On this page
Image Classification
既然您已经了解了什么是深度学习,它是为了什么,以及如何创建和部署模型,那么我们是时候深入研究了!在一个理想的世界里,深度学习的实践者不必知道引擎下事物如何运作的每个细节……但到目前为止,我们还没有生活在一个理想的世界里。事实是,为了让您的模型真正有效,并可靠地工作,您必须正确处理许多细节,以及许多细节,您必须检查。这个过程需要能够在神经网络训练时查看神经网络内部,并在预测时发现可能的问题,并知道如何解决这些问题。
因此,从现在开始,我们将深入研究深度学习的机制。计算机视觉模型、NLP模型、表格模型等的架构是什么?如何创建符合特定域需求的结构?您如何从训练过程中获得最佳结果?你如何让训练变快?随着数据集的变化,您必须更改什么?
我们将首先重复我们在第一章中看到的相同的基本应用程序,但我们将做两件事:
- 使它们更好
- 在更广泛的数据集上应用它们
为了完成这两件事,我们必须学习深度学习谜题的所有部分。这包括不同类型的图、正则化方法、优化器、如何将图组合到结构中、标签技术等。不过,我们不仅会把所有这些东西都教给你;我们会根据需要逐步介绍它们,以解决与我们正在进行的项目相关的实际问题。
From Dogs and Cats to Pet Breeds
在我们的第一个模型中,我们学会了如何对狗和猫进行分类。就在几年前,这被认为是一项非常具有挑战性的任务——但今天,这太容易了!我们将无法向您展示带有这个问题的训练模型的细微差别,因为我们在不担心任何细节的情况下获得了几乎完美的结果。但事实证明,相同的数据集也允许我们解决一个更具挑战性的问题:找出每张图像中显示的宠物品种。
在现实生活中,我们从一些我们一无所知的数据集开始。然后,我们必须弄清楚它是如何组合在一起的,如何从中提取我们需要的数据,以及这些数据是什么样子的。在这本书的其余部分,我们将向您展示如何在实践中解决这些问题,包括理解您正在处理的数据和边走边测试建模所需的所有中间步骤。
我们已经下载了宠物数据集,我们可以使用如下代码获取此数据集的路径:
from fastai.vision.all import *
path = untar_data(URLs.PETS)
现在,如果我们要了解如何从每张图像中提取每只宠物的品种,我们需要了解这些数据是如何布局的。这些数据布局的细节是深度学习谜题的重要组成部分。数据通常以以下两种方···式之一提供:
- 代表数据项的单个文件,如文本文档或图像,可能被组织成文件夹或带有代表这些项目信息的文件名
- 数据表,例如CSV格式的数据表,其中每行都是一个项目,其中可能包含文件名,该文件名在表中的数据和其他格式的数据(如文本文档和图像)之间提供连接
这些规则也有例外——特别是在基因组学等领域,那里可以有二进制数据库格式甚至网络流——但总的来说,您将使用的绝大多数数据集将使用这两种格式的某种组合。
要查看我们数据集中的内容,我们可以使用 ls 方法:
#hide
Path.BASE_PATH = path
path.ls()
> (#3) [Path('annotations'),Path('images'),Path('models')]
我们可以看到,此数据集为我们提供了图像和标注目录。数据集的网站告诉我们,标注目录包含关于宠物在哪里而不是它们是什么的信息。在这一章中,我们将进行分类,而不是定位,也就是说,我们关心的是宠物是什么,而不是它们在哪里。因此,我们现在将忽略标注目录。因此,让我们看看图像目录:
(path/"images").ls()
> (#7394) [Path('images/great_pyrenees_173.jpg'),Path('images/wheaten_terrier_46.jpg'),Path('images/Ragdoll_262.jpg'),Path('images/german_shorthaired_3.jpg'),Path('images/american_bulldog_196.jpg'),Path('images/boxer_188.jpg'),Path('images/staffordshire_bull_terrier_173.jpg'),Path('images/basset_hound_71.jpg'),Path('images/staffordshire_bull_terrier_37.jpg'),Path('images/yorkshire_terrier_18.jpg')...]
Fastai中返回集合的大多数函数和方法都使用名为 L 的类。L 可以被视为普通 Python list 类的增强版本,并为常见操作增加了便利。例如,当我们在笔记本中显示此类对象时,它会以其中显示的格式显示。显示的第一件事是集合中的项目数量,前缀为#。您还将在前面的输出中看到列表后缀为省略号。这意味着只显示前几个项目——这是件好事,因为我们不希望屏幕上超过7000个文件名!
通过检查这些文件名,我们可以看到它们的结构如何。每个文件名都包含宠物品种,然后是下划线(_)、数字,最后是文件扩展名。我们需要创建一个代码,从单个路径中提取品种。Jupyter Notebook 使这变得简单,因为我们可以逐步构建一些有效的东西,然后将其用于整个数据集。在这一点上,我们确实必须小心,不要做出太多假设。例如,如果您仔细查看,您可能会注意到一些宠物品种包含多个单词,因此我们不能简单地在找到的第一个_字符处断开。为了测试代码,让我们从这些文件名中挑选一个:
fname = (path/"images").ls()[0]
从此类字符串中提取信息的最强大和灵活的方法是使用 regular expression,也称为 regex。
在这种例子中,我们需要一个正则表达式,从文件名中提取宠物品种。
当您编写正则表达式时,最好的开始方式是首先根据一个示例进行尝试。让我们使用 finall 方法对 fname 对象的文件名尝试正则表达式:
re.findall(r'(.+)_\d+.jpg$', fname.name)
> ['great_pyrenees']
这个正则表达式会找出 最后一个下划线字符,子序列字符是数字,最后是JPEG文件扩展名的所有字符。
现在我们确认正则表达式适用于示例,让我们用它来标记整个数据集。fastai附带许多类来帮助标记。对于用正则表达式进行标记,我们可以使用 RegexLabeller 类。在本例中,我们使用 datablock API(事实上,我们几乎总是使用 datablock API——它比简单工厂方法灵活得多):
pets = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'),
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224, min_scale=0.75))
dls = pets.dataloaders(path/"images")
我们以前从未见过的 DataBlock 调用的一个重要部分是以下两行:
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224, min_scale=0.75)
这些代码实现了 fastai 数据增强策略,我们称之为 presizing。presizing 是进行图像增强的一种特殊方式,旨在最大限度地减少数据破坏,同时保持良好的性能。
Presizing
我们需要我们的图像具有相同的尺寸,以便它们可以整理成张量并传递给GPU。我们还希望最大限度地减少我们执行的不同增强计算的数量。性能要求表明,在可能的情况下,我们应该将增强转换合成为更少的转换(以减少计算次数和有损操作的数量),并将图像转换为统一大小(以便在GPU上更有效地处理)。
挑战在于,如果在调整大小调整到增强大小后执行,各种常见的数据增强转换可能会引入 spurious empty zones、degrade data或两者兼而有之。例如,将图像旋转45度会使新边界的角区域充满空,这不会教会模型任何东西。许多旋转和缩放操作需要插值才能创建像素。这些插值像素来自原始图像数据,但质量仍然较低。
为了应对这些挑战,presizing 采用了如下所示的两种策略:
- 将图像大小调整为相对“大”的维度——即显著大于目标训练维度的维度。
- 将所有常见的增强操作(包括调整大小为最终目标大小)组合成一个,并在处理结束时只在GPU上执行一次组合操作,而不是单独执行和多次插值操作。
第一步,调整大小,创建足够大的图像,使其具有备用余地,允许在不创建空区域的情况下进一步增强其内部区域的转换。这种转换通过使用大 crop size 调整到正方形来发挥作用。在训练集中,随机选择 crop 面积,并选择 crop 大小可以覆盖图像的整个宽度或高度,以较小者为准。

这张图片显示了两个步骤:
- 裁剪全宽度或高度:这是在
item_tfms中,因此在复制到GPU之前,它会应用于每个单独的图像。它用于确保所有图像大小相同。在训练集中,随机选择 crop 面积。在验证集上,总是选择图像的中心。 - 随机裁剪和增强:这是在
batch_tfms中,因此它在 GPU 上一次性应用于批处理,这意味着它速度很快。在验证集上,此处仅将大小调整为模型所需的最终大小。在训练集中,首先进行随机 crop 和任何所有增强。
要在 fastai 中实现此过程,请使用大尺寸 Resize 作为的 item transform,并使用 RandomResizeCrop 作为较小尺寸的批处理转换。如果您在 aug_transforms 函数中包含 min_scale 参数,将为您添加 RandomResizeCrop ,就像上一节中的 DataBlock 调用所做的那样。或者,对于初始 Resize,您可以使用 pad 或 squish 代替 crop(默认)。
下图显示右侧显示的缩放、插值、旋转然后再次插值的图像(这是所有其他深度学习库使用的方法)与左侧显示的缩放和旋转然后仅插值一次的图像(fastai方法)之间的区别。
#hide_input
#id interpolations
#caption A comparison of fastai's data augmentation strategy (left) and the traditional approach (right).
