On this page
Abstract
提出了一种叫做Inception的深度卷积神经网络结构, 在ILSVRC14中用于分类和检测。
网络结构的特点是提升了网络内部计算资源的利用率。
保持计算预算为常量, 增加网络的深度和宽度。
为了提升质量,使用了两种方法:Hebbian principle和多尺度处理。
Introduction
GoogLeNet使用比两年前的网络少于12倍的参数量,取得了显著提升的准确率。
目标检测的最大收益不仅来自更大模型或更深模型的使用,还有深度结构和传统计算机视觉的协同, 比如R-CNN。
在测试时,将计算预算设置为150万次乘和加的操作。
这篇文章专注于深度神经网络在计算机视觉中网络结构的效率, 叫做Inception, 它的名字来自Network in Network这篇文章。
deep有两种不同的含义:
- 引入一种Inception模块
- 增加网络深度
这种结构在ILSVRC2014分类和检测挑战上得到验证, 它显著提升了SOTA的表现。
Ralated Work
受到视觉皮层的神经科学模型的启发, 使用不同大小的滤波器来处理不同的尺度, 与Inception模型相似。
与两层固定的深度模型不同, Inception中所有的滤波器都是学习得到的。
Inception层重复多次, 产生了22层深的GoogLeNet模型。
Network in Network在卷积神经网络中可以看做1x1卷积层后跟着ReLU激活, 这使得它在CNN pipeline中非常容易集成进去。
1x1卷积有两个目的:
- 作为维度减少的模块
- 移除计算瓶颈, 计算瓶颈会限制网络的大小
这使得在没有显著地性能惩罚的情况下, 不仅增加深度, 还可以增加宽度。
现在流行的物体检测方式是R-CNN, 它将整个检测问题分解为两个子问题:
- 首先使用低级线索检测不关注类别的提议位置
- 再使用CNN分类器在这些位置识别物体种类
他们在物体检测上的这两个阶段作了一些增强, 比如在bounding box回归时的multi-box预测
Motivation and High Level Considerations
增加网络的深度和增加网络的宽度是最简单和安全的方式提升模型质量, 尤其是在有大量标注训练数据的情况下。
但是这种简单的方案有两个主要的缺点:
- 更大的尺寸意味着更大数量的参数, 它使得网络更加容易过拟合, 尤其当训练集有限的时候。
- 另外一个缺点是会显著增加计算资源的使用。如果两个卷积网络链起来, 均匀增加的卷积核数量都会导致计算量平方增加。如果大部分权重最后接近0, 那么大量的计算资源被浪费。
解决这两个问题的方法是将全连接变成稀疏连接的结构。模仿生物系统, 如果数据集的概率分布可以由一个大的,非常稀疏的深度神经网络表示, 则可以通过分析最后一层的激活的相关统计量,逐层构建最佳网络拓扑。 聚集具有高度相关输出的神经元。
Architectural Details
我们需要找出最优的局部结构, 然后在空间上重复它。
一层接一层的构造方法, 分析最后一层的相关统计量, 并将其聚类为具有高相关性的单元组:
- 这些聚类组成下一层的单元并且由上一层的的单元连接。
- 我们假设来自较早层的每个单元对应于输入图像的某些区域, 并且这些单元被分组为滤波器组。
- 在较低的层(靠近输入层), 相关单元关注局部区域。
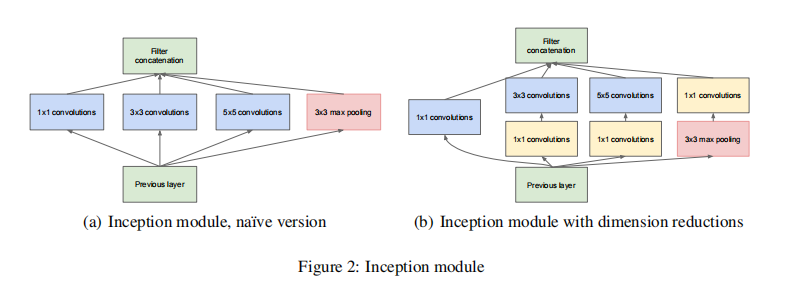
