Abstract
准确检测3D点云中的物体是许多应用的核心问题,例如自主导航、家政机器人和增强/虚拟现实。
为了将高度稀疏的激光雷达点云与区域提议网络(RPN)连接起来,大多数现有工作都集中在手工制作的特征表示上,例如,鸟瞰投影。
在这项工作中,作者消除了3D点云手动特征工程的需要,并提出了VoxelNet,这是一个通用的3D检测网络,将特征提取和边界框预测统一到单阶段的端到端可训练深层网络中。
具体而言,VoxelNet将点云划分为间隔相同的3D体素,并通过新引入的体素特征编码(VFE)层将每个体素中的一组点转换为统一的特征表示。
通过这种方式,点云被编码为 descriptive volumetric 表征,然后连接到RPN以生成检测。
KITTI汽车检测基准的实验表明,VoxelNet的表现远远优于最先进的基于激光雷达的3D检测方法。
此外,该网络学习了对具有各种几何形状的物体的有效判别性表示,从而在仅基于激光雷达对行人和非机动车进行3D检测方面产生良好的结果。
VoxelNet
在本节中,解释了VoxelNet的架构、用于训练的损失函数以及实现网络的高效算法。
VoxelNet Architecture
提出的VoxelNet由三个功能块组成:(1) 特征学习网络, (2) 卷积中间层网络 和 (3) 区域提议网络,如图2所示。
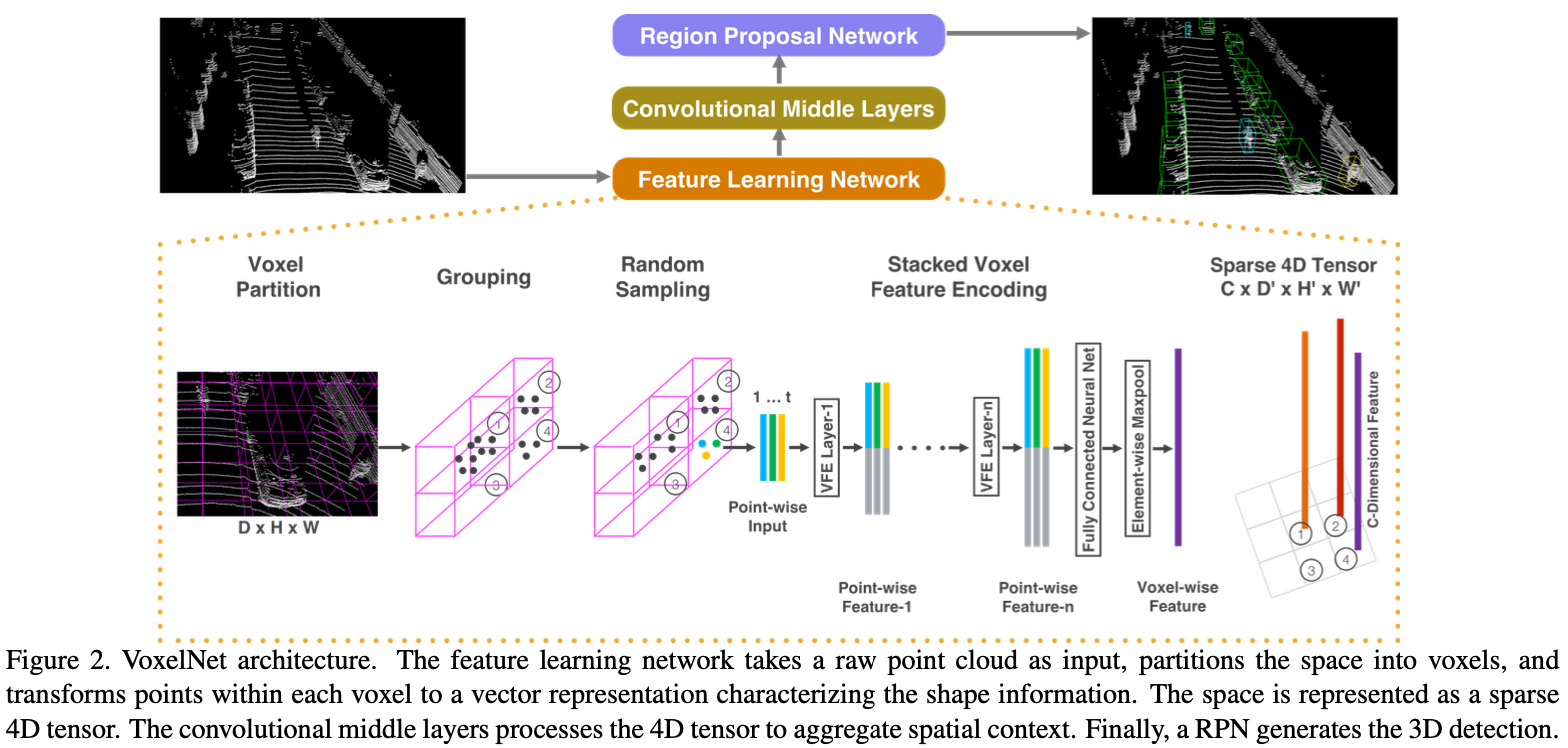
Feature Learning Network
Voxel Partition 给定点云,将3D空间细分为等间隔的体素,如图2所示。假设点云分别沿着Z、Y、X轴包含D、H、W范围的3D空间。相应地定义了每个大小为 $v_D$、$v_H$ 和 $v_W$ 的体素。产生大小为 $D’ = D / v_D, H’ = H / v_{H}, W’ = W / v_W$。 为了简便,我们假设 $D, H, W$ 是多个 $v_D, v_H, v_W$。
Grouping 我们根据它们在的体素对点进行分组。由于距离、遮挡、物体的相对位姿和不均匀采样等因素,激光雷达点云稀疏,整个空间的点密度变化很大。因此,分组后,体素将包含可变数量的点。图2显示了Voxel-1的点明显多于Voxel-2和Voxel-4,而Voxel-3不包含任何点。
Random Sampling 通常,高清激光雷达点云由∼100k点组成。直接处理所有点不仅会给计算平台带来更大的内存/效率负担,而且整个空间的高度可变点密度可能会影响检测。为此,我们从那些包含超过 $T$ 个点的体素中随机抽取一个固定数 $T$。这种采样策略有两个目的,(1)计算节省(详见第2.3节);(2)减少体素之间的点不平衡,从而减少采样偏差,并为训练增加多样性。
Stacked Voxel Feature Encoding 关键创新是VFE层。为了简单起见,图2说明了一个体素的分层特征编码过程。在不失去泛化性的情况下,我们使用VFE第1层来描述以下段落中的细节。图3显示了VFE第1层的架构。
