Abstract
基于校准的方法在极低光环境下主导了RAW图像降噪。
然而,这些方法存在几个主要不足之处:
1)校准过程繁琐且耗时
2)不同相机的降噪器难以转移
3)高数字增益扩大了合成噪声与真实噪声之间的差异。
为了克服以上缺点,我们提出了一种无需校准的 Lighting Every Darkness(LED)Pipeline,不受数字增益或相机传感器的限制。
与反复校准噪声参数并进行训练不同,我们的方法只需少量配对数据和微调即可适应目标相机。
此外,在两个阶段都经过精心设计的结构修改减轻了合成和真实噪声之间的领域差距,而无需额外的计算成本。
通过每个额外数字增益(总共6对)和0.5%的迭代,我们的方法在性能上优于其他基于校准的方法。
Introduction
噪声是图像捕获中一个不可避免的话题,近年来已经进行了系统的研究。与标准的RGB图像相比,RAW图像在图像降噪方面具有两个巨大的潜力:可处理的原始噪声分布和更高的位深度,以区分信号和噪声。基于学习的方法在使用配对的真实数据集进行RAW图像降噪方面取得了显著进展。然而,为每个单独的相机型号收集大规模真实的RAW图像数据集是不可行的。因此,越来越多的关注点被转向在合成数据集上部署基于学习的方法。
基于校准的噪声合成通过基于物理的模型在拟合真实噪声方面证明了其有效性。总体而言,这些方法执行以下步骤。首先,它们基于 electronic imaging pipeline 构建一个经过精心设计的噪声模型。然后,它们选择特定目标相机,并仔细校准预定义噪声模型的参数。最后,它们生成用于训练去噪网络的合成配对数据。此外,一些方法借助基于深度神经网络(DNN)的生成模型进行噪声参数校准。
尽管已经取得了出色的性能,但这些方法存在三个主要不足之处,如图2(a)所示。
1)专门进行校准的数据收集需要稳定的照明环境和精心设计的后期处理,导致一个耗时且劳动密集的过程。
2)为特定相机训练的降噪网络难以转移到另一台相机。这导致网络与相机之间存在强烈的关联,需要针对不同目标相机进行重复校准和训练。
3)某些噪声分布可能未包含在噪声模型中,被称为模型之外的噪声。换句话说,合成噪声(SN)和真实噪声(RN)之间的域差异仍然存在。
尽管最近的研究主要集中在通过基于深度神经网络的校准来缓解校准成本,但耦合问题和模型之外的噪声仍然增加了训练开销并限制了它们的性能。
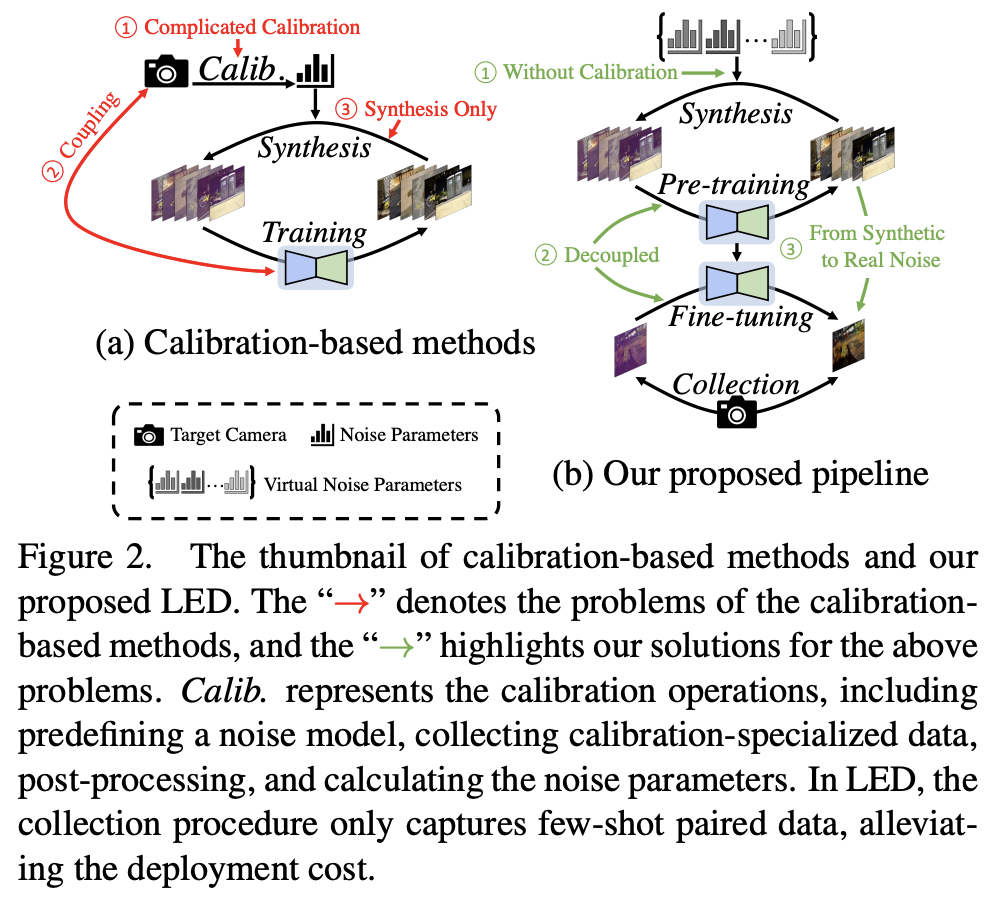
为了解决基于校准的方法中的上述三个问题,我们提出了一个 calibration-free pipeline for lighting every darkness (LED).(LED)。
如图2(b)所示,我们的框架不需要进行任何校准的数据或操作。此外,为了解耦降噪网络与特定目标相机之间的强烈关联,我们提出了一个预训练和微调的框架。对于虚拟相机与目标相机之间的差距,以及模型之外的噪声的影响,我们提出了一个重新参数化噪声去除(RepNR)模块。在预训练期间,RepNR模块配备了多个 camera-specific alignments(CSA)。每个CSA负责学习虚拟相机的相机特定信息并将特征对齐到共享空间。然后,通过去噪卷积学习噪声模型中被假定为噪声模型一部分的在模型内(已被假定为噪声模型一部分的组件)的共同知识。在微调中,我们将虚拟相机的所有CSA平均作为目标相机的初始化。此外,为了处理 out-of-model noise removal(OMNR),我们添加了一个并行卷积分支。仅使用目标相机捕获的每个比例(附加数字增益)的2对图像,总共6对RAW图像,用于学习去除其真实噪声(有关为什么每个比例使用2对图像的讨论可以在第5节找到)。在部署期间,所有RepNR模块可以在不增加任何额外计算成本的情况下被结构重新参数化为简单的3×3卷积,生成一个普通的UNet。
我们的主要贡献总结如下:
- 我们提出了一个calibration-free pipeline,用于 lighting every darkness,避免了对噪声参数进行校准的所有额外成本。
- 设计的CSA放松了去噪网络与相机模型之间的耦合,而OMNR通过学习不同传感器的模型之外的噪声,实现了小样本的迁移。
- 与现有方法相比,仅需要每个比例2对RAW图像和0.5%的迭代次数。
-
Previous
【TPAMI 2023】PIDS:Prior Image Guided Snapshot Compressive Spectral Imaging -
Next
【ECCV 2022】FECNet:Deep Fourier-based Exposure Correction Network with Spatial-Frequency Interaction