dblock1 = DataBlock(blocks=(ImageBlock(), CategoryBlock()),
get_y=parent_label,
item_tfms=Resize(460))
# Place an image in the 'images/grizzly.jpg' subfolder where this notebook is located before running this
dls1 = dblock1.dataloaders([(Path.cwd()/'images'/'grizzly.jpg')]*100, bs=8)
dls1.train.get_idxs = lambda: Inf.ones
x,y = dls1.valid.one_batch()
_,axs = subplots(1, 2)
x1 = TensorImage(x.clone())
x1 = x1.affine_coord(sz=224)
x1 = x1.rotate(draw=30, p=1.)
x1 = x1.zoom(draw=1.2, p=1.)
x1 = x1.warp(draw_x=-0.2, draw_y=0.2, p=1.)
tfms = setup_aug_tfms([Rotate(draw=30, p=1, size=224), Zoom(draw=1.2, p=1., size=224),
Warp(draw_x=-0.2, draw_y=0.2, p=1., size=224)])
x = Pipeline(tfms)(x)
#x.affine_coord(coord_tfm=coord_tfm, sz=size, mode=mode, pad_mode=pad_mode)
TensorImage(x[0]).show(ctx=axs[0])
TensorImage(x1[0]).show(ctx=axs[1]);

你可以看到右边的图像不清晰,左下角有reflection padding artifacts;此外,左上角的草已经完全消失了。我们发现,在实践中,使用 presizing 可以显著提高模型的准确性,而且速度更快。
Fastai库还提供了在训练模型之前检查数据看起来怎么样的简单方法,这是一个极其重要的步骤。我们接下来再看看它们。
Checking and Debugging a DataBlock
我们永远不能只是假设我们的代码运行良好。写 DataBlock 就像写蓝图一样。如果您在代码的某个地方出现语法错误,您将收到错误消息,但您无法保证您的模板将按您的意愿在您的数据源上工作。因此,在训练模型之前,您应该始终检查您的数据。您可以使用 show_batch 方法进行此操作:
dls.show_batch(nrows=1, ncols=3)

看看每张图片,看看每张图片是否都有该品种宠物的正确标签。通常,数据科学家处理他们可能不像领域专家那么熟悉的数据:例如,我实际上不知道这些宠物品种中有很多是什么。由于我不是宠物品种的专家,我现在会使用谷歌图像来搜索其中一些品种,并确保图像看起来与我在这个输出中看到的相似。
如果您在构建 DataBlock 时出错,您很可能在此步骤之前看不到它。要调试此内容,我们鼓励您使用 summary 方法。它将尝试从您给出的源头创建一个批处理,其中包含许多详细信息。此外,如果它失败了,您将确切地看到错误发生的时间,库将尝试为您提供一些帮助。例如,一个常见的错误是忘记使用 Resize 转换,因此您最终会看到不同大小的图片,并且无法批量处理它们。在这种情况下,summary 会是什么样子(请注意,确切的文本可能自编写本文以来发生了变化,但它会给你一个想法):
#hide_output
pets1 = DataBlock(blocks = (ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(seed=42),
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'))
pets1.summary(path/"images")
> Setting-up type transforms pipelines
Collecting items from /home/jhoward/.fastai/data/oxford-iiit-pet/images
Found 7390 items
2 datasets of sizes 5912,1478
Setting up Pipeline: PILBase.create
Setting up Pipeline: partial -> Categorize
Building one sample
Pipeline: PILBase.create
starting from
/home/jhoward/.fastai/data/oxford-iiit-pet/images/american_pit_bull_terrier_31.jpg
applying PILBase.create gives
PILImage mode=RGB size=500x414
Pipeline: partial -> Categorize
starting from
/home/jhoward/.fastai/data/oxford-iiit-pet/images/american_pit_bull_terrier_31.jpg
applying partial gives
american_pit_bull_terrier
applying Categorize gives
TensorCategory(13)
Final sample: (PILImage mode=RGB size=500x414, TensorCategory(13))
Setting up after_item: Pipeline: ToTensor
Setting up before_batch: Pipeline:
Setting up after_batch: Pipeline: IntToFloatTensor
Building one batch
Applying item_tfms to the first sample:
Pipeline: ToTensor
starting from
(PILImage mode=RGB size=500x414, TensorCategory(13))
applying ToTensor gives
(TensorImage of size 3x414x500, TensorCategory(13))
Adding the next 3 samples
No before_batch transform to apply
Collating items in a batch
Error! It's not possible to collate your items in a batch
Could not collate the 0-th members of your tuples because got the following shapes
torch.Size([3, 414, 500]),torch.Size([3, 375, 500]),torch.Size([3, 500, 281]),torch.Size([3, 203, 300])
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-11-8c0a3d421ca2> in <module>
4 splitter=RandomSplitter(seed=42),
5 get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'))
----> 6 pets1.summary(path/"images")
~/git/fastai/fastai/data/block.py in summary(self, source, bs, show_batch, **kwargs)
182 why = _find_fail_collate(s)
183 print("Make sure all parts of your samples are tensors of the same size" if why is None else why)
--> 184 raise e
185
186 if len([f for f in dls.train.after_batch.fs if f.name != 'noop'])!=0:
~/git/fastai/fastai/data/block.py in summary(self, source, bs, show_batch, **kwargs)
176 print("\nCollating items in a batch")
177 try:
--> 178 b = dls.train.create_batch(s)
179 b = retain_types(b, s[0] if is_listy(s) else s)
180 except Exception as e:
~/git/fastai/fastai/data/load.py in create_batch(self, b)