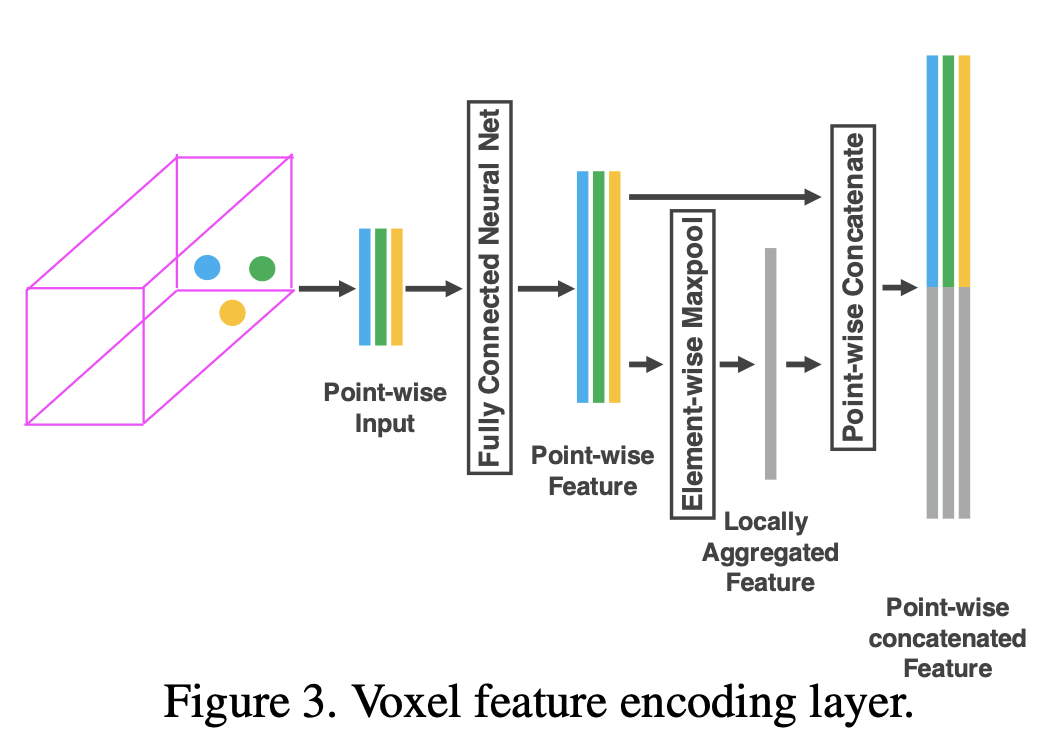 表示 $V = {p_i = [x_i, y_i, z_i, r_i]^T \in \mathbb{R}^4}{i=1, …, t}$ 为一个包含 $t \leq T$ 激光雷达点的非空体素, 其中 $p_i$ 包含第 $i$ 个点的 XYZ 坐标, $r_i$ 是接收到的反射。首先将局部平均值计算为 V 中所有点的质心,表示为 $(v_x, v_y, v_z)$。 然后,我们用质心的相对偏移量w.r.t.增强每个点 $p_i$,并获得输入特征集 $V{in} = {\hat p_i = [x_i, y_i, z_i, r_i, x_i - v_x, y_i - v_y, z_i - v_z]^T \in R^7}{i=1, …, t}$。 接下来, 每个 $\hat p_i$ 通过全连接网络(FCN) 转换到一个特征空间, 其中我们可以从点特征 $f_i \in R^m$ 聚合信息。FCN 由线性层、批处理归一化(BN)层和 ReLU 层组成。在获得点特征表示后,我们在与 V 关联的所有 $f_i$ 上使用元素级MaxPooling来获得 V 的局部聚合特征 $\tilde f \in R^m$。最终,我们用 $\tilde f$ 增强 $f_i$ 形成点级别的拼接特征 $f_i^{out} = [f_i^T, \tilde f^T]^T \in R^{2m}$。 因此我们得到输出特征集合 $V{out} = {f^{out}i}{i…t}$。 所有的非空体素以相同的方式编码并且他们共享FCN的参数。
表示 $V = {p_i = [x_i, y_i, z_i, r_i]^T \in \mathbb{R}^4}{i=1, …, t}$ 为一个包含 $t \leq T$ 激光雷达点的非空体素, 其中 $p_i$ 包含第 $i$ 个点的 XYZ 坐标, $r_i$ 是接收到的反射。首先将局部平均值计算为 V 中所有点的质心,表示为 $(v_x, v_y, v_z)$。 然后,我们用质心的相对偏移量w.r.t.增强每个点 $p_i$,并获得输入特征集 $V{in} = {\hat p_i = [x_i, y_i, z_i, r_i, x_i - v_x, y_i - v_y, z_i - v_z]^T \in R^7}{i=1, …, t}$。 接下来, 每个 $\hat p_i$ 通过全连接网络(FCN) 转换到一个特征空间, 其中我们可以从点特征 $f_i \in R^m$ 聚合信息。FCN 由线性层、批处理归一化(BN)层和 ReLU 层组成。在获得点特征表示后,我们在与 V 关联的所有 $f_i$ 上使用元素级MaxPooling来获得 V 的局部聚合特征 $\tilde f \in R^m$。最终,我们用 $\tilde f$ 增强 $f_i$ 形成点级别的拼接特征 $f_i^{out} = [f_i^T, \tilde f^T]^T \in R^{2m}$。 因此我们得到输出特征集合 $V{out} = {f^{out}i}{i…t}$。 所有的非空体素以相同的方式编码并且他们共享FCN的参数。
