On this page
Attention Cues
Thank you for your attention to this book。
Attention是一种稀缺资源:现在你正在读这本书,忽略了其他的。因此,和金钱一样,你的注意力也伴随着机会成本。为了确保你现在投入的注意力是值得的,我们一直被高度激励着用心去创作一本好书。
根据经济学研究中 稀缺资源的分配,我们正处于注意力经济时代,在这个时代,人类的注意力被视为一种有限的、有价值的、稀缺的、可以交换的商品。人们利用它开发了许多商业模式。在音乐或视频流媒体服务上,我们要么关注它们的广告,要么花钱隐藏它们。为了在网络游戏世界中成长,我们要么付出注意力参与战斗,吸引新玩家,要么花钱立即变得强大。天下没有免费的午餐。
总之,信息在我们的环境中并不稀缺,注意力才是。当注视一个视觉场景时, 我们的光学神经每秒感受到 $10^8$ bits, 远远超出我们的大脑所能完全处理的信息。幸运的是,我们的祖先从经验(也被称为数据)中了解到,not all sensory inputs are created equal。纵观人类历史,将注意力集中在少数感兴趣的信息上的能力使我们的大脑能够更聪明地分配资源以生存、成长和社交,比如发现捕食者、猎物和配偶。
Attention Cues in Biology
为了解释我们的注意力是如何在视觉世界中被部署的,一个双组件框架已经出现并普遍存在。这个观点可以追溯到19世纪90年代的威廉·詹姆斯,他被认为是美国心理学之父[James, 2007]。在这个框架中,受试者利用 nonvolitional cue 和 volitional cue 有选择地引导注意力。
nonvolitional cue 以环境中物体的 saliency 和 conspicuity 为基础。 想象你面前有五样东西:一份报纸,一份研究报告,一杯咖啡,一个笔记本和一本书,如图10.1.1所示。所有的纸制品都是黑白印刷的,而咖啡杯是红色的。换句话说,这杯咖啡在这个视觉环境中本质上是很突出和明显的,自动地 和 不自觉地 吸引注意力。所以你把 fovea ( the center of the macula where visual acuity is highest ) 放在咖啡上,如图10.1.1所示。
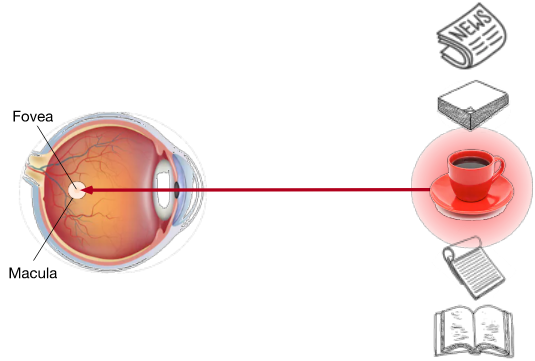
Fig. 10.1.1 使用基于 saliency 的 nonvolitional cue ( red cup, non-paper ),注意力会不由自主地指向咖啡。
喝完咖啡后,你会变得 caffeinated ,想要读一本书。所以你转过头,重新聚焦你的眼睛,然后看着书,如图10.1.2所示。在图10.1.1的案例中,咖啡会让你基于 saliency 选择,而在这个任务依赖的案例中,你会在 cognitive 和volitional 控制下选择书籍。使用基于 variable selection criteria 的 volitional cue,这种形式的注意力更刻意。主体的自主意愿也更强大。
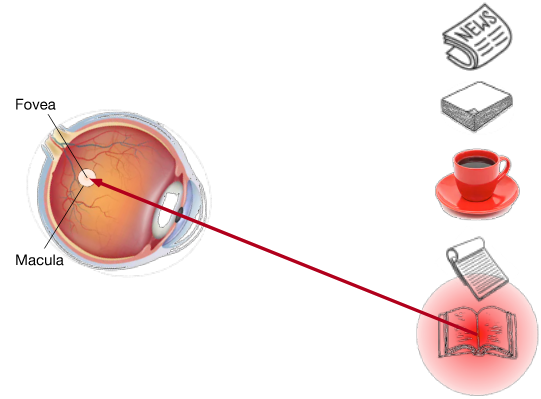
Fig. 10.1.2 使用依赖于任务的 volitional cue (想要读一本书),注意力被引导到 volitional 控制下的书。
Queries, Keys, and Values
在解释注意力部署的nonvolitional 和 volitional 线索的启发下,我们将描述一个 结合这两种注意线索 设计注意力机制的框架。
首先,考虑一个更简单的情况,即只有 nonvolitional cues 可用。为了对sensory inputs 进行 bias selection,我们可以简单地使用参数化的全连接层,甚至非参数化的最大或平均池化。
因此,将注意力机制与那些全连接的层或池化的层区别开来的 是 包含volitional cues。在注意力机制的背景下,我们将 volitional cues 称为 queries 。对于任何 query,注意力机制通过注意力池化对sensory inputs (例如,中间特征表征) 进行 bias selection。在注意力机制的背景下,这些 sensory inputs 被称为 values。更普遍地说,每个 value 都与一个 key 配对,这可以被认为是 sensory input 的 nonvolitional cue 。如图10.1.3所示,我们可以设计注意力池化,使给定的 query (volitional cue)可以与 keys ( nonvolitional cues )交互,从而引导对 values (sensory inputs))的bias selection。
