Abstract
Multi-query attention(MQA)仅使用单个 key-value head,大大加快了解码器推理。
然而,MQA可能导致质量下降,此外,仅仅为了更快的推理而训练一个单独的模型可能不是可取的。
我们提出了一种方法,可以使用原始预训练计算的5%将现有的多头语言模型 checkpoint 升级为具有MQA的模型,并引入了 grouped-query attention(GQA),这是多查询注意力的一种泛化,它使用中间(多于一个,少于 query heads 数)数量的 key-value heads。
我们表明,经过训练的GQA以与MQA相当的速度实现了接近多头注意力的质量。
Introduction
由于加载解码器权重以及每个解码步骤的所有注意力键和值的内存带宽开销,自回归解码器推理对 Transformer 模型来说是一个严重的瓶颈。通过多查询关注,加载键和值的内存带宽可以大幅减少,该注意力使用多个查询头,但单个键和值头。
然而,多查询关注(MQA)可能导致质量下降和训练不稳定,训练针对质量和推理优化的单独模型可能不可行。此外,虽然一些语言模型已经使用多查询注意力,如PaLM(Chowdhery等人,2022年),但许多没有,包括公开可用的语言模型,如T5(Raffel等人,2020年)和LLaMA(Touvron等人,2023年)。
这项工作包含两个方面,旨在加速大型语言模型的推理。首先,我们展示了具有多头注意力(MHA)的语言模型 checkpoint 可以使用原始训练计算的一小部分进行升级,以使用MQA(Komatsuzaki等人,2022)。这为获得快速多查询以及高质量的MHA checkpoint 提供了一种具有成本效益的方法。
第二,我们提出了分组查询注意力(GQA),它是多头注意力和多查询注意力之间的插值,每个查询头子组只有一个键和值头。我们展示了经过升级的GQA在质量上接近多头注意力,同时几乎与多查询注意力一样快。
Method
Uptraining
从多头模型生成多查询模型分为两个步骤:第一步是转换 checkpoint,第二步是额外的预训练,以使模型适应其新结构。图1显示了将多头检查点转换为多查询检查点的过程。键和值头的投影矩阵被平均池化成单个投影矩阵,我们发现这比选择单个键和值头或从头开始随机初始化新的键和值头更有效。
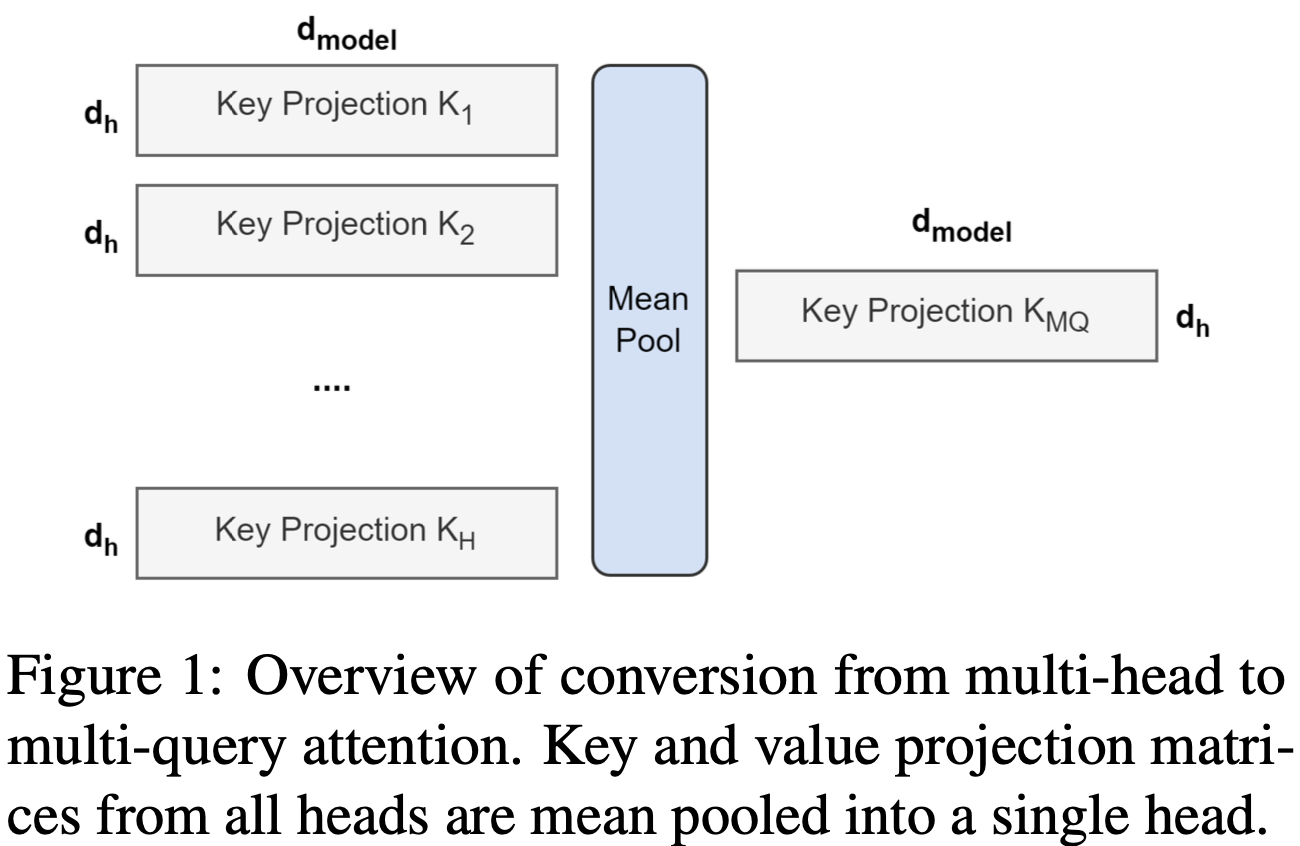
转换后的 checkpoint 会在同一个预训练配方上进行原始训练步骤的一小部分 $\alpha$ 的预训练。
Grouped-query attention
分组查询注意力将查询头分成 G 组,每组共享一个键头和值头。GQA-G 指的是具有 G 组的分组查询。GQA-1,具有单个组,因此单个键和值头,相当于MQA,而GQA-H,组数等于头数,相当于MHA。图2显示了分组查询注意力和多头/多查询注意力的比较。将多头检查点转换为GQA检查点时,我们通过平均汇集该组内的所有原始头来构建每个组键和值头。1
-
Previous
【深度学习】基于 LLM 构建中文场景检索式对话:Llama2+NeMo -
Next
【CVPR 2023】Burstormer: Burst Image Restoration and Enhancement Transformer