我们用 VFE-i($c_{in}, c_{out}$) 表示第 i 个 VFE 层, 其将输入特征维度 $c_{in}$ 变换为输出特征维度 $c_{out}$。 线性层学习一个大小为 $c_{in} \times (c_{out} / 2)$ 的矩阵, 并且按点拼接生成维度为 $c_{out}$ 的输出。
由于输出特征结合了按点特征和局部聚合特征,堆叠VFE 层编码了体素中的点交互,并使最终的特征表示能够学习描述性形状信息。 体素级别的特征通过 FCN 转换 VFE-n 的输出得到, 并且应用按元素级别的最大池化, $C$ 是体素级别的特征的维度, 如图2所示。
Sparse Tensor Representation 通过仅处理非空体素,我们得到了一个体素特征列表,每个特征都与特定非空体素的空间坐标唯一相关。获得的体素级特征列表可以表示为稀疏的4D张量,大小为 $C \times D′ \times H′ \times W′$ 如图2所示。虽然点云包含约10万个点,但超过90%的体素通常是空的。将非空体素特征表示为稀疏张量大大降低了反向传播期间的内存使用和计算成本,这是我们高效实现的关键一步。
Convolutional Middle Layers
我们使用 ConvMD($c_{in}, c_{out}, k, s, p$) 表示 $M$ 维度卷积操作, 其中 $c_{in}$ 和 $c_{out}$ 是输入和输出通道的数量, $k, s$ 和 $p$ 分别是 $M$ 维度向量对应的核大小, 步长大小和填充大小。当跨 M 维度的大小相同, 我们使用一个标量表示大小, 例如 $k = (k, k, k)$。
每个卷积中间层依次应用3D卷积、BN层和ReLU层。卷积中间层聚集了逐渐扩大的感受野中的体素特征,为形状描述增加了更多的上下文。第3节解释了卷积中间层中卷积核的详细尺寸。
Region Proposal Network
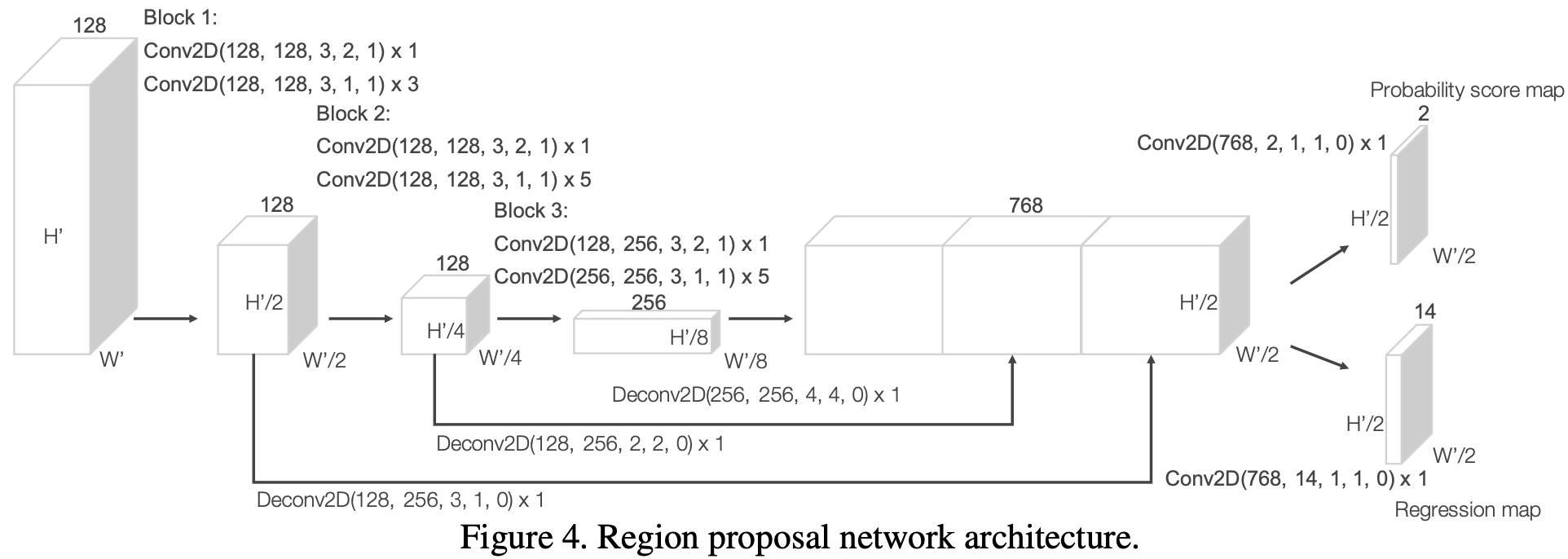
最近,区域提议网络已成为性能最佳目标检测框架的重要组成部分。在这项工作中,我们对[32]中提出的RPN架构进行了几项关键修改,并将其与特征学习网络和卷积中间层相结合,形成端到端可训练的流程。
我们RPN的输入是由卷积中间层提供的特征图。该网络的架构如图4所示。该网络有三个全卷积层的块。每个块的第一层通过步长为2的卷积采样特征图的一半,然后是步长为1的卷积序列。在每个卷积层之后,应用BN和ReLU操作。然后,我们将每个块的输出上采样到固定大小,并进行拼接以构建高分辨率特征图。最后,该特征图映射到学习目标:(1)概率分数图和(2)回归图。
