Abstract
在计算机视觉任务的智能分析中,高吞吐量成像很好。在传统设计中,吞吐量受到物理图像捕获和数字后期处理分离的限制。计算成像通过图像捕获流程混合模拟和数字处理来增加吞吐量。然而,计算成像的最新进展侧重于“压缩采样”,这阻碍了在实际任务中的广泛应用。这篇文章对基于快照压缩成像(SCI)和语义计算机视觉(SCV)任务的计算成像的下一步进行了系统分析,这些任务在过去十年中作为基本的计算成像平台独立出现。
SCI是一个物理层过程,可以最大限度地提高每个样本的信息容量,同时最大限度地减少系统大小、功率和成本。SCV是一个抽象层过程,将图像数据分析为对象和特征,而不是简单的像素映射。在目前的实践中,SCI和SCV是独立和 sequential 的。这种串联流程导致以下问题:i)大量资源用于与任务无关的计算和传输,ii)SCI的采样和设计效率减弱,iii)SCV的最终性能受到SCI重建错误的限制。考虑到这些担忧,这篇文章进一步旨在弥合 SCI 和 SCV 之间的差距,以充分利用这两种方法。
在回顾了SCI的现状后,作者提出了一个新的联合框架,通过对SCI捕获的原始观测进行SCV来选择感兴趣的区域,然后在这些区域进行重建,以加快处理时间。作者使用最近构建的SCI原型来验证该框架。提出了初步结果,并讨论了 SCI 和 SCV 联合的前景。通过在压缩域中执行计算机视觉任务,作者设想了一个端到端带宽有限的快照压缩成像的新时代即将到来。
Introduction
成像是计算机视觉(CV)的创始支柱,它现在是当今数字世界的核心技术,特别是在多媒体领域,在消费和军事电子以及元宇宙等新兴主题中有着广泛的应用。从1970年 charge-coupled devices(CCD)的发明开始[1],数字成像技术彻底改变了CV。随着生命的不断前进,成像技术也是如此。特别是,由于人工智能,特别是机器学习和深度学习的最新进展,计算成像(CI)[2, 3]已进入一个新阶段。我们很幸运地见证了一个由CI和CV驱动的新时代。这篇文章更进一步,旨在弥合 CI 和 CV 之间的差距,特别是快照压缩成像(SCI)[4]和语义计算机视觉(SCV)任务之间的差距。