125 def retain(self, res, b): return retain_types(res, b[0] if is_listy(b) else b)
126 def create_item(self, s): return next(self.it) if s is None else self.dataset[s]
--> 127 def create_batch(self, b): return (fa_collate,fa_convert)[self.prebatched](b)
128 def do_batch(self, b): return self.retain(self.create_batch(self.before_batch(b)), b)
129 def to(self, device): self.device = device
~/git/fastai/fastai/data/load.py in fa_collate(t)
44 b = t[0]
45 return (default_collate(t) if isinstance(b, _collate_types)
---> 46 else type(t[0])([fa_collate(s) for s in zip(*t)]) if isinstance(b, Sequence)
47 else default_collate(t))
48
~/git/fastai/fastai/data/load.py in <listcomp>(.0)
44 b = t[0]
45 return (default_collate(t) if isinstance(b, _collate_types)
---> 46 else type(t[0])([fa_collate(s) for s in zip(*t)]) if isinstance(b, Sequence)
47 else default_collate(t))
48
~/git/fastai/fastai/data/load.py in fa_collate(t)
43 def fa_collate(t):
44 b = t[0]
---> 45 return (default_collate(t) if isinstance(b, _collate_types)
46 else type(t[0])([fa_collate(s) for s in zip(*t)]) if isinstance(b, Sequence)
47 else default_collate(t))
~/anaconda3/lib/python3.7/site-packages/torch/utils/data/_utils/collate.py in default_collate(batch)
53 storage = elem.storage()._new_shared(numel)
54 out = elem.new(storage)
---> 55 return torch.stack(batch, 0, out=out)
56 elif elem_type.__module__ == 'numpy' and elem_type.__name__ != 'str_' \
57 and elem_type.__name__ != 'string_':
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 414 and 375 in dimension 2 at /opt/conda/conda-bld/pytorch_1579022060824/work/aten/src/TH/generic/THTensor.cpp:612
Setting-up type transforms pipelines
Collecting items from /home/sgugger/.fastai/data/oxford-iiit-pet/images
Found 7390 items
2 datasets of sizes 5912,1478
Setting up Pipeline: PILBase.create
Setting up Pipeline: partial -> Categorize
Building one sample
Pipeline: PILBase.create
starting from
/home/sgugger/.fastai/data/oxford-iiit-pet/images/american_bulldog_83.jpg
applying PILBase.create gives
PILImage mode=RGB size=375x500
Pipeline: partial -> Categorize
starting from
/home/sgugger/.fastai/data/oxford-iiit-pet/images/american_bulldog_83.jpg
applying partial gives
american_bulldog
applying Categorize gives
TensorCategory(12)
Final sample: (PILImage mode=RGB size=375x500, TensorCategory(12))
Setting up after_item: Pipeline: ToTensor
Setting up before_batch: Pipeline:
Setting up after_batch: Pipeline: IntToFloatTensor
Building one batch
Applying item_tfms to the first sample:
Pipeline: ToTensor
starting from
(PILImage mode=RGB size=375x500, TensorCategory(12))
applying ToTensor gives
(TensorImage of size 3x500x375, TensorCategory(12))
Adding the next 3 samples
No before_batch transform to apply
Collating items in a batch
Error! It's not possible to collate your items in a batch
Could not collate the 0-th members of your tuples because got the following
shapes:
torch.Size([3, 500, 375]),torch.Size([3, 375, 500]),torch.Size([3, 333, 500]),
torch.Size([3, 375, 500])
您可以确切地看到我们如何收集和拆分数据,我们如何从文件名到样本(元组(图像、类别)),然后应用了哪些 item transform,以及它如何未能将这些样本分批处理(因为形状不同)。
一旦您认为您的数据看起来是对的,我们通常建议下一步应该使用它来训练一个简单的模型。我们经常看到人们推迟了对实际模型的训练太长时间。因此,他们实际上没有发现他们的基线结果是什么样子的。也许你的问题不需要很多花哨的特定领域工程。或者也许数据似乎根本无法训练模型。这些是你想知道的尽快知道的事情。对于此初始测试,我们将使用简单模型:
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(2)
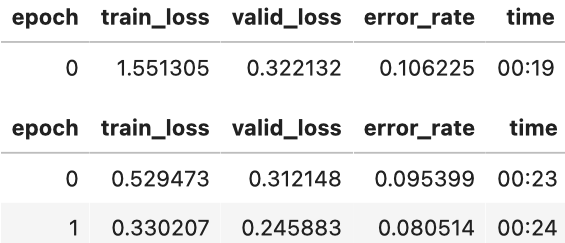
正如我们之前简要讨论的那样,当我们安装模型时显示的表格向我们展示了每个训练 epoch 后的结果。请记住,一个 epoch 是完全通过数据中的所有图像。显示的列是训练集样本的平均损失、验证集的损失以及我们要求的所有指标——在这种例子下是错误率。
请记住,损失是我们决定使用来优化模型的参数的函数。但我们实际上还没有告诉fastai我们要使用什么损失函数。那么它在做什么?Fastai通常会尝试根据您正在使用的数据类型和模型选择适当的损失函数。在这种例子下,我们有图像数据和类别结果,因此fastai将默认使用 cross-entropy 损失。
Cross-Entropy Loss
交叉熵损失是一种类似于我们在上一章中使用的损失函数,但(正如我们将看到的)有两个好处:
- 即使我们的依赖变量有两个以上的类别,它也可以工作。
- 它导致更快、更可靠的训练。
为了了解 cross-entropy 如何适用于两个以上类别的依赖变量,我们首先必须了解损失函数看到的实际数据和激活是什么样子的。
Viewing Activations and Labels
让我们看看我们模型的激活。要从我们的 DataLoaders 实际获取一批真实数据,我们可以使用 one_batch 方法:
x,y = dls.one_batch()
如您所见,这将以小批量的形式返回依赖变量和独立变量。让我们看看我们依赖变量中实际包含的内容:
y