Loss Function
令 ${\alpha_i^{pos}}{i=1, …, N{pos}}$ 表示 $N_{pos}$ 正先验框集合和 ${\alpha_j^{neg}}{j=1, …, N{neg}}$ 表示 $N_{neg}$ 负先验框集合。 我们参数化一个 3D 真实边界框为 $(x_c^g, y_c^g, z_c^g, l^g, w^g, h^g, \theta^g)$ , 其中 $x_c^g, y_c^g, z_c^g$ 表示中心位置, $l^g, w^g, h^g$ 是边界框的长宽高, $\theta^g$ 是绕 Z 轴的偏航旋转角度。从参数化的匹配正先验框中检索真实边界框 $(x_c^a, y_c^a, z_c^a, l^a, w^a, h^a, \theta^a)$, 我们定义残差向量 $u^* \in R^7$ 包含 7 个回归目标, 对应于中心位置 $\Delta x, \Delta y, \Delta z$, 三个维度 $\Delta l, \Delta w, \Delta h$ 和旋转 $\Delta \theta$, 其计算为:
\(\Delta x = \frac{x_c^g - x_c^a}{d^a}, \Delta y = \frac{y_c^g - y_c^a}{d^a}, \Delta z = \frac{z_c^g - z_c^a}{h^a} \\ \Delta l = \log (\frac{l^g}{l^a}), \Delta w = \log (\frac{w^g}{w^a}), \Delta h = \log(\frac{h^g}{h^a}) \\ \Delta \theta = \theta^g - \theta^a\) 其中 $d^a = \sqrt{(l^a)^2 + (w^a)^2}$ 是先验框基的对角线。在这里,我们的目标是直接估计带方向的3D框,并与对角线 $d^a$ 均匀地归一化 $\Delta x$ 和 $\Delta y$。我们将损失函数定义如下:
\[L = \alpha \frac{1}{N_{pos}} \sum_i L_{cls}(p_i^{pos}, 1) + \beta \frac{1}{N_{neg}} \sum_j L_{cls}(p_j^{neg}, 0) + \frac{1}{N_{pos}} \sum_i L_{reg}(u_i, u_i^*)\]其中 $p_i^{pos}$ 和 $p_j^{neg}$ 表示正先验框和负先验框的 softmax 输出,$u_i \in R^7, u_i^* \in R^7$。前两项是规范化的分类损失, 其中 $L_{cls}$ 表示交叉熵损失, $\alpha, \beta$ 是正常数用于平衡相对重要性。最后一项 $L_{reg}$ 是回归损失, 其中我们使用 SmothL1 函数。
