Abstract
基于激光雷达或基于RGB-D的目标检测用于许多应用,从自动驾驶到机器人视觉。
基于Voxel的3D卷积网络已经使用了一段时间,以提高处理点云激光雷达数据时的信息保留率。
然而,问题仍然存在,包括推理速度缓慢和方向估计性能低。
因此,作者研究了一种改进的此类网络稀疏卷积方法,该方法显著提高了训练和推理的速度。
作者还引入了一种新形式的角度损失回归,以提高定向估计性能,以及一种可以提高收敛速度和性能的新数据增强方法。
所提出的网络在 KITTI 3D目标检测基准上产生了最先进的结果,同时保持了快速的推理速度。
SECOND Detector
在本节中,作者描述了所提出的 SECOND 检测器的架构,并介绍了有关训练和推断的相关细节。
Network Architecture
如图1所示,所提出的 SECOND 检测器由三个部分组成:(1)体素级别特征提取器;(2)稀疏的卷积中间层;以及(3)RPN。
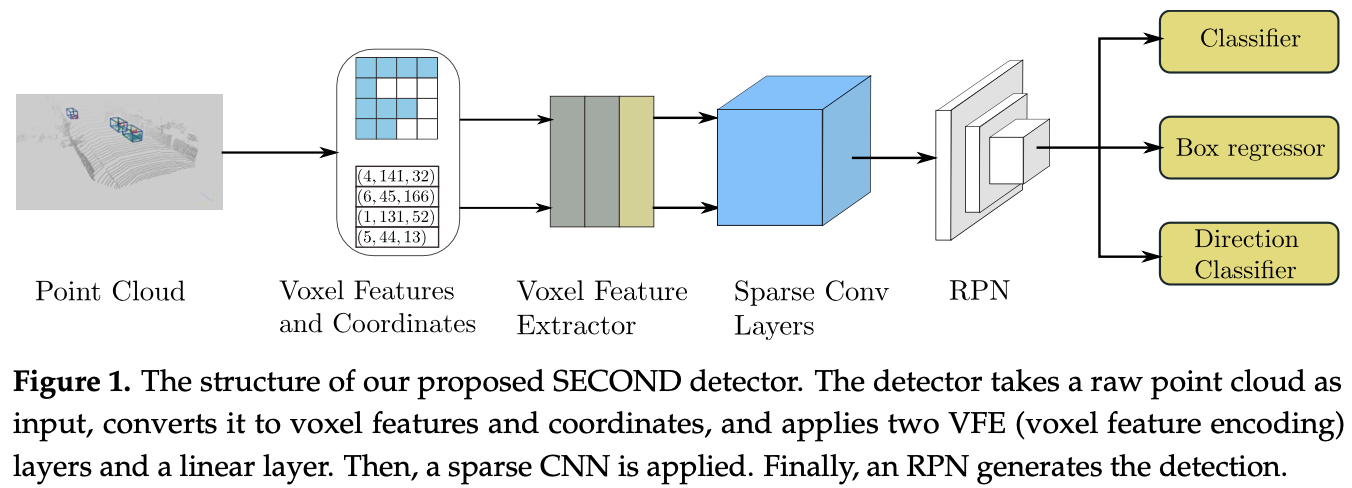
Point Cloud Grouping
在这里,作者遵循[14]中描述的简单程序来获得点云数据的体素表征。我们首先根据对体素数量限制预先分配缓冲区;然后,在点云上迭代,并将点分配给它们关联的体素,然后保存体素坐标和每个体素的点数。在迭代过程中,根据哈希表检查体素的存在。如果与某个点相关的体素尚不存在,我们会在哈希表中设置相应的值;否则,我们会将体素的点数增加一。一旦体素数量达到指定限制,迭代过程将停止。最后,我们得到了所有体素,它们的坐标和每个体素实际数量的点数。为了检测相关类别中的汽车和其他物体,我们根据沿 $z \times y \times x$ 轴在 [−3, 1] × [−40, 40] × [0, 70.4] 米处的真值分布来裁剪点云。对于行人被非机动车检测,我们使用 [−3, 1] × [−20, 20] × [0, 48] 米的点裁剪。对于我们较小的模型,我们只使用 [−3, 1] × [−32, 32] × [0, 52.8] 米范围内的点来提高推理速度。裁剪区域需要根据体素大小进行略微调整,以确保生成的特征图的大小可以在后续网络中正确下采样。对于所有任务,我们使用 $v_D = 0.4 \times v_H = 0.2 \times v_W = 0.2 m$的体素大小。每个用于汽车检测的空体素的最大点数设置为T = 35,这是根据KITTI数据集中每个体素点数的分布选择的;行人和非机动车检测的相应最大值设置为T = 45,因为行人和非机动车相对较小,因此需要更多的点来提取体素特征。
Voxelwise Feature Extractor
如[14]所述,我们使用体素特征编码(VFE)层来提取体素特征。VFE层将同一体素中的所有点作为输入,并使用由线性层、批处理规范化(BatchNorm)层和ReLU层组成的全连接网络(FCN)来提取逐点特征。然后,它使用元素最大池来获得每个体素的局部聚合特征。最后,它将获得的特征拼接在一起,并将这些特征和逐点特征连接在一起。我们使用 $VFE(c_{out})$ 表示一个 VFE 层, 其将输入特征变换为 $c_{out}$ 维度的输出特征。相似的, $FCN(c_{out})$ 表示一个 Linear-BatchNorm-ReLU 层, 其将输入特征转换为 $c_{out}$ 维输出特征。总体而言,voxelwise特征提取器由几个VFE层和一个FCN层组成。
Sparse Convolutional Middle Extractor
Review of Sparse Convolutional Networks
参考文献[25]是第一篇引入空间稀疏卷积的论文。在这种方法中,如果没有相关的输入点,则不会计算输出点。这种方法在基于激光雷达的检测中提供了计算优势,因为KITTI中点云的分组步骤将产生稀疏度接近0.005的5k-8k体素。作为正常稀疏卷积的替代方案,子流形卷积[27]限制当且仅当相应的输入位置处于激活状态, 输出位置为激活状态。这避免了产生太多的激活位置,其可能导致由于激活点数量众多而导致后续卷积层的速度下降。
Sparse Convolution Algorithm
让我们首先考虑二维稠密卷积算法。我们使用 $W_{u,v,l,m}$ 表示卷积核元素,$D_{u,v,l}$表示图像元素,其中 $u$ 和 $v$ 是空间位置索引,$l$ 表示输入通道,$m$ 表示输出通道。给定提供的输出位置, 函数 $P(x,y)$ 生成需要计算的输入位置。因此,$Y_{x,y,m}$ 的卷积输出由以下公式给出:
Sparse Convolutional Middle Extractor
Region Proposal Network
Anchors and Targets
Training and Inference
Loss
Sine-Error Loss for Angle Regression
Focal Loss for Classification
Data Augmentation
Sample Ground Truths from the Database
Object Noise
Global Rotation and Scaling
Optimization
Network Details
-
Previous
【深度学习】Score-baed Diffusion:Score-Based Generative Moddling Through Stochastic Differential Equations -
Next
【深度学习】PointPillars: Fast Encoders for Object Detection from Point Clouds