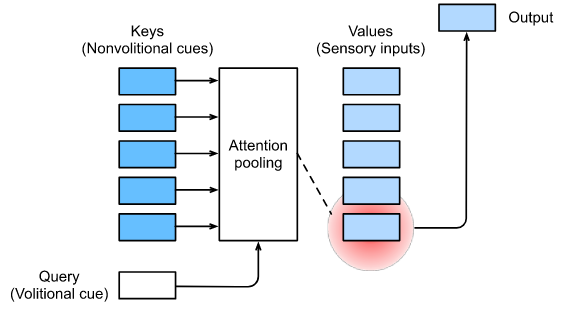
Fig. 10.1.3 注意力机制通过注意力池化(包括 queries (volitional cues) 和 keys (nonvolitional cues) )对 values (sensory inputs) 进行 bias selection。
注意,注意力机制的设计有很多选择。 例如,我们可以设计一个不可微分的注意力模型,该模型可以使用强化学习方法进行训练[Mnih et al., 2014]。考虑到图10.1.3中框架的主导地位,该框架下的模型将是本章关注的中心。
Visualization of Attention
平均池化可以被视为输入的加权平均,其中权重是均匀的。在实践中,注意力池化使用加权平均来聚合值,其中权重在给定 query 和不同 keys 之间计算。
import torch
from d2l import torch as d2l
为了可视化注意力权重,我们定义了 show_heatmaps 函数。 它的输入矩阵的形状(要展示的行数, 要展示的列数, query的数量, keys的数量)。
def show_heatmaps(matrices, xlabel, ylabel, titles=None, figsize=(2.5, 2.5),cmap='Reds'):
"""
args:
matrices(tensor) : 要画的attention weights, shape 为 要展示的行数, 要展示的列数, query的数量, keys的数量
xlabel(str) : x轴的标签
ylabel(str) : y轴的标签
titles : 标题
figsize : 设置fig的尺寸
cmap : map的color
return:
code :
"""
d2l.use_svg_display()
num_rows, num_cols = matrices.shape[0], matrices.shape[1]
fig, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize,
sharex=True, sharey=True, squeeze=False)
# axes 应该是一个 n 行 m 列的fig “矩阵”, 遍历时先遍历行,再遍历列
for i, (row_axes, row_matrices) in enumerate(zip(axes, matrices)):
for j, (ax, matrix) in enumerate(zip(row_axes, row_matrices)):
pcm = ax.imshow(matrix.detach().numpy(), cmap=cmap)
# 在最下面一行添加 x 轴的标签
if i == num_rows - 1:
ax.set_xlabel(xlabel)
# 在第一列添加 y 轴的标签
if j == 0:
ax.set_ylabel(ylabel)
if titles:
ax.set_title(titles[j])
fig.colorbar(pcm, ax=axes, shrink=0.6)
为了演示,我们考虑一个简单的例子,只有当 query 和 key 相同时,注意力权重才为1; 否则就是0。

在后面的小节中,我们将经常调用这个函数来可视化注意力权重。
Summary
- 人类的注意力是一种有限的、有价值的、稀缺的资源。
- 主体使用 nonvolitiona 线索和 volitional 线索选择性地引导注意力。前者是基于saliency,后者是 task-dependent。
- 注意力机制由于包含了 volitional 线索而不同于全连接层或池化层。
- 注意力机制通过注意力池化(包括queries(volitional cues)和keys(nonvolitional cues))对values(sensory inputs) 进行 bias selection 。Keys 和 values 是配对的。
- 我们可以可视化 queries 和 keys 之间的注意力权重。
Exercises
- 在机器翻译中,一个符号一个符号地解码序列时,什么是volitional cue?什么是 nonvolitional cues 和 sensory inputs?
- 随机生成一个 $10 \times 10$ 矩阵,使用softmax操作确保每一行是一个有效的概率分布。可视化输出的注意力权重。