Efficient Implementation
GPU针对处理密集张量结构进行了优化。直接使用点云的问题在于,点分布在空间中稀疏,每个体素都有可变的点数。 我们设计了一种方法,将点云转换为密集的张量结构,其中堆叠的VFE操作可以跨点和体素并行处理。
图5总结了该方法。我们初始化一个 $K \times T \times 7$ 维张量结构来存储体素输入特征缓冲区,其中 $K$ 是非空体素的最大数量,$T$ 是每个体素的最大点数,$7$ 是每个点的输入编码维数。这些点在处理前是随机的。 对于点云中的每个点,我们检查相应的体素是否已经存在。此查找操作在 $O(1)$ 中使用voxel坐标作为哈希键的哈希表高效完成。如果体素已经初始化,如果体素点小于T点,我们会将该点插入体素位置,否则该点将被忽略。如果体素未初始化,我们将初始化一个新的体素,将其坐标存储在体素坐标缓冲区中,并将点插入此体素位置。体素输入特征和坐标缓冲区可以通过单次传递点列表来构建,因此其复杂性为O(n)。为了进一步提高内存/计算效率,可以只存储数量有限的体素(K),而忽略来自很少点的体素的点。
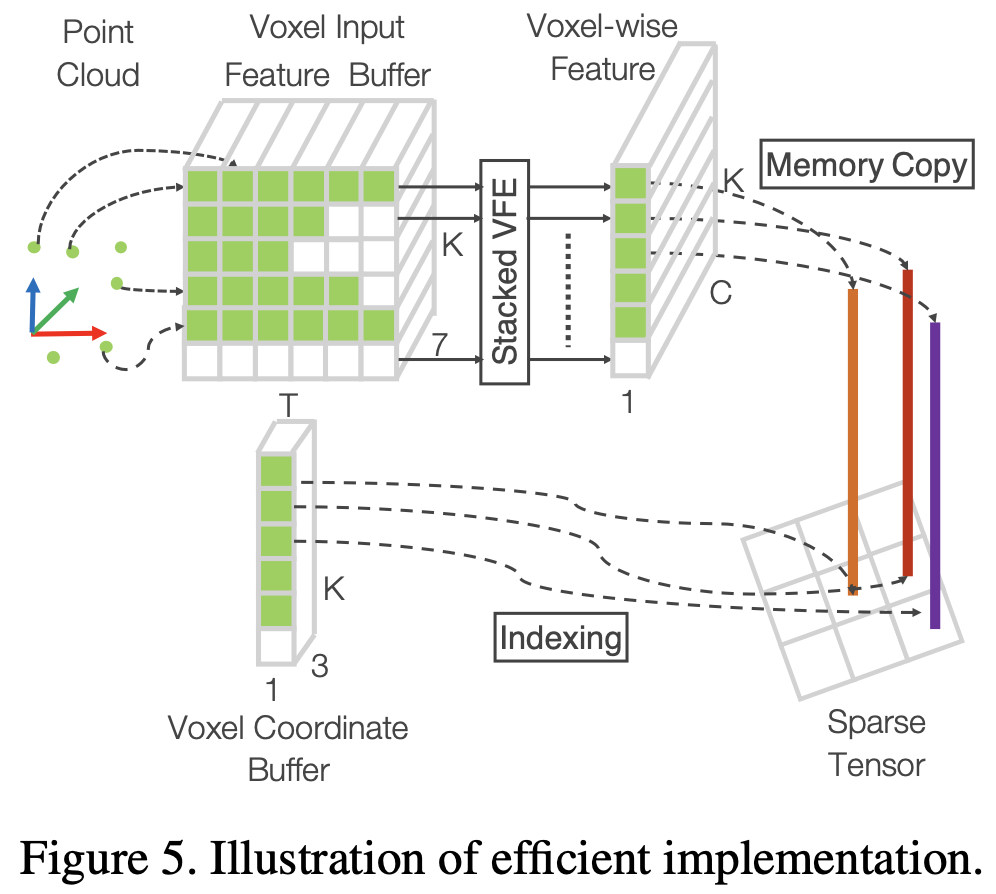 构建体素输入缓冲区后,堆叠的VFE仅涉及点级和体素级密集操作,可以在GPU上并行计算。请注意,在VFE中串联操作后,我们将与空点相对应的特征重置为零,这样它们就不会影响计算的体素特征。最后,使用存储坐标缓冲区,我们将计算的稀疏体素结构重组为密集的体素网格。接下来的卷积中间层和RPN操作在密集的体素网格上工作,可以在GPU上高效实现。
构建体素输入缓冲区后,堆叠的VFE仅涉及点级和体素级密集操作,可以在GPU上并行计算。请注意,在VFE中串联操作后,我们将与空点相对应的特征重置为零,这样它们就不会影响计算的体素特征。最后,使用存储坐标缓冲区,我们将计算的稀疏体素结构重组为密集的体素网格。接下来的卷积中间层和RPN操作在密集的体素网格上工作,可以在GPU上高效实现。
Training Details
在本节中,我们将解释 VoxelNet 的实现细节和训练程序。
Network Details
我们的实验设置基于KITTI数据集[11]的激光雷达。
Car Detection 对于这项任务,我们分别考虑了沿着 Z、Y、X轴 [−3, 1] × [−40, 40] × [0, 70.4]米范围内的点云。投影在图像边界之外的点将被删除[5]。我们选择一个体素大小 $v_D = 0.4, v_H 0.2, v_W = 0.2$ 米, 其导致 $D’ = 10, H’ = 400, W’ = 352$。 我们将 $T = 35$ 设置为每个非空体素中随机采样点的最大数量。我们使用两个VFE层 VFE-1(7,32)和 VFE-2(32,128)。