为了避免patch对齐的问题, Inception结构的前身限制卷积核大小为1x1, 3x3和5x5, 这种决策不是必要的, 而是为了方便。
这意味着所有这些层的输出滤波器组拼接成一个单个输出向量形成下一阶段的输入。
池化操作对SOTA卷积神经网络的成功是必要的, 这意味着在每个阶段添加一个池化可以带来额外好的影响。
由于Inception模块互相在顶部叠加, 它们的输出相关统计数据不同。 高层捕获更抽象的特征, 它们的空间关注应该减小, 因此当我们到更高层时, 3x3和5x5卷积的比例应该减小。
一个大问题, 即便是适中数量的5x5卷积在卷积层的顶层也是非常昂贵的, 这个问题在池化单元加入后更加严重, 它们输出滤波器的数量等于前一阶段滤波器的数量:
- 池化层的输出和卷积层的输出融合之后将会导致不可避免地增加阶段到阶段的输出的数量。
- 即使这个结构可能包含了最优的稀疏结构, 它还是可能是低效的, 导致在一些阶段计算爆炸。
体系结构的第二个想法
- 计算需要增加太多的时候使用降维和投影。它是基于embedding的成功思想: 即便是低维的embedding也可能包含了相对更大patch的大量信息。
- embeddings以密集、压缩的形式表示信息, 而压缩信息到模型更难。
- 我们想要在大多数地方保持我们的表示稀疏, 并且仅在必须将它们汇总时才压缩信号。在昂贵的3x3和5x5卷积核之前使用1x1卷积计算降维。除了降维外, 通过激活增加了非线性。
通常Inception网络有各个Inception模块堆叠而成, 偶尔会有步长为2的最大池化层减半分辨率。
出于训练时的显存效率, 在高层使用Inception模块, 在低层使用传统卷积。
这个结构的一个主要的好处是它可以显著增加每个阶段的单元数, 而不会导致计算复杂性急剧增加:
- 维度减少使得最后一级的大量输入滤波器屏蔽到下一层, 在用更大的patch大小卷积之前首先减小它们的维度。
- 视觉信息应该在不同尺度处理,然后集合在一起以便于下一阶段能够同时从不同尺度抽象特征。
GoogLeNet
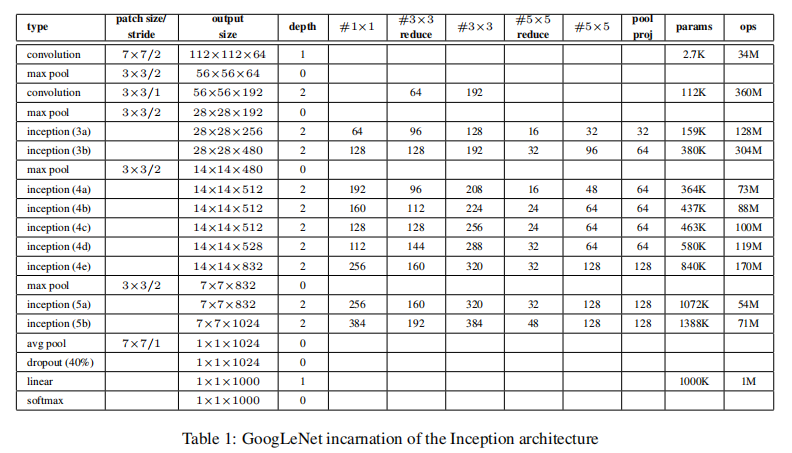
所有的卷积,包括Inception模块, 使用ReLU激活。
在我们的网络中,感受野的尺寸是224x224, RGB色彩通道减去均值。
“#3x3 reduce” 和 “#5x5 reduce” 表示 表示在3x3和5x5卷积之前使用的1x1滤波器数量。
在pool proj可以看到在build-in max-pooling之后投影层的1x1的滤波器数量。
在这个任务上相对浅层网络的强大表现表明 由中间层产生的特征非常具有判别性。
通过在中间层添加一个辅助分类器, 我们希望在分类的较低阶段鼓励判别, 增加反向传播的梯度, 以及提供额外的正则化。
这些分类器采用更小的卷积网络的形式在Inception(ra)和Inception(4d)模块的输出顶层。
在训练阶段, 它们的loss乘以一个折扣权重加到总loss上(权重为0.3), 预测阶段,抛弃辅助网络。
在边上的额外网络的结构, 包括辅助分类器, 如下:
- 一个5x5滤波器大小, 步长为3的平均池化层, 产生在(4a)阶段产生一个4x4x512输出, 在(4d)阶段产生一个4x4x528输出。
- 128个滤波器的1x1卷积用于降维和ReLU激活。
- 一个全连接层带有1024个单元并且使用ReLU激活。
- 0.7的比率dropout
- 一个带有softmax损失的线性层作为分类器(和主分类器一样预测1000类, 但是在推理时删除)