CI是一个新兴的多学科主题,涵盖光学、传感器、图像处理、信号处理和机器学习,旨在将计算设计纳入图像捕获过程,以提高图像质量[5-8],优化成像系统和程序[9-11],获取高维视觉信息[12-14]或提高后续高级任务的性能。另一方面,计算机视觉主要专注于高级图像处理和理解任务,如图像分类[18、19]、语义分割[20、21]、目标检测和跟踪[22-24]、视频字幕[25、26]等,很少关注之前的图像获取过程。CI和CV是与成像采集、处理和理解相关的两个紧密领域。共享智能成像的相似目标,并由机器学习等共同引擎驱动,CI和CV已经来到了同一个大舞台,以揭示彼此。因此,现在是共同考虑CI和CV的合适时机。通过这种方式,将出现设计视觉信息获取、处理和理解整个过程的新框架。
作为CI和CV的两个新兴话题,SCI和SCV在各自领域引起了越来越多的关注。一方面,随着对4K和8K录制等超高清视频采集需求的增加,当前成像系统的带宽已成为进一步发展的瓶颈。摩尔定律的结束使得仅仅通过提高硬件性能很难打破障碍。进而,基于压缩感知(CS)的SCI可以通过在采集期间进行数据压缩来为这一困境提供可行的解决方案[4]。通过调查自然图像或视频先验的内在冗余,SCI能够通过精心设计的编码观测策略,使用传统的2D相机获取视频和高光谱图像等高维信号。通过这种方式,可以在不牺牲有用信息的情况下大幅减少带宽。此外,SCI系统和重建算法的最新进展为SCI在我们的日常生活中的应用铺平了道路。
另一方面,在大数据时代,我们正面临越来越多的来自社交媒体、监控、自动驾驶、物联网、遥感等的多媒体数据,这些数据严重依赖自动信息分析。在这种情况下,从海量多媒体数据中提取高级语义信息已成为计算机视觉中最重要的任务之一。随着深度学习的快速发展,我们在SCV领域取得了重大进展。例如,我们正在不断推进自动信息处理系统的智能水平,从图像分类[19]、语义分割[27]、目标检测和跟踪[23]到动作识别[28]、面部表情识别[29]、场景理解[30]和视频字幕[31]。
虽然SCI和SCV分别在CI和CV中发挥着越来越重要的作用,但它们尚未得到共同考虑,这阻碍了它们的相互发展。因此,弥合SCI和SCV之间的差距已成为利用彼此优势实现双赢未来的紧迫方向和前景。这篇文章提出了一个结合SCI和SCV的新框架,以高效地实施压缩视频采集和语义信息检索的整个过程。为了验证将SCI和SCV连接起来的可行性,同时揭露推进联合框架的挑战,作者构建了一个SCI原型系统,该系统可以使用传统的低速传感器捕获编码的高速视频。此外,还设计了一条涉及目标跟踪、深度估计和场景理解的语义信息检索流程,以便对目标视频进行定性和定量描述。如图1所示,作为将SCI和SCV结合起来在自然场景中实际应用的首次尝试,作者相信其工作可以为CI和CV的合作提供新的见解,并揭示相应技术在未来的日常生活中的应用。