最后 FCN 映射 VFE-2 输出为 $R^{128}$。 因此,我们的特征学习网生成一个形状为 $128 \times 10 \times 400 \times 352$ 的稀疏张量。为了聚合体素特征,我们依次使用三个卷积中间层,分别是 Conv3D(128, 64, 3, (2,1,1), (1, 1,1)), Conv3D(64, 64, 3, 3、(1, 1, 1), (0, 1, 1)), 和Conv3D(64, 64, 64, 3、3, (2, 1, 1), (1, 1, 1)) 等三个卷积中间层,其产生一个尺寸为 $64 \times 2 \times 400 \times 352$ 的4D张量。重塑后,RPN的输入是尺寸为 $128 \times 400 \times 352$ 的特征图,其中尺寸对应于3D张量的通道、高度和宽度。图4说明了这项任务的详细网络架构。与[5]不同,我们只使用一个先验框尺寸,$l^a = 3.9,w^a = 1.6,h^a = 1.56$ 米,以 $z_c^a = −1.0$ 米为中心,两次旋转,0度和90度。我们的先验框匹配标准如下:如果先验框与真实边界框的交并比(IoU)最高,或者其与真实边界框的 IoU 高于0.6(在鸟瞰图中),则该先验框被认为是正的。如果先验框与所有真实边界框之间的IoU小于0.45,则该先验框被视为负。对于0.45 ≤ IoU ≤ 0.6的先验框将被忽略掉。我们在等式2中设置了 $\alpha = 1.5,\beta = 1.2$。
Pedestrian and Cyclist Detection 沿着Z、Y、X轴,输入范围是[−3, 1] × [−20, 20] × [0, 48]米。我们使用与汽车检测相同的体素尺寸,为 $D=10,H=200,W=240$。我们设置 $T=45$,以获得更多的激光雷达点,更好地捕获形状信息。特征学习网络和卷积中间层与汽车检测任务中使用的网络相同。对于RPN,我们通过将第一个2D卷积中的步长大小从2更改为1,对图4中的块1进行了一次修改。这允许在先验框匹配中实现更精细的分辨率,这是检测行人和非机动车所必需的。我们使用先验框大小 $l^a = 0.8, w^a = 0.6, h^a = 1.73$ 米以 $z_c^a = -0.6$ 旋转角 0 和 90 度用于行人检测,使用先验框大小 $l^a = 1.76, w^a = 0.6, h^a = 1.73$米以 $z_c^a = -0.6$ 旋转角 0 和 90度用于非机动车检测。匹配的特定先验框准则如下:如果先验框和真值具有最高的IoU,或者其与真值的IoU高于0.5,我们会将其指定为正先验框。 如果先验框与每个真实变借款的IoU小于0.35,则该先验框被视为负值。忽视掉与真值 0.35 ≤ IoU ≤ 0.5 的先验框。
