On this page
Abstract
第一点, 生成式预训练语言模型, 然后在每个特定任务上判别性微调 有很大收益。
在微调期间, 在最小改变模型结构的情况下, 利用task-aware的输入实现有效的迁移学习。
Introduction
标注数据是非常费时间的, 因此使用未标注的数据是非常有价值的。
即便有可观的监督数据可用,以一种无监督的方式学习表征可以提供显著的性能提升。一个例子就是预训练词向量对NLP任务的提升。
从未标注的文本中学习不仅仅是词级别的表征主要有两大难点。
- 不清楚学习用于迁移的表征时, 哪种优化目标最有效
- 将这些学习到的表征迁移到目标任务哪种方式最有效没有达成一致
本文使用结合无监督预训练和监督微调探索了一种用于语言理解任务半监督方式。首先,我们使用在未标记数据上使用语言模型目标学习神经网络模型的初始化参数。然后 我们采用这些参数到使用监督目标的目标任务上。
模型的结构使用 Transformer。 在迁移时,将结构化的输入处理为一个 task-specific 连续的自适应输入的序列。
Related Work
Semi-supervised learning for NLP 先进行无监督的预训练, 再进行监督的训练是一种半监督训练。 比如词向量的预训练, 但是这些方法主要迁移词级别的信息, 而我们想要捕获更高级别的语义。
Unsupervised pre-training 一些方法使用来自于预训练的语言模型或者机器翻译模型中的隐表征作为在目标任务上训练一个监督模型的辅助特征。这种方法会给下游任务带来更多地参数, 而我们的方法仅对下游任务进行最小的更改。
Auxiliary training objectives 增加辅助的无监督训练目标是半监督学习的另一种形式。
Framework
Unsupervised pre-training
在实验中使用多层的Transformer的decoder用以语言模型, 它是transformer的一种变体。
Supervised fine-tuning
将语言建模作为微调时一个辅助目标有以下帮助:
- 帮助提升监督模型的泛化性。
- 提升收敛速度。
Task-specific input transformations
针对不同的下游任务, 对模型只需做出最小的更改。
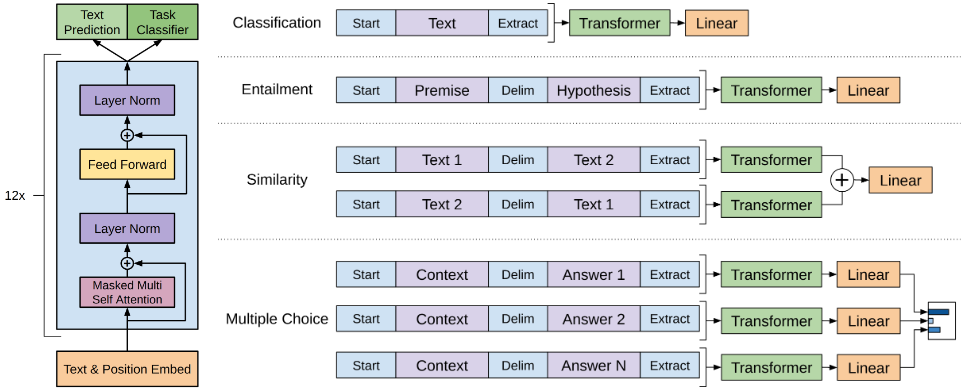
Textual entailment 对于 Textual entailment 任务, 拼接 premise $p$ 和 hypothesis $h$ token 序列, 在他们之间使用 token $分隔。
Similarity: 对于 Similarity 任务, 因为两句话没有天然的先后顺序之分, 因此将输入改为包含两种可能性的情况分别处理, 产生两个序列表征相加在送入线性输出层。
Question Answering and Commosense Reasoning 将document context 、question和可能的answer拼接, 使用分隔符 token 分割, [z; q; $; a_k]。 每个序列分别处理, 最后通过一个softmax层规范化产生对所有答案可能的输出分布。