> TensorCategory([ 0, 5, 23, 36, 5, 20, 29, 34, 33, 32, 31, 24, 12, 36, 8, 26, 30, 2, 12, 17, 7, 23, 12, 29, 21, 4, 35, 33, 0, 20, 26, 30, 3, 6, 36, 2, 17, 32, 11, 6, 3, 30, 5, 26, 26, 29, 7, 36,
31, 26, 26, 8, 13, 30, 11, 12, 36, 31, 34, 20, 15, 8, 8, 23], device='cuda:5')
我们的批处理大小是64,所以我们在这个张量中有64行。每行都是0到36之间的单个整数,代表我们37个可能的宠物品种。我们可以使用 Learner.get_preds 查看预测(即神经网络最后一层的激活)。此函数要么接受数据集索引(train 为0,valid 为1),要么接受批处理迭代器。因此,我们可以用我们的批次传递一个简单的列表来获取我们的预测。默认情况下,它返回预测和目标,但由于我们已经拥有目标,我们可以通过分配给特殊变量 _ 来忽略它们:
preds,_ = learn.get_preds(dl=[(x,y)])
preds[0]
> tensor([9.9911e-01, 5.0433e-05, 3.7515e-07, 8.8590e-07, 8.1794e-05, 1.8991e-05, 9.9280e-06, 5.4656e-07, 6.7920e-06, 2.3486e-04, 3.7872e-04, 2.0796e-05, 4.0443e-07, 1.6933e-07, 2.0502e-07, 3.1354e-08,
9.4115e-08, 2.9782e-06, 2.0243e-07, 8.5262e-08, 1.0900e-07, 1.0175e-07, 4.4780e-09, 1.4285e-07, 1.0718e-07, 8.1411e-07, 3.6618e-07, 4.0950e-07, 3.8525e-08, 2.3660e-07, 5.3747e-08, 2.5448e-07,
6.5860e-08, 8.0937e-05, 2.7464e-07, 5.6760e-07, 1.5462e-08])
实际预测是0到1之间的37个概率,总和为1个:
len(preds[0]),preds[0].sum()
> (37, tensor(1.0000))
为了将模型的激活转换为这样的预测,我们使用了所谓的 softmax 激活函数。
Softmax
在我们的分类模型中,我们使用最后一层的 softmax 激活函数,以确保激活都在0到1之间,并且它们的总和为1。
softmax 类似于我们之前看到的 sigmoid 函数。 sigmoid 如下所示:
plot_function(torch.sigmoid, min=-4,max=4)
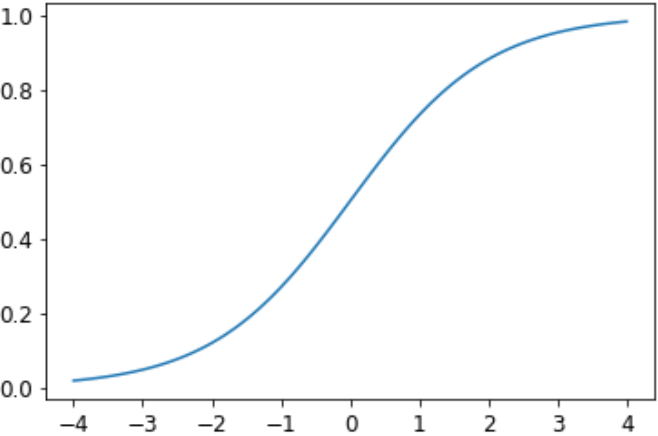
我们可以将此激活函数应用于神经网络的单个列,并返回列数量的0到1之间的数,因此它是我们最后一层非常有用的激活函数。
现在想想,如果我们想在目标中有更多的类别(例如我们的37个宠物品种),会发生什么。这意味着我们需要比单个列更多的激活:我们需要每个类别的激活。例如,我们可以创建一个神经网络,预测 3 和 7,返回两个激活,每个类一个——这将是创建更通用方法的良好第一步。假设我们有6张图像和2个可能的类别(其中第一列代表3,第二列代表7),让我们在本例中使用一些标准偏差为2的随机数字(因此我们将randn乘以2):
#hide
torch.random.manual_seed(42);
acts = torch.randn((6,2))*2
acts
> tensor([[ 0.6734, 0.2576],
[ 0.4689, 0.4607],
[-2.2457, -0.3727],
[ 4.4164, -1.2760],
[ 0.9233, 0.5347],
[ 1.0698, 1.6187]])
我们不能直接使用这个的 sigmoid,因为我们的行求和不等于1(即,我们希望成为3的概率加上成为7的概率加起来1):
acts.sigmoid()
> tensor([[0.6623, 0.5641],
[0.6151, 0.6132],
[0.0957, 0.4079],
[0.9881, 0.2182],
[0.7157, 0.6306],
[0.7446, 0.8346]])
我们的神经网络通过 sigmoid 函数为每张图像创建了单个激活。单个激活表示模型对输入是3的置信度。二分类问题是分类问题的特殊情况,因为目标可以被视为单个布尔值,就像我们在 mnist_loss 中所做的那样。但二分类问题也可以在具有任意数量类别的更一般的分类器组的背景下考虑:在这种情况下,我们碰巧有两个类别。正如我们在熊分类器中看到的,我们的神经网络每个类别将返回一个激活。
那么,在二分类情况下,这些激活真正表示什么?单个激活仅表示输入为3与7的相对置信度。总体值,无论是高还是低,都无关紧要——重要的是哪个更高,有多少。
我们预计,由于这只是代表同一问题的另一种方式,我们将能够直接在神经网络的双激活版本上使用 sigmoid。我们确实可以!我们只需区分神经网络激活,因为这反映了我们对输入的确定性比7大得多,然后取其 sigmoid:
(acts[:,0]-acts[:,1]).sigmoid()
> tensor([0.6025, 0.5021, 0.1332, 0.9966, 0.5959, 0.3661])
第二列(为7的概率)将只是从1中减去的值。现在,我们需要一种方法来完成所有这些,它也适用于两列以上。事实证明,这个被称为softmax的函数正是:
def softmax(x): return exp(x) / exp(x).sum(dim=1, keepdim=True)
让我们检查 softmax 返回的第一列的值是否与 sigmoid 相同,第二列从1中减去这些值:
sm_acts = torch.softmax(acts, dim=1)
sm_acts
> tensor([[0.6025, 0.3975],
[0.5021, 0.4979],
[0.1332, 0.8668],
[0.9966, 0.0034],
[0.5959, 0.4041],
[0.3661, 0.6339]])
softmax 是 sigmoid的多类别等价物——我们必须在有两个以上类别时使用它,类别的概率之和必须为1,即使只有两个类别,我们也经常使用它,只是为了让事情更一致。我们可以创建其他函数,这些函数的特性是所有激活都在0到1之间,总和为1;然而,没有其他函数与 sigmoid 函数具有相同的关系,我们看到 sigmoid 函数是光滑和对称的。此外,我们很快就会看到softmax 函数与我们将在下一节中看到的损失函数合作得很好。
如果我们有三个输出激活,例如在熊分类器中,那么计算单个熊图像的 softmax 会看起来像:
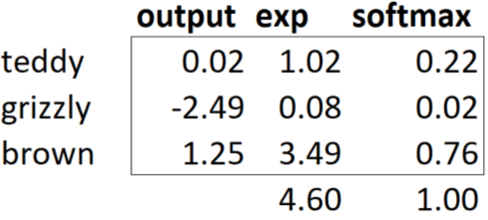
这个函数在实践中的作用是什么?采用指数可以确保我们所有的数字都是正数,然后除以和,可以确保我们有一堆数字加起来等于1。指数还有一个很好的属性:如果我们激活x中的一个数字比其他数字略大,指数将放大这个数字(因为它会增长,嗯……指数级),这意味着在 softmax 中,这个数字将接近1。
直观地说,softmax函数真的想在其他类别中选择一个类,所以当我们知道每张图片都有明确的标签时,它是训练分类器的理想选择。(请注意,在推断期间,它可能不那么理想,因为您可能希望您的模型有时会告诉您,它无法识别训练期间看到的类,并且不会选择类,因为它的激活分数略高。在这种情况下,使用多个二进制输出列训练模型可能更好,每个列都使用 sigmoid 激活。)
Softmax是交叉熵损失的第一部分——第二部分是对数对数似然。
Log Likelihood
当我们计算最后一章MNIST示例的损失时,我们使用了:
def mnist_loss(inputs, targets):
inputs = inputs.sigmoid()
return torch.where(targets==1, 1-inputs, inputs).mean()
正如我们从 sigmoid 转移到 softmax 一样,我们需要扩展损失函数,而不仅仅是二分类——它需要能够对任意数量的类别进行分类(在这种情况下,我们有37个类别)。在 softmax 之后,我们的激活在0到1之间,每行预测的总和为1。我们的目标是0到36之间的整数。
在二分类情况下,我们使用 torch.where 在 inputs 和 1-inputs 之间进行选择。当我们将二分类视为两个类别的一般分类问题时,它实际上变得更加容易,因为(正如我们在上一节中看到的)我们现在有两列,包含等效的 inputs 和 1-inputs 。因此,我们只需要从适当的列中选择。让我们试着在 PyTorch 中实现这一点。对于我们的合成 3 和 7 示例,假设这些是我们的标签:
targ = tensor([0,1,0,1,1,0])
这些是 softmax 激活:
sm_acts
> tensor([[0.6025, 0.3975],
[0.5021, 0.4979],
[0.1332, 0.8668],
[0.9966, 0.0034],
[0.5959, 0.4041],
[0.3661, 0.6339]])
然后,对于每个 targ ,我们可以使用张量索引选择适当的 sm_acts 列,如下所示:
idx = range(6)
sm_acts[idx, targ]
> tensor([0.6025, 0.4979, 0.1332, 0.0034, 0.4041, 0.3661])
为了准确了解这里发生了什么,让我们把所有列放在一个表格里。在这里,前两列是我们的激活,然后我们有目标,行索引,最后是上面显示的结果:
#hide_input
from IPython.display import HTML
df = pd.DataFrame(sm_acts, columns=["3","7"])
df['targ'] = targ
df['idx'] = idx
df['loss'] = -sm_acts[range(6), targ]
t = df.style.hide_index()
#To have html code compatible with our script
html = t._repr_html_().split('</style>')[1]
html = re.sub(r'<table id="([^"]+)"\s*>', r'<table >', html)
display(HTML(html))
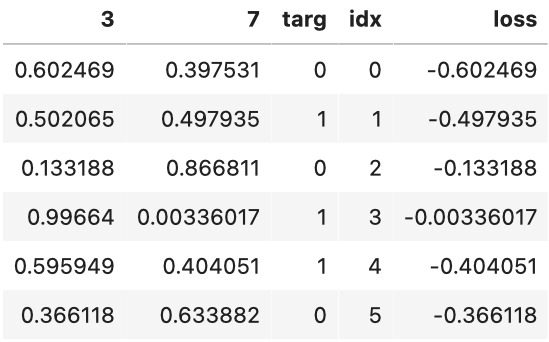
看看这个表,你可以看到最后一列可以通过将 targ 和 idx 列作为索引进入包含3列和7列的两列矩阵来计算。这就是 sm_acts[idx, targ] 的实际作用。
这里真正有趣的是,这实际上对于超过两列的数据一样有效。要查看这一点,请考虑如果我们为每个数字(0到9)添加一个激活列,然后targ包含一个从0到9的数字会发生什么。只要激活列的总和为1(如果我们使用softmax,他们会这样做),那么我们将有一个损失函数,显示我们对每个数字的预测程度。
我们只是从包含正确标签的列中选择损失。我们不需要考虑其他列,因为根据 softmax 的定义,它们加起来等于 1 减去正确标签对应的激活。因此,使正确标签的激活率尽可能高,这必须意味着我们也在减少剩余列的激活。
PyTorch 提供了一个与 sm_acts[range(n), targ] 完全相同的函数(除了它接受负数,因为应用 log 之后,我们将有负数),称为 nll_loss(NLL代表负对数似然):
-sm_acts[idx, targ]
> tensor([-0.6025, -0.4979, -0.1332, -0.0034, -0.4041, -0.3661])
F.nll_loss(sm_acts, targ, reduction='none')
> tensor([-0.6025, -0.4979, -0.1332, -0.0034, -0.4041, -0.3661])
尽管它的名字,但这个PyTorch函数不会使用 log。我们将在下一节中了解原因,但首先,让我们看看为什么使用对数会有用。
Taking the Log
我们在上一节中看到的函数作为损失函数效果很好,但我们可以让它变得更好一点。问题在于我们正在使用概率,概率不能小于0或大于1。这意味着我们的模型不会在乎它预测0.99还是0.999。事实上,这些数字非常接近——但从另一个意义上说,0.999的信心是0.99的10倍。因此,我们希望将数字在0和1之间转换成负无限和0之间。有一个数学函数可以做到这一点:对数(可用作 torch.log )。它不是为小于0的数字定义的,如下所示:
plot_function(torch.log, min=0,max=4)
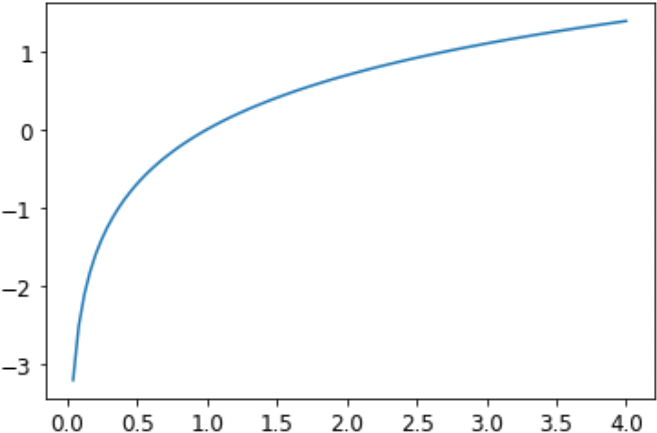
对数函数具有以下性质:
y = b**a
a = log(y,b)
在这种情况下,我们假设 log(y,b) 返回以 b 为底 log y 。然而,PyTorch实际上没有这样定义 log :log 在 Python使用特殊数字 e(2.718...) 作为底。
也许对数是你过去20年左右没有想到的事情。但对于深度学习的许多事情来说,这是一个数学想法,它真的很关键,所以现在将是刷新记忆的好时机。了解对数的关键是这种关系:
log(a * b) = log(a) + log(b)
当我们看到这种格式时,它看起来有点无聊;但想想这到底意味着什么。这意味着当基础信号呈指数级或乘法增加时,对数会线性增加。例如,这用于地震严重程度的 Richter scale 和 噪声水平的dB scale 。它还经常用于金融图表,我们希望更清楚地显示复合增长率。计算机科学家喜欢使用对数,因为它意味着乘法可以创建非常大和非常小的数字,可以用加法取代,这不太可能导致我们的计算机难以处理的尺度。
S:不仅仅是计算机科学家喜欢 log !在计算机出现之前,工程师和科学家使用一种名为“slide rule” 的 special ruler,其通过添加对数进行乘法。对数广泛应用于物理学、乘以非常大或非常小的数字以及许多其他领域。
以我们概率的正数或负数的平均值(取决于它是正确的类还是不正确的类)来得出负对数似然损失。在PyTorch中,nll_loss 假设您已经实现了 softmax 的 log ,因此它实际上不会为您完成对数。
警告:混淆名称,当心:
nll_loss中的nll代表“负对数似然”,但它实际上根本不使用 log!它假设你已经采用了 log 。PyTorch有一个名为log_softmax的函数,该函数以快速准确的方式将log和softmax结合起来。nll_loss设计用于log_softmax之后。
当我们首先取 softmax,然后取对数似然时,这种组合被称为交叉熵损失。在PyTorch中,这可以作为 nn.CrossEntropyLoss 使用(在实践中,它实际上可以进行 log_softmax ,然后是 nll_loss ):
loss_func = nn.CrossEntropyLoss()
如你所见,这是一个类。实例化它为您提供了一个行为类似于函数的对象:
loss_func(acts, targ)
> tensor(1.8045)
所有 PyTorch 损失函数都以两种形式提供,如上所示的类,以及 F 命名空间中可用的纯函数形式:
F.cross_entropy(acts, targ)
> tensor(1.8045)
任一都可以正常工作,在任何情况下都可以使用。我们注意到,大多数人倾向于使用类版本,这在PyTorch的官方文档和示例中更常用,所以我们也倾向于使用它。
默认情况下,PyTorch损失函数采用所有样本损失的平均值。您可以使用 reduction='none' 来禁用它:
nn.CrossEntropyLoss(reduction='none')(acts, targ)
> tensor([0.5067, 0.6973, 2.0160, 5.6958, 0.9062, 1.0048])
S:当我们考虑交叉熵损失的梯度时,就会出现一个有趣的特征。
cross_entropy(a,b)的梯度只是softmax(a)-b。由于softmax(a)只是模型的最终激活,这意味着梯度与预测和目标之间的差异成正比。这与回归的平均平方误差相同,因为(a-b)**2的梯度是2*(a-b)。由于梯度是线性的,这意味着我们不会看到梯度的突然跳跃或指数增长,这应该会导致模型更平稳的训练。
我们现在看到了隐藏在我们损失功能背后的所有碎片。但是,尽管这说明了我们的模型做得有多好(或糟糕),但它无助于帮助我们知道它是否真的有什么好处。现在让我们看看解释模型预测的一些方法。
Model Interpretation
直接解释损失函数非常困难,因为它们被设计成计算机可以区分和优化的东西,而不是人们可以理解的东西。这就是为什么我们有指标的原因。这些不用于优化过程,而只是为了帮助我们了解发生了什么。在这种情况下,我们的准确性看起来已经相当不错了!那么,我们在哪里犯错呢?
我们在下面看到,我们可以使用混淆矩阵来查看我们的模型在哪里做得很好,在哪里做得不好:
#width 600
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix(figsize=(12,12), dpi=60)
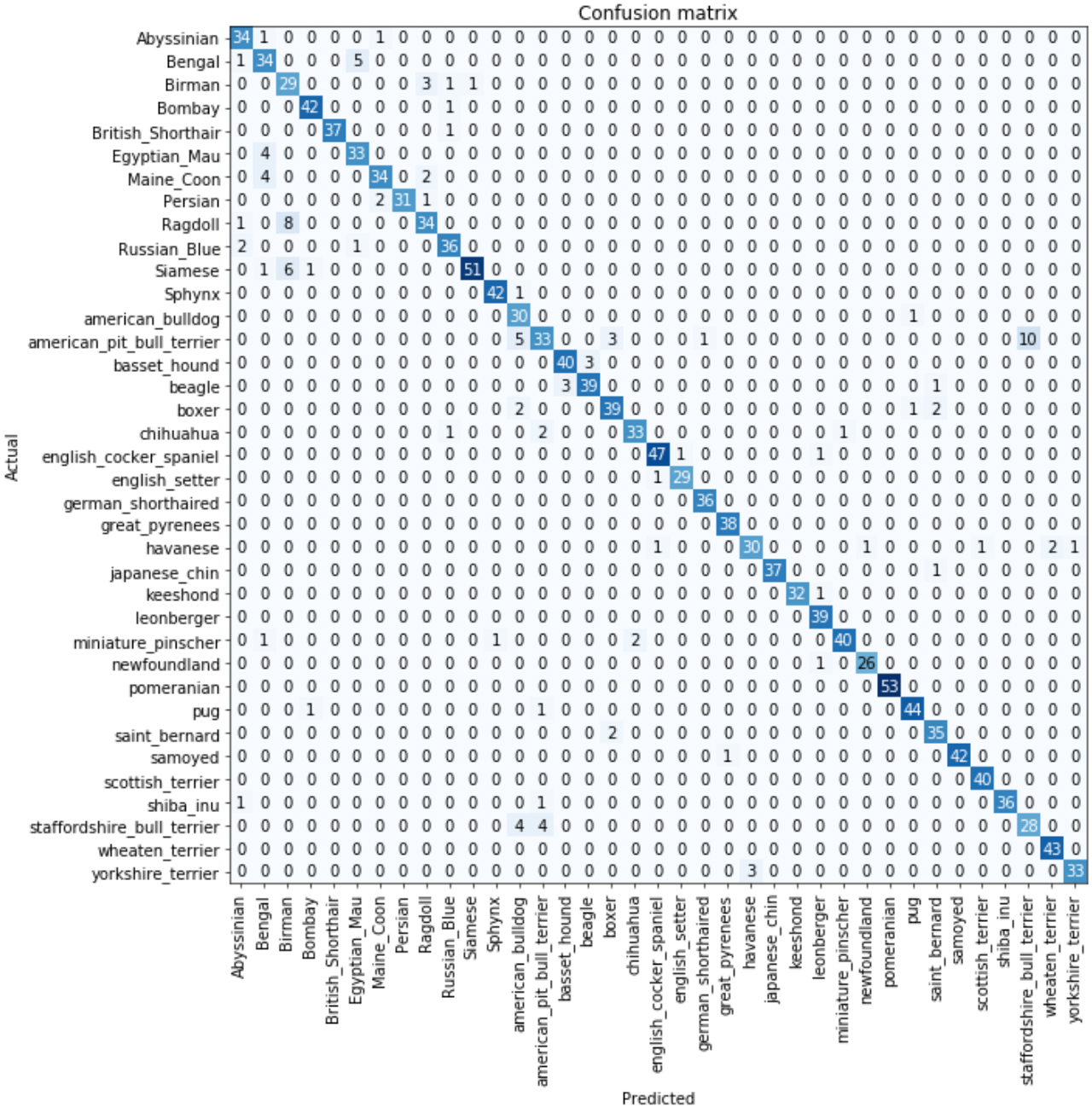
哦,天啊——在这种情况下,混淆矩阵很难读懂。我们有37种不同品种的宠物,这意味着在这个巨大的矩阵中,我们有37×37个条目!进而,我们可以使用 most_confused 的方法,它只是向我们显示预测最不正确的混淆矩阵的单元格(此处,至少有5个或更多):
interp.most_confused(min_val=5)
> [('american_pit_bull_terrier', 'staffordshire_bull_terrier', 10),
('Ragdoll', 'Birman', 8),
('Siamese', 'Birman', 6),
('Bengal', 'Egyptian_Mau', 5),
('american_pit_bull_terrier', 'american_bulldog', 5)]
由于我们不是宠物品种专家,我们很难知道这些类别错误是否反映了识别品种的实际困难。因此,我们再次转向谷歌。一点点谷歌搜索告诉我们,这里显示的最常见类别错误实际上是即使是专家育种者有时也不同意的品种差异。因此,这给了我们一些安慰,因为我们走在正确的轨道上。
我们似乎有一个好的基线。我们现在能做些什么来让它变得更好?