在训练期间,我们在前150个 epoch 使用学习率为0.01的随机梯度下降(SGD),在最后 10 个 epoch 将学习率降至0.001。我们使用批大小为16的点云。
Data Augmentation
Experiments
我们在KITTI 3D目标检测基准[11]上评估了VoxelNet,该基准包含7,481个训练图像/点云和7,518个测试图像/点云,涵盖三个类别:汽车、行人和非机动车。
对于每个类,检测结果根据三个难度级别进行评估:简单、中等和困难,这些难度级别根据目标大小、遮挡状态和截断水平确定。由于测试集的标签不可用,并且对测试服务器的访问有限,我们使用[4、3、5]中描述的协议进行全面评估,并将训练数据细分为训练集和验证集,从而生成3,712个用于训练的数据样本和3,769个数据样本进行验证。拆分避免了训练和验证集[3]中包含相同序列的样本。最后,我们还使用KITTI服务器介绍了测试结果。
对于汽车类别,作者将该方法与几种性能最好的算法进行了比较,包括基于图像的方法:Mono3D和3DOP;基于激光雷达的方法:VeloFCN和3D-FCN;以及多模态方法MV。Mono3D、3DOP和MV使用预训练的模型进行初始化,而作者仅使用KITTI中提供的激光雷达数据从头开始训练VoxelNet。
为了分析端到端学习的重要性,作者实现了来自VoxelNet架构的强大基线,但使用手工制作的特征,而不是提议的特征学习网络。我们称这个模型为手工制作的基线(HC基线)。HC基线使用[5]中描述的鸟瞰图特征,这些特征以0.1米分辨率计算。与[5]不同,作者将高度通道的数量从4增加到16个,以捕获更详细的形状信息——进一步增加高度通道的数量并不能提高性能。作者将VoxelNet的卷积中间层替换为类似大小的2D卷积层,即Conv2D(16、32、3、1、1)、Conv2D(32、64、3、2、1)、Conv2D(64、128、3、1、1)。最后,RPN在VoxelNet和HC基线中是相同的。HC基线和VoxelNet中的参数总数非常相似。作者使用第3节中描述的相同训练程序和数据增强来训练HC基线。
Evaluation on KITTI Validation Set
Metrics 作者遵循官方的KITTI评估协议,其中汽车类的IoU阈值为0.7,行人和非机动车的 IoU 阈值为0.5。鸟瞰图和完整3D评估的IoU阈值都是相同的。作者使用平均精度(AP)度量来比较方法。
Evaluation in Bird’s Eye View 评估结果见表1。VoxelNet在所有三个难度级别的表现一直优于所有竞争方法。HC基线还实现了与最先进的[5]相当的令人满意的性能,这表明基础区域提议网络(RPN)是有效的。对于鸟瞰图中的行人和非机动车检测任务,作者将拟议的VoxelNet与HC基线进行了比较。对于这些更具挑战性的类别,VoxelNet的AP比HC基线高得多,这表明端到端学习对于基于点云的检测至关重要。
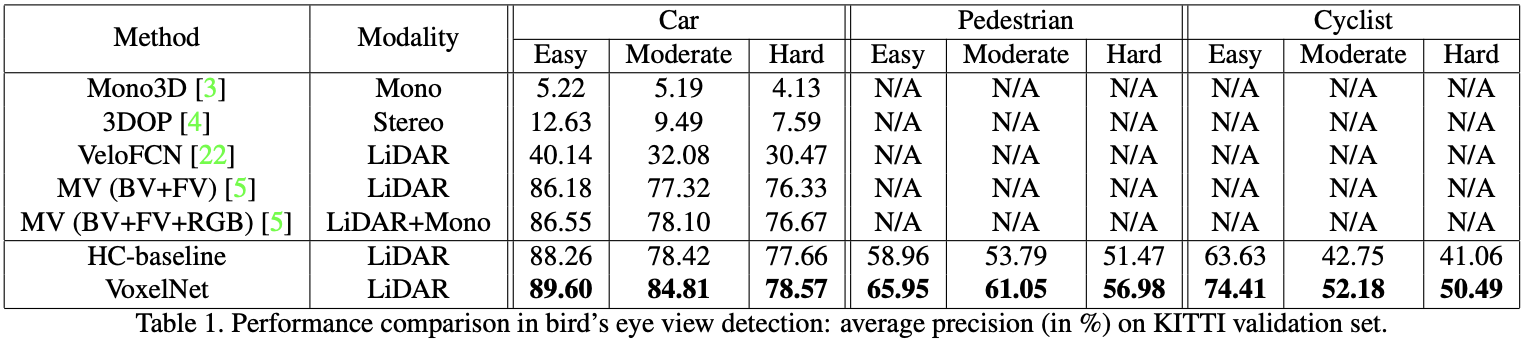 作者想指出,[21]分别报告了容易、中等和困难水平的88.9%、77.3%和72.7%,但这些结果是根据6000个训练帧和约1500个验证帧的划分得出的,它们与表1中的算法没有直接比较。因此,作者没有将这些结果包含在表格中。
作者想指出,[21]分别报告了容易、中等和困难水平的88.9%、77.3%和72.7%,但这些结果是根据6000个训练帧和约1500个验证帧的划分得出的,它们与表1中的算法没有直接比较。因此,作者没有将这些结果包含在表格中。
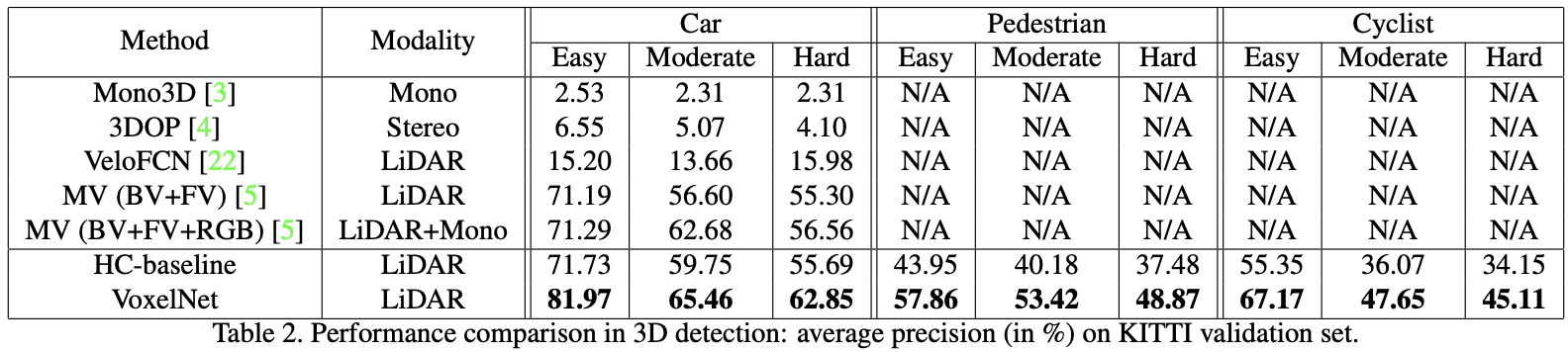
Evaluation in 3D 与鸟瞰图检测(只需要准确定位二维平面上的物体)相比,3D检测是一项更具挑战性的任务,因为它需要在3D空间中对形状进行更精细的定位。表2总结了比较。对于Car类,VoxelNet在所有难度级别上的表现都明显优于所有其他方法。具体来说,仅使用激光雷达,VoxelNet在简单, 中等和困难级别上分别优于基于激光雷达+RGB的最新方法MV(BV+FV+RGB),分别优于10.68%、2.78%和6.29%。HC基线的精度与MV [5]方法相似。
与鸟瞰图评估一样,作者还比较了VoxelNet与3D行人和非机动车检测的HC基线。由于3D位姿和形状差异很大,成功检测这两个类别需要更好的3D形状表示。如表2所示,VoxelNet的改进性能被强调为更具挑战性的3D检测任务(从鸟瞰图改善约8%到3D检测改善约12%),这表明VoxelNet在捕获3D形状信息方面比手工制作的特征更有效。
Conclusion
基于激光雷达的大多数现有3D检测方法都依赖于手工制作的特征表示,例如鸟瞰投影。
这篇文章消除了手动特征工程的瓶颈,并提出了VoxelNet,这是一种用于新的基于点云的端到端可训练3D检测架构。
该方法可以直接在稀疏的3D点上操作,并有效地捕获3D形状信息。
这篇文章还介绍了VoxelNet的有效应用,它受益于点云稀疏性和体素网格上的并行处理。
作者对KITTI汽车检测任务的实验表明,VoxelNet以很大的优势形成了最先进的基于激光雷达的3D检测方法。
在更具挑战性的任务上,例如对行人和非机动车进行3D检测,VoxelNet还提出了令人鼓舞的结果,表明它提供了更好的3D表征。
未来的工作包括为联合激光雷达和基于图像的端到端3D检测扩展VoxelNet,以进一步提高检测和定位精度。
-
Previous
【深度学习】Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite -
Next
【深度学习】Score-baed Diffusion:Score-Based Generative Moddling Through Stochastic Differential Equations