Overview
应该下载哪些 dataset splits? 每年的图像都与不同的任务相关联。具体地说:
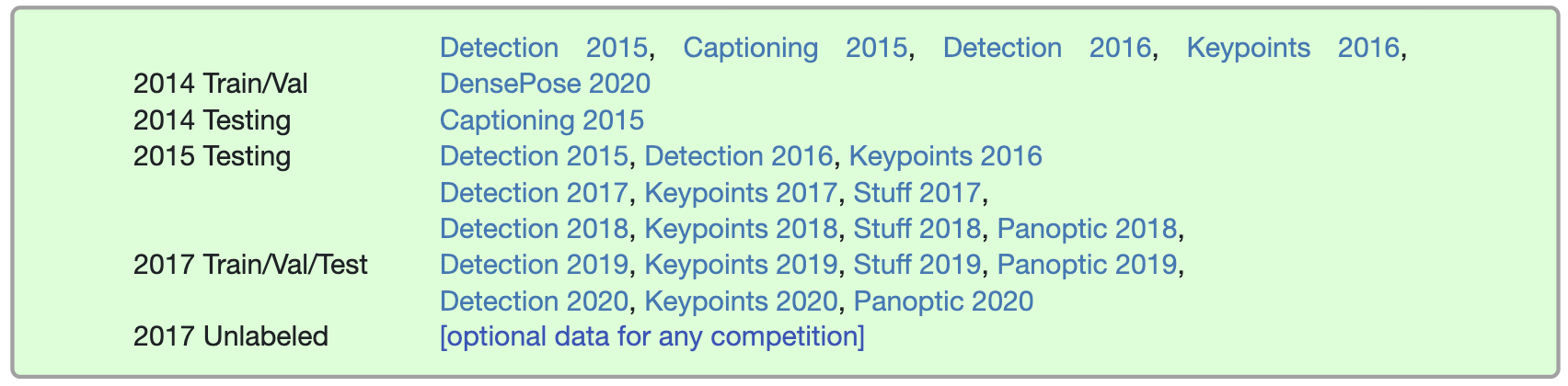
如果你要提交2017年、2018年、2019年或2020年的任务,你只需要下载2017年的图片。你可以忽略之前的 split 。注: split 年份是指 image splits 发布的年份,而不是标注发布的年份。
2020 Update: 所有挑战的所有数据保持不变。
2019 Update: 所有挑战的所有数据保持不变。
2018 Update: 检测和关键点数据不变。2018年新推出,2017年所有图片的完整 stuff 和 panoptic 标注都可以使用。 注: 如果你下载了 06/17/2018 之前的 stuff 标注, 请重新下载。
2017 Update: 2017年的主要变化是,根据社区反馈,train/val的 split 现在不是83K/41K train/val split,而是118K/5K。使用相同的图像,没有提供新的检测/关键点标注。2017年新增的是 40K 训练图片(2017年118K 训练图片的子集) 和 5K val 图片上的 stuff 标注。此外,对于测试,在2017年,测试集只有两个 split(dev/challenge),而不是前几年使用的四个split(dev/standard/reserve/challenge)。最后,在2017年,将发布来自COCO的120K未标记图像,这些图像遵循与标记图像相同的类分布; 这对于COCO上的半监督学习可能是有用的。
COCO API
COCO API有助于在COCO中加载、解析和可视化标注。这些API支持多种格式。

Python API demo
导入包
1
2
3
4
5
6
7
%matplotlib inline
from pycocotools.coco import COCO
import numpy as np
import skimage.io as io
import matplotlib.pyplot as plt
import pylab
pylab.rcParams['figure.figsize'] = (8.0, 10.0)
目录
1
2
3
dataDir='..'
dataType='val2017'
annFile='{}/annotations/instances_{}.json'.format(dataDir,dataType)
初始化
1
2
# initialize COCO api for instance annotations
coco=COCO(annFile)
展示类别:
1
2
3
4
5
6
7
# display COCO categories and supercategories
cats = coco.loadCats(coco.getCatIds())
nms=[cat['name'] for cat in cats]
print('COCO categories: \n{}\n'.format(' '.join(nms)))
nms = set([cat['supercategory'] for cat in cats])
print('COCO supercategories: \n{}'.format(' '.join(nms)))
给定类别,得到所有包含该类别的图像, 随机选择一个
1
2
3
4
5
# get all images containing given categories, select one at random
catIds = coco.getCatIds(catNms=['person','dog','skateboard']);
imgIds = coco.getImgIds(catIds=catIds );
imgIds = coco.getImgIds(imgIds = [324158])
img = coco.loadImgs(imgIds[np.random.randint(0,len(imgIds))])[0]
加载并展示一个图像
1
2
3
4
5
6
7
# load and display image
# I = io.imread('%s/images/%s/%s'%(dataDir,dataType,img['file_name']))
# use url to load image
I = io.imread(img['coco_url'])
plt.axis('off')
plt.imshow(I)
plt.show()
加载并展示实例标注
1
2
3
4
5
# load and display instance annotations
plt.imshow(I); plt.axis('off')
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns)

为人关键点标注初始化 COCO api
1
2
3
# initialize COCO api for person keypoints annotations
annFile = '{}/annotations/person_keypoints_{}.json'.format(dataDir,dataType)
coco_kps=COCO(annFile)
加载并展示关键点标注
1
2
3
4
5
6
# load and display keypoints annotations
plt.imshow(I); plt.axis('off')
ax = plt.gca()
annIds = coco_kps.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco_kps.loadAnns(annIds)
coco_kps.showAnns(anns)

为 caption 标注初始化 COCO API
1
2
3
# initialize COCO api for caption annotations
annFile = '{}/annotations/captions_{}.json'.format(dataDir,dataType)
coco_caps=COCO(annFile)
1
2
3
4
5
# load and display caption annotations
annIds = coco_caps.getAnnIds(imgIds=img['id']);
anns = coco_caps.loadAnns(annIds)
coco_caps.showAnns(anns)
plt.imshow(I); plt.axis('off'); plt.show()

Mask API
COCO为每个目标实例提供分割 mask。这就产生了两个挑战: 紧凑地存储 mask 和高效地执行 mask 计算。我们使用自定义 Run Length Encoding(RLE) 方案解决了这两个挑战。RLE表示的大小与 mask 的边界像素的数量成正比,并且可以直接在 RLE 上高效地计算诸如区域、并集或交集等操作。具体地说,假设相当简单的形状,RLE表示为 $O(\sqrt(n)$ ,其中 $n$ 是目标中的像素数,常见的计算也是 $O(\sqrt{n})$。 朴素地对解码后的 mask (存储为数组)进行相同的运算将是 $O(n)$ 。
MASK API提供了一个接口,用于操作以 RLE 格式存储的 mask 。最后,我们注意到大部分的基本真实 mask 都存储为多边形(非常紧凑),这些多边形在需要时被转换为RLE。

Reference
-
Previous
【深度学习】Diffusion Model -
Next
【深度学习】Real-Time Object Detection and Localization in Cimpressive Sensed Video