Improving Our Model
我们现在将研究一系列技术,以改进模型的训练并使其变得更好。在这样做的同时,我们将进一步解释一下迁移学习,以及如何在不打破预训练的权重的情况下尽可能微调我们的预训练模型。
在训练模型时,我们需要设置的第一件事是学习率。我们在上一章中看到,尽可能高效地训练需要恰到好处,那么我们如何选择一个好的呢?Fastai为此提供了一个工具。
The Learning Rate Finder
在训练模型时,我们可以做的最重要的事情之一是确保我们有正确的学习率。如果我们的学习率太低,训练我们的模型可能需要很多很多epoch。这不仅浪费了时间,还意味着我们可能存在过拟合的问题,因为每次我们完全通过数据时,我们都会给我们的模型一个记住它的机会。
所以让我们让我们的学习率非常高,对吗?当然,让我们试试看会发生什么:
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1, base_lr=0.1)
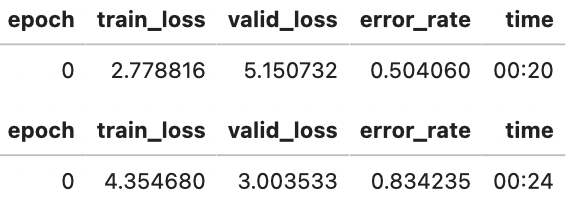
那看起来不太好。事情是这样的。优化器朝着正确的方向前进,但它走得太远了,完全超过了最小的损失。重复多次会使它越来越远,而不是越来越近!
我们该怎么做才能找到完美的学习率——不是太高,也不是太低?2015年,研究员莱斯利·史密斯提出了一个好主意,称为学习率查找器。他的想法是从非常、非常小的学习率开始,这种学习率是如此之小,以至于我们永远不会期望它太大而无法处理。我们使用它进行一个小批量,找出之后的损失,然后将学习率提高一定百分比(例如,每次加倍)。然后我们再做一个迷小批量,跟踪损失,并将学习率再次提高一倍。我们继续这样做,直到损失变得更糟,而不是好转。这就是我们知道我们走得太远的地方。然后,我们选择比这一点低一点的学习率。我们的建议是选择:
- 比实现最小损失的地方少一个数量级(即最小损失除以10)
- 损失明显减少的最后一点
学习率查找器计算曲线上的这些点以帮助您。这两条规则通常都赋予相同的价值。在第一章中,我们没有使用指定学习率, 而是使用fastai库的默认值(1e-3):
learn = cnn_learner(dls, resnet34, metrics=error_rate)
lr_min,lr_steep = learn.lr_find()
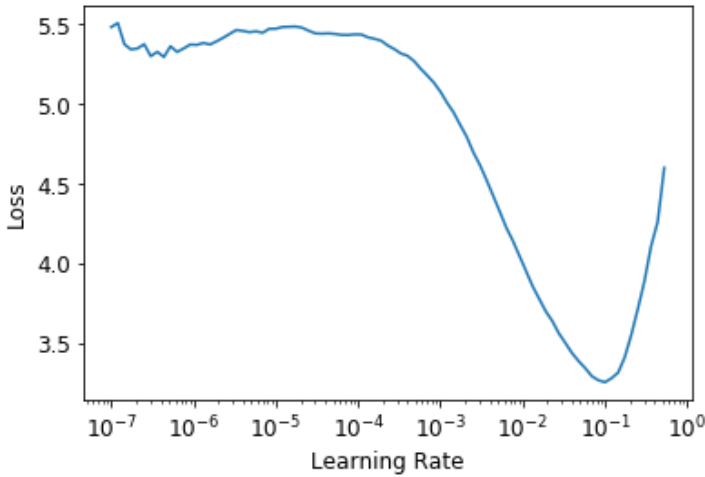
print(f"Minimum/10: {lr_min:.2e}, steepest point: {lr_steep:.2e}")
> Minimum/10: 1.00e-02, steepest point: 5.25e-03
我们在这个 plot 中可以看到,在1e-6到1e-3之间,什么都没发生,模型没有训练。然后损失开始减少,直到达到最低水平,然后再次增加。我们不希望学习率超过1e-1,因为它会提供像以前一样不同的训练(你可以自己尝试),但1e-1已经太高了:在这个阶段,我们已经离开了损失稳步下降的时期。
在这个学习率图中,3e-3左右的学习率似乎是合适的,所以让我们选择:
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(2, base_lr=3e-3)
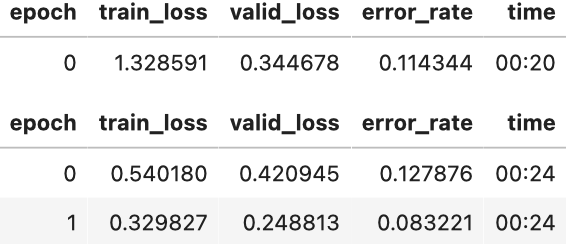
注:对数尺度:学习速率查找器图具有对数尺度,这就是为什么1e-3和1e-2之间的中点在3e-3和4e-3之间。这是我们最关心学习率的数量级。
有趣的是,学习率查找器直到2015年才被发现,而神经网络自20世纪50年代以来一直在开发中。在此期间,找到良好的学习率也许一直是从业者最重要和最具挑战性的问题。该解决方案不需要任何高级数学、巨大的计算资源、巨大的数据集或其他任何好奇的研究人员都无法访问它的东西。此外,莱斯利·史密斯不是硅谷一些独家实验室的一部分,而是一名海军研究员。所有这些都可以说:深度学习的突破性工作绝对不需要获得丰富的资源、精英团队或先进的数学思想。还有很多工作要做,只需要一点常识、创造力和坚韧不拔。
现在我们有很好的学习率来训练我们的模型,让我们看看如何微调预训练模型的权重。
Unfreezing and Transfer Learning
我们之前简要讨论了迁移学习的工作原理。我们看到,基本想法是,可能在数百万个数据点(如ImageNet)上训练的预训练模型可以微调其他一些任务。但这到底是什么意思?
我们现在知道,卷积神经网络由许多线性层组成,每对之间都有非线性激活函数,然后是一个或多个最后的最终线性层,其激活函数为softmax。最后的线性层使用具有足够列的矩阵,因此输出大小与我们模型中的类数量相同(假设我们正在进行分类)。
当我们在迁移学习设置中微调时,这个最后的线性层不太可能对我们有任何用处,因为它是专门为对原始训练前数据集中的类别进行分类而设计的。因此,当我们迁移学习时,我们会删除它,扔掉它,并用一个新的线性层替换它,该线性层具有我们期望任务的正确输出数量(在这种情况下,将有37个激活)。
这个新添加的线性层将具有完全随机的权重。因此,我们的模型在微调之前具有完全随机的输出。但这并不意味着它是一个完全随机的模型!上一层之前的所有层都经过了精心训练,以擅长图像分类任务。正如我们从Zeiler和Fergus论文中的图像中看到的,前几层编码非常一般的概念,如查找梯度和边缘,以及后来的层编码对我们仍然非常有用的概念,如查找眼球和毛皮。
我们希望以这样一种方式训练模型,使它能够记住预训练模型中所有这些通常有用的想法,使用它们来解决我们的特定任务(对宠物品种进行分类),并且只根据特定任务的具体情况进行调整。
微调时的挑战是将我们添加的线性层中的随机权重替换为正确完成我们期望任务(宠物品种分类)的权重,而不会打破精心预训练的权重和其他层。实际上有一个非常简单的技巧可以允许这种情况发生:告诉优化器只更新那些随机添加的最后层中的权重。完全不要改变神经网络其余部分的权重。这被称为冻结那些预训练的层。
当我们从预训练的网络创建模型时,fastai会自动为我们冻结所有预训练的层。当 fastai 调用 fine_tune 方法时有两件事:
- 训练一个 epoch 的随机添加的layer,所有其他 layer 都被冻结
- 解冻所有 layer ,并根据要求的 epoch 数量训练它们
虽然这是一个合理的默认方法,但对于您的特定数据集,您可能会通过稍微不同的方式做事情来获得更好的结果。fine_tune 方法有许多参数可用于更改其行为,但如果您想获得一些自定义行为,您可能最容易直接调用基础方法。请记住,您可以使用以下语法查看该方法的源代码:
learn.fine_tune??
所以让我们自己试着手动做这件事吧。首先,我们将使用 fit_one_cycle 为三个 epoch 训练随机添加的 layer 。fit_one_cycle 是建议在不使用 fine_tune 的情况下训练模型的方法。在书的后面,我们将了解为什么;简而言之,fit_one_cycle 所做的是以较低的学习率开始训练,在训练的第一部分逐步增加学习率,然后在训练的最后一部分再次逐步减少学习率。
learn.fine_tune??
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(3, 3e-3)
然后我们将解冻模型:
learn.unfreeze()
再次运行 lr_find ,因为有更多的层需要训练,以及已经训练了三个 epoch 的权重,这意味着我们之前发现的学习率不再合适了:
learn.lr_find()
> (1.0964782268274575e-05, 1.5848931980144698e-06)
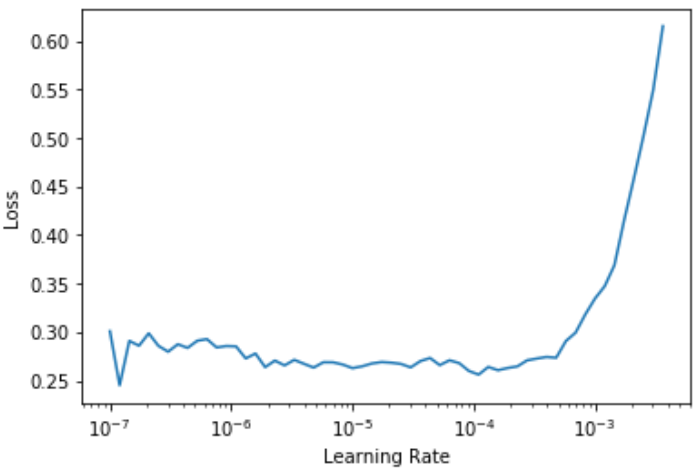
请注意,该图表与我们随机权重时略有不同:没有表明模型正在训练的急剧下降。那是因为我们的模型已经训练过了。在这里,在急剧增加之前,我们有一个有点平坦的区域,我们应该在急剧增加之前多一点——例如,1e-5。最大梯度的一点不是我们在这里寻找的,应该忽略。
让我们以适当的学习速度进行训练:
learn.fit_one_cycle(6, lr_max=1e-5)
这稍微改进了我们的模型,但我们还可以做更多。我们预训练模型的最深层可能不需要像上一层那样高的学习率,所以我们可能应该对这些模型使用不同的学习率——这被称为使用判别性学习率。
Discriminative Learning Rates
即使我们解冻,我们仍然非常关心那些预训练的权重的质量。即使我们已经调整了这些随机添加的参数几个 epoch,我们也不会期望这些预训练参数的最佳学习率与随机添加的参数一样高。请记住,预训练的权重已经训练了数百个 epoch,在数百万张图像上。
此外,你还记得之前看到的显示每个层所学内容的图像吗?第一层学习非常简单的基础,如边缘和梯度探测器;这些基础对几乎所有任务都可能同样有用。后面的几层学习了更复杂的概念,如“眼睛”和“日落”,这可能对您的任务毫无用处(例如,您可能正在对汽车型号进行分类)。因此,让后面的图层比前面的图层更快地微调是有道理的。
因此,fastai的默认方法是使用判别性学习率。这最初是在ULMFiT 方法进行 NLP 迁移学习开发的。像深度学习中的许多好主意一样,它非常简单:神经网络的早期层使用较低的学习率,后层(特别是随机添加的层)使用更高的学习率。这个想法是基于Jason Yosinski开发的见解,他在2014年表明,随着迁移学习,神经网络的不同层应该以不同的速度训练。
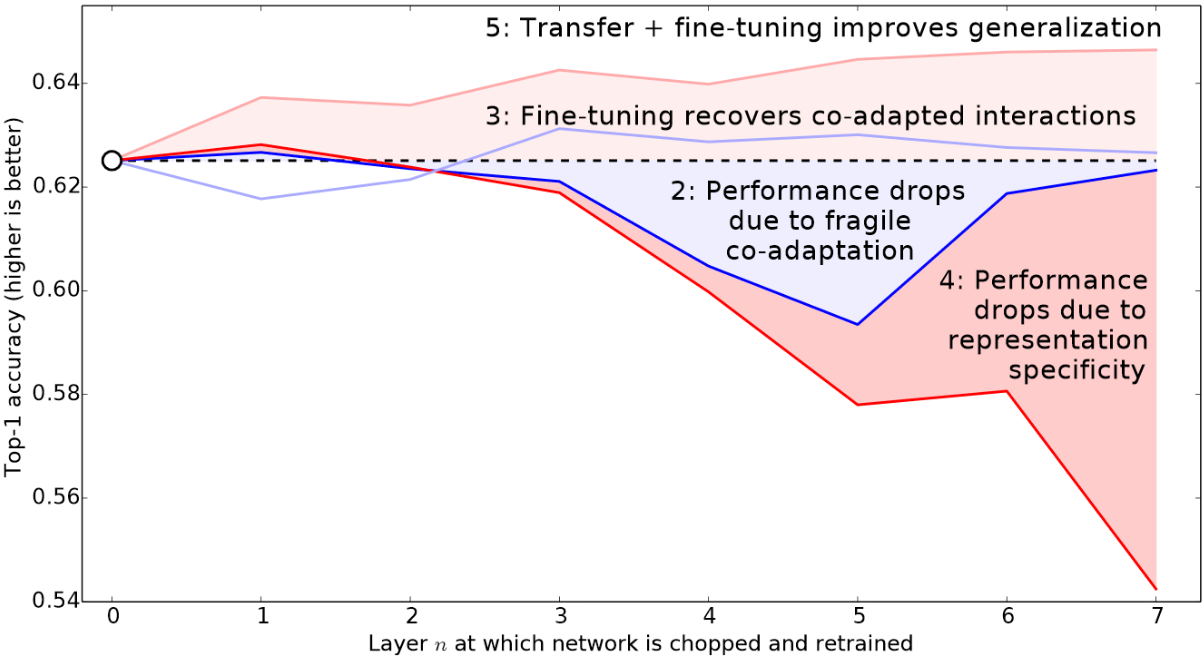
fastai 允许您将Python切片对象传递到所有预期学习率的地方。通过的第一个值将是神经网络最早层的学习率,第二个值将是最后层的学习率。介于两者之间的层将具有在整个范围内乘以等距离的学习率。让我们使用这种方法来复制之前的训练,但这次我们只会将网络的最低层设置为1e-6的学习率;其他层将扩展到1e-4。让我们训练一会儿,看看会发生什么:
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(3, 3e-3)
learn.unfreeze()
learn.fit_one_cycle(12, lr_max=slice(1e-6,1e-4))
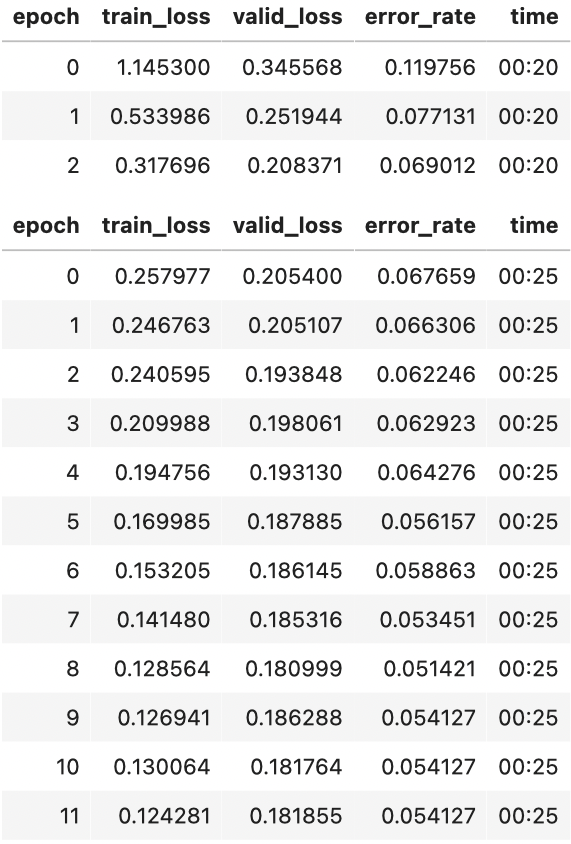
现在微调效果很好!
Fastai可以向我们显示训练和验证损失的图表:
learn.recorder.plot_loss()
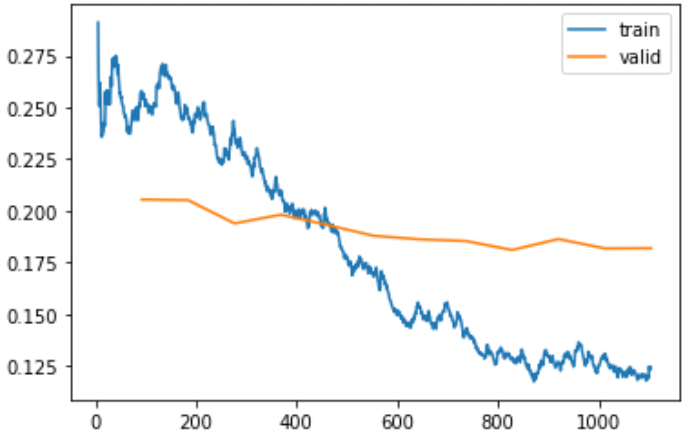
正如你所看到的,训练损失越来越好。但请注意,最终验证损失的改进会放缓,有时甚至会变得更糟!这就是模型开始过拟合的点。特别是,该模型对其预测变得过于自信。但这并不意味着它必然会变得不那么准确。看看每个 epoch 的训练结果表,你经常会看到准确性继续提高,即使验证损失越来越严重。最后,重要的是你的准确性,或者更一般地说,是你选择的指标,而不是损失。损失只是我们赋予计算机帮助我们优化的功能。
在训练模型时,你必须做出的另一个决定是训练多长时间。我们接下来会考虑的。
Selecting the Number of Epochs
通常,在选择要训练的 epoch 时,你会发现你受到时间的限制,而不是泛化性和准确性的限制。因此,您的第一个训练方法应该是简单地选择一些epoch,这些 epoch 将按照您乐意等待的时间进行训练。然后看看上面显示的训练和验证损失 plot,特别是你的指标,如果你看到即使在你最后的 epoch,它们仍然在进步,那么你就知道你训练的时间不够。
另一方面,你可能会看到,在训练结束时,你选择的指标真的越来越糟糕了。请记住,我们不仅在寻找验证损失的恶化,还在寻找实际指标。您的验证损失首先会在训练期间恶化,因为模型过于自信,然后才会恶化,因为它错误地记住了数据。我们在实践中只关心后一个问题。请记住,我们的损失函数只是我们用来让我们的优化器拥有可以微分和优化的东西;它实际上不是我们在实践中关心的事情。
在 1cycle 训练的日子之前,在每个 epoch 结束时保存模型,然后从每个 epoch 保存的所有模型中选择哪个模型的准确性最高,这是非常常见的。这被称为 earlystopping。然而,这不太可能给你最好的答案,因为中间的那些 epoch 发生在学习率有机会达到小价值之前,在那里它真的可以找到最好的结果。因此,如果您发现自己过拟合了,您实际上应该做的是从头开始重新训练模型,这次根据您之前的最佳结果在哪里找到,选择一个epoch总数。
如果您有时间为更多时代进行训练,您可能希望利用这段时间训练更多参数——即使用更深层次的架构。
Deeper Architectures
一般来说,具有更多参数的模型可以更准确地建模您的数据。(对这种概括有很多很多注意事项,这取决于您正在使用的架构的细节,但目前这是一个合理的经验法则。)对于我们将在本书中看到的大多数架构,您只需添加更多层即可创建更大的版本。然而,由于我们希望使用预训练模型,我们需要确保我们选择一些已经预训练的层。
这就是为什么在实践中,架构往往有少量变体。例如,我们在本章中使用的ResNet架构有18、34、50、101和152层的变体,在ImageNet上预先训练。ResNet更大的(更多层和参数;有时被称为模型的“容量”)版本将始终能够给我们带来更好的训练损失,但它可能会因过拟合而遭受更大的影响,因为它有更多的参数可以过拟合。
一般来说,更大的模型有能力更好地捕获数据中的真实潜在关系,并捕获和记住单个图像的具体细节。
然而,使用更深的版本需要更多的GPU RAM,因此您可能需要降低批处理的大小,以避免内存外错误。当您试图在GPU中安装太多东西时,就会发生这种情况,并且看起来像:
Cuda runtime error: out of memory
发生这种情况时,您可能需要重新启动 Notebook。解决这个问题的方法是使用较小的批处理大小,这意味着在任何给定时间通过模型传递较小的图像组。您可以将您想要的批处理大小传递给DataLoaders。
更深层次架构的另一个缺点是,它们需要更长的时间才能训练。一种可以大大加快速度的技术是混合精度训练。这是指在训练期间尽可能使用不太精确的数字(半精度浮点,也称为fp16)。由于我们在2020年初编写这些单词,几乎所有当前的NVIDIA GPU都支持一项名为张量核心的特殊功能,该功能可以大幅加快神经网络训练2-3倍。它们还需要少得多的GPU内存。要在fastai中启用此功能,只需在 Leaner 创建后添加 to_fp16()(您还需要导入模块)。
您无法提前真正知道解决您特定问题的最佳架构是什么——您需要尝试训练一些架构。因此,现在让我们尝试混合精度的ResNet-50:
from fastai.callback.fp16 import *
learn = cnn_learner(dls, resnet50, metrics=error_rate).to_fp16()
learn.fine_tune(6, freeze_epochs=3)
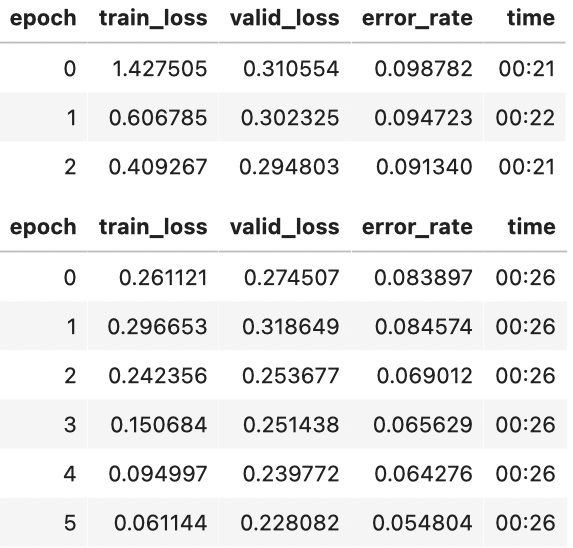
你会在这里看到,我们已经恢复了使用 fine_tune,因为它太方便了!我们可以通过冻结 epoch,告诉 fastai 在冻结期间要训练多少个 epoch。它将自动适当更改大多数数据集的学习率。
在这种情况下,我们没有看到更深层次模型的明显胜利。这有助于记住——更大的模型不一定是适合您特定案例的更好模型!在开始升级之前,请确保您尝试小型版本。
Conclusion
在这一章中,您学习了一些重要的实用技巧,既可以让您的图像数据为建模做好准备( presizing、data block summary)和拟合模型(学习率查找器、解冻、判别性学习率、设置 epoch 数和使用更深层次的体系结构)。使用这些工具将帮助您更快地构建更准确的图像模型。
我们还讨论了交叉熵损失。这本书的这一部分值得花很多时间读。在实践中,您不太可能自己实际上不需要从头开始实现跨熵损失,但了解该函数的输入和输出真的很重要,因为它(或我们将在下一章中看到的变体)几乎用于每个分类模型。因此,当您想调试模型,或将模型投入生产,或提高模型的准确性时,您需要能够查看其激活和丢失,并了解发生了什么,以及原因。如果你不了解你的损失函数,你就无法正确做到这一点。
如果交叉熵损失还没有为你“点击”,别担心——你会到达那里的!首先,回到最后一章,确保你真正理解mnist_loss。然后逐步浏览本章笔记本的单元格,在那里我们逐步完成每一块交叉熵损失。确保你了解每个计算都在做什么,以及为什么。尝试自己创建一些小张量,并将其传递到函数中,看看它们返回了什么。
请记住:在实施交叉熵损失时做出的选择并不是唯一可能做出的选择。就像我们在查看回归时一样,我们可以在平均平方误差和平均绝对差(L1)之间做出选择。如果您对您认为可能可行的功能有其他想法,请随时在本章的笔记本中尝试一下!(但警告是:您可能会发现模型的训练速度会慢,准确性也会降低。这是因为交叉熵损失的梯度与激活和目标之间的差异成正比,因此SGD总是获得权重的良好缩放步骤。)