. 为了探索原始数据级别的融合效果,作者在 VIC-Sync 数据集上实现了以 PointPillars 为3D检测器的早期融合。作者首先将 VIC-Sync 数据集中设施点云转换为车辆激光雷达坐标系统,然后融合设施点云和车辆点云。作者直接使用点云训练和评估检测器。为了进一步说明时间异步问题,作者还在 VIC-Async-k 数据集上实现了与PointPillars的早期融合。
Analysis
在这里,作者分析了第5.1.1节中 VIC3D 目标检测基准方法的属性。
Cooperative-view vs. Single-view. 作者比较了使用设施数据和车辆数据的方法的每种形式。在表3中,后期融合的检测性能比 Veh.-Only 或 Inf.-Only 的性能要好得多,无论是基于图像还是基于激光雷达,还是基于VIC-Sync 数据集或 VIC-Async-k 数据集。例如,在 VIC-Sync 数据集上使用后期融合的 LiDAR Detection 3D检测达到 41.90 AP 和 BEV Detection 达到 47.96 AP。然而,仅使用车辆数据的激光雷达检测在3D检测中仅达到 31.33% AP,在BEV检测方面的 AP 达到 35.06%,而仅使用设施数据的 LiDAR检测在3D检测中仅达到17.62%的AP 和 BEV检测的 AP 为24.40%。实验结果表明,融合设施信息可以有效地提升车辆的感知性能。这主要是因为设施数据提供了补充信息,弥补了车辆的感受野。图4中显示了可视化样本。

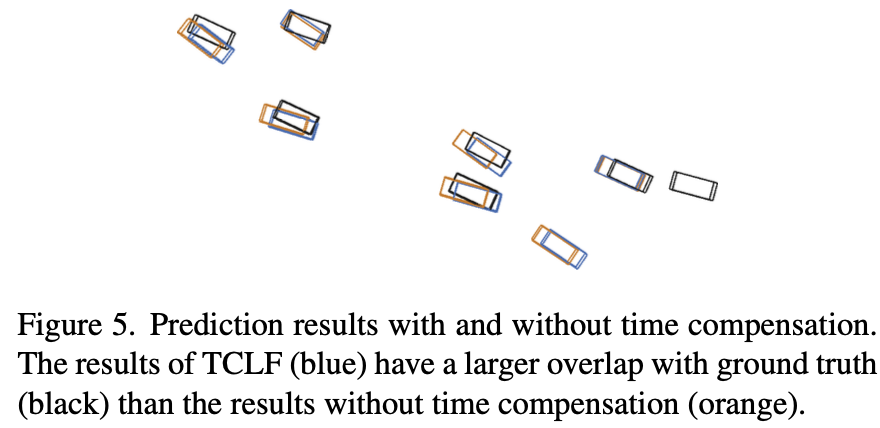
Temporal Asynchrony vs Time Compensation. 时间异步给融合基础设施数据带来了挑战。与 VIC-Sync 数据集的结果相比,带有融合的激光雷达检测性能在 VIC-Async-k 上显著下降(VIC-Async-1为2点,VIC-Async-2上有6点)。下降主要是由于移动物体的状态变化,导致匹配困难和融合误差。然而,TCLF 可以有效地提高 VIC-Async-1 和 VIC-Async-2 上高达 0.5%AP 和 1.5%AP 的后期融合性能,这表明时间补偿可以有效地缓解时间异步问题,特别是在时间延迟较大的情况下。图5中提供了充足的可视化。