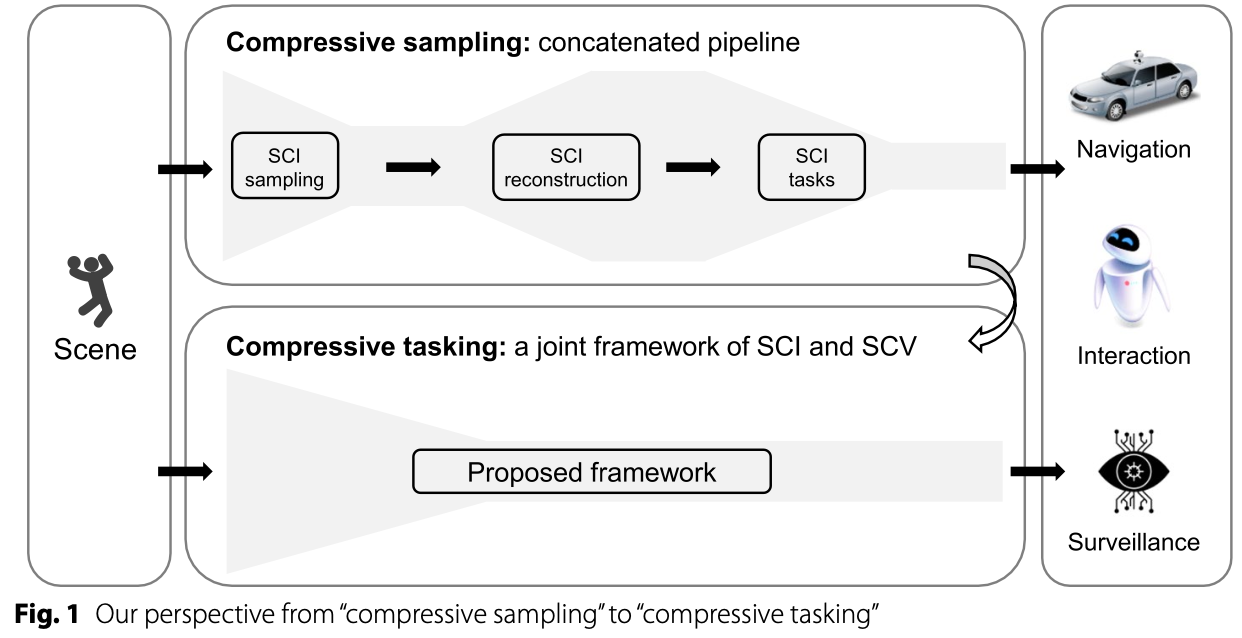
Joint development of SCI and SCV
与专注于捕获方面的SCI不同,动态场景中语义计算机视觉的处理框架通常包括以下阶段:场景理解、目标检测和跟踪、行为分类和描述、人或车辆识别以及定量和定性数据融合。
作为可视化信息采集和处理流程中的两个顺序模块,面向硬件的CI和任务驱动的CV是自然互补的。因此,提高整体性能已成为将SCI和SCV相结合的新趋势。
Kwan等人提出了一种新的目标跟踪和分类方案,使用 pixel-wise coded exposure 相机捕获的压缩观测,并分别使用可见光、短波红外(SWIR)、中波红外(MWIR)和长波红外(LWIR)视频进行了广泛实验,展示了所提方法的有效性[63、65、66]。他们通过合成压缩观测对YOLO进行了重新训练,以提取目标位置,并将它们联系起来以创建轨迹。然后,使用受过压缩观测训练的ResNet分类器单独进行分类。值得注意的是,这项工作直接将编码观测视为单个图像,并执行了随后的计算机视觉任务,但忽略了测量的视频属性,这减弱了SCI在高吞吐量高速成像中的优势。Hu等人进一步扩展了这项工作,提出了VODS,即通过神经网络从单个编码图像中检测视频目标。在这项工作中,他们用神经网络模拟了光学编码过程,将编码 mask 的像素值作为可训练的参数。然后,CNN解码器和目标检测网络按顺序级联,以执行接下来的目标检测和分类任务。在训练期间,光学编码器、CNN解码器和目标检测网络中的所有可训练参数都进行了联合更新,以实现整体优化性能。通过利用SCI的高速成像特性和深度学习在目标检测方面的优势,VODS使使用低速传感器进行高速目标检测成为可能。同样,Okawara等人通过结合SCI和深度神经网络,从单个编码图像实现了无重建的动作识别。除了联合优化策略外,他们还设计了一个移位变化卷积,以适应SCI的时空编码造成的空间不平滑。最后,他们通过单个编码图像实现了相对较高的识别精度,这与具有原始高速视频的传统3D卷积网络相当。
A novel joint framework of SCI and SCV
为了弥合新兴的SCI技术和SCV任务之间的差距,作者提出了一个新的联合框架(图3),以利用双方的优势,并高效地实施编码高速视频采集、定性描述和定量描述生成的整个过程。 作者认为,该框架可以提供一种可能的途径,模糊高通量视频捕获和相应的高级语义信息检索之间的界限。
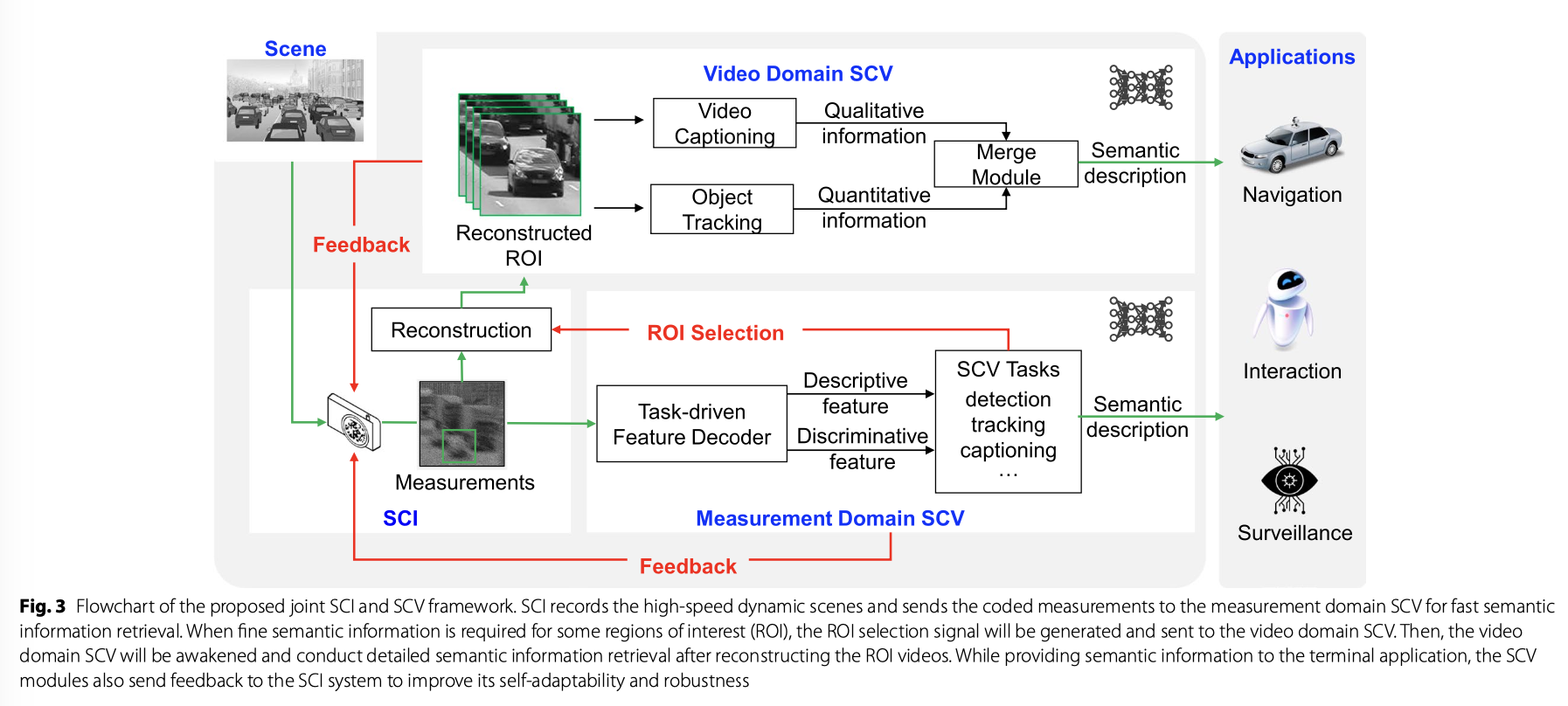
Closing the loop
深入研究 SCI 和 SCV 的合作,可以进一步介绍 SCV 对 SCI 的反馈,以调整SCI系统的压缩比[69]或根据语义信息检索结果优化其编码 mask。 通过这种方式,框架的自适应性、鲁棒性和整体性能可以进一步提高[16]。
总之,所提出的框架能够有效地从自然场景中提取视觉信息,并将其转换为语义描述,这促进了导航、交互和监视等许多终端应用程序。为了验证该框架的可行性并积累进一步发展的经验,作者进行了一次户外实验,并在下一节中演示了初步结果。
Conclusion
SCI 和 SCV是两个密切相关的与图像获取、处理和理解相关的领域,具有共同发展以实现双赢未来的巨大潜力。
虽然之前对 SCI 的研究侧重于压缩采样,但作者将SCI扩展到压缩任务,旨在使SCI更接近实际应用。
实际上,为了弥合SCI和SCV之间的差距,我们回顾了这两个领域的现状,并提出了一个新的联合框架,该框架实现了视觉信息捕获和语义信息提取的端到端流程。
该框架利用SCI在低带宽高吞吐量成像中,使用传统相机实现高速视频采集,并提出了一种自适应 观测/视频 域信息处理策略,以提高语义信息检索的效率。
为了验证框架的有效性并发现实际应用中的潜在问题,作者进行了户外实验,并提出了初步结果和详细分析。
最后,作者给出了前瞻性展望,并为该框架的未来发展提供了可能的方向。
作者认为,随着SCI和SCV的快速发展,所提出的框架将很快在实际应用中可用,并为大规模视觉信息获取和相应的智能分析开辟一条新的道路。
-
Previous
【深度学习】ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection -
Next
【机器学习】Generalized Assorted Pixel Camera(CAVE):Postcapture Control of Resolution, Dynamic Range, and Spectrum