Early Fusion vs. Late Fusion. 与后期融合相比,无论是基于 VIC-Sync 数据集还是 VIC-Async-1 数据集,早期融合在 BEV 和 3D 基准下都实现了高达8%的AP。然而,早期融合应该传输整个点云,并承受极高的传输成本,大约是后期融合的4000倍。对于更实际的应用,作者鼓励未来研究在消耗更少传输带宽的同时实现更好的性能。将来,作者还将为基准发布特征融合。
Benchmark for SV3D Detection
作者为那些对基于 DAIR-V2X-V 和 DAIR-V2X-I 数据集的单视图(SV)3D检测任务感兴趣的人提供了广泛的3D检测基准。与 DAIR-V2X-C 中的单面数据相比,这两个数据集更加多样化,在实现3D目标检测方面可能更具挑战性。因此,作者鼓励那些仅旨在提高 DAIR-V2X-V 和 DAIR-V2X-I 上车辆3D目标检测或设施3D目标性能的研究人员。
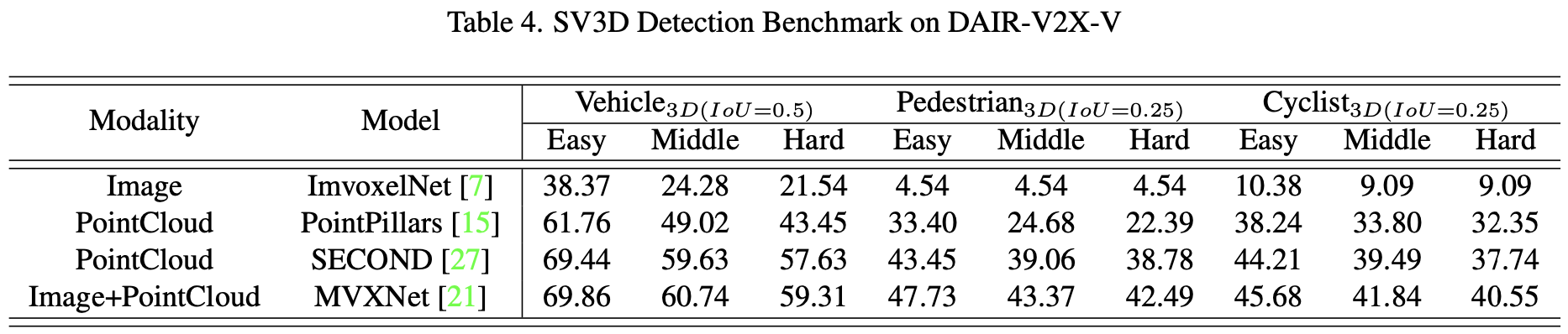
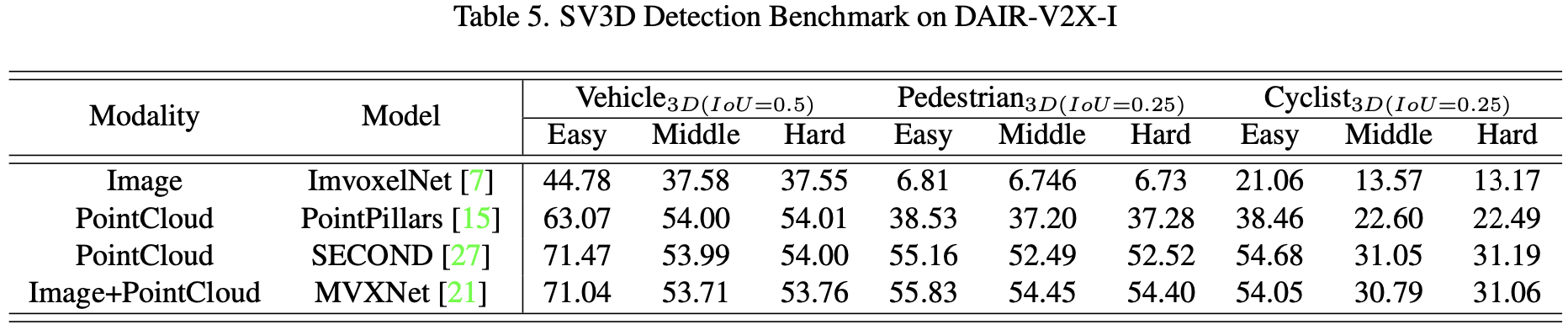
作者将 DAIR-V2X-V 和 DAIR-V2X-I 数据集按 5:2:3 划分为训练/验证/测试部分。作者分别在两个数据集上提出了一些基于不同模态的方法的基线:ImvoxelNet、PointPillars、SECOND和MVXNet。作者使用 PASCAL 标准 KITTI[10] 来评估3D目标检测性能,即根据图像平面上的边界框高度对远距离物体进行过滤。评估使用三种模式,包括Easy、Moderate和Hard模式。作者使用MMDetection3D框架实现这些基线, 如表4和表5所示。
Conclusion
这篇文章介绍了DAIR-V2X,这是第一个用于车辆基础设施合作自动驾驶的大规模、多模态、多视图数据集,所有帧都从真实场景中3D标注的。
作者还定义了 VIC3D 目标检测,以制定使用车辆和基础设施的传感器输入协作定位和识别3D目标的问题。
除了解决传统的3D目标检测问题外,VIC3D的解决方案还需要解决车辆和基础设施传感器之间的时间异步问题以及它们之间的数据传输成本。
为了便于未来的研究,作者提出的 Time Compensation Late Fusion 框架为检测模型提供了一个VIC3D基准,以及车辆视图和基础设施视图数据集3D检测的基准。
结果表明,集成基础设施传感器的数据平均比单车 3D 检测高15%的AP,TCLF 可以缓解时间异步问题。
-
Previous
【深度学习】Fast R-CNN -
Next
【深度学习】ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection