On this page
我们在第10.6.2节比较了CNNs、RNNs和self-attention。特别地,self-attention既可以并行计算,又有最短的最大路径长度。因此,自然而然地,通过self-attention来设计深层次的结构是很有吸引力的。
与早期仍依赖于RNNs的 self-attention 不同[Cheng et al., 2016][Lin et al., 2017b][Paulus et al., 2017], transformer模型完全基于注意力机制,没有任何卷积或循环层[Vaswani et al., 2017]。虽然最初被提议用于文本数据的序列到序列学习,但transformers器已经广泛应用于现代深度学习应用,如语言、视觉、语音和强化学习等领域。
Model
作为encoder-decoder结构的实例,transformer的整体架构如图10.7.1所示。如我们所见,transformer由encoder和decoder组成。与图10.4.1中的Bahdanau attention对序列到序列学习不同的是,输入(源)和输出(目标)序列 embeddings 在被输入到基于 self-attention 堆叠模块的encoder和decoder之前,先进行位置编码。
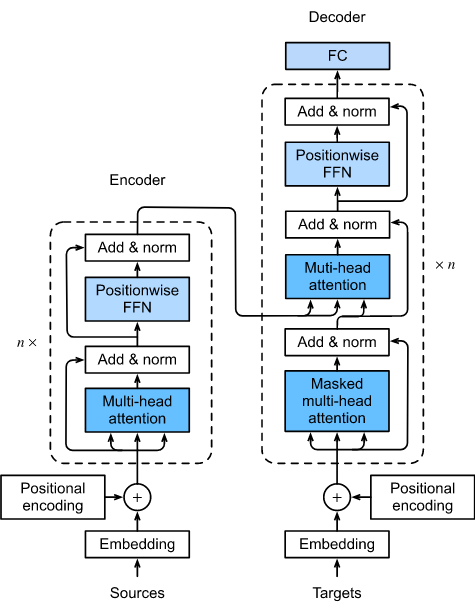
图10.7.1 transformer 的结构。
现在我们提供图10.7.1中transformer结构的概述。在较高的级别上,transformer encoder是由多个相同层堆叠而成,其中每个层都有两个子层(表示为sublayer)。第一个是multi-head self-attention pooling,第二个是positionwise feed-forward network。具体来说,在encoder self-attention 中,queries, keys, 和 values都来自前一个encoder层的输出。受第7.6节ResNet设计的启发, 在两个子层周围都采用了残差连接。在 transformer 中, 对于序列在任意位置的任意输入 $x \in \mathbb{R}^d$, 我们需要 $sublayer(x) \in \mathbb{R}^d$ 使得残差连接 $x + sublayer(x) \in \mathbb{R}^d$ 可行。 残差连接的添加在层归一化[Ba等人,2016]后。因此,transformer encoder为输入序列的每个位置输出 $d$ 维的向量表示。
transformer decoder也是具有残差连接和层归一化的多个相同层的堆叠。除encoder中所述的两个子层外,decoder在这两个子层之间插入第三个子层,称为encoder-decoder注意力层。在encoder-decoder attention中,queries来自前一个decoder层的输出,而keys和values来自transformerencoder的输出。在decoder self-attention中,queries、keys和values都来自前一个decoder层的输出。然而,decoder中的每个位置被允许只关注decoder中直至该位置的所有位置。这种masked attention保留了自回归属性,确保预测只依赖于已经生成的输出tokens。
我们已经在第10.5节和第10.6.3节描述并实现了基于scaled dot-products的multi-head attention和positional encoding。下面,我们将实现transformer模型的其余部分。
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
Positionwise Feed-Forward Networks
positionwise feed-forward network 在所有 序列位置 使用相同的MLP 转换表征。 这是为什么我们叫它 positionwise。在下面的实现中,具有形状的input X (batch size, time steps number or sequence length In tokens, hidden units number or feature dimension)将通过两层MLP转换为形状为(batch size, time steps number, ffn num outputs)的输出张量。
class PositionWiseFFN(nn.Module):
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
下面的例子展示了张量的最内层维数改变为positionwise feed-forward network的输出数。由于相同的MLP在所有位置进行转换,当所有这些位置的输入相同时,它们的输出也相同。
输出:
tensor([[-0.9460, 0.5965, -0.4089, 0.3745, -0.8109, -0.7892, -1.0203, 0.0239],
[-0.9460, 0.5965, -0.4089, 0.3745, -0.8109, -0.7892, -1.0203, 0.0239],
[-0.9460, 0.5965, -0.4089, 0.3745, -0.8109, -0.7892, -1.0203, 0.0239]],
grad_fn=<SelectBackward>)
在这里, 位置编码是学出来的。
Residual Connection and Layer Normalization
现在让我们关注图10.7.1中的 “add & norm” 组件。正如我们在本节开始时所描述的,这是紧接着层规范化之后的残差连接。两者都是深层结构有效的关键。
在第7.5节中,我们解释了 batch normalization 如何在 minibatch 中跨样本 recenters和rescales。Layer normalization 与 batch normalization 相同,只是前者是 跨特征维度规范化。尽管batch normalization在计算机视觉中的广泛应用,但在自然语言处理任务中,其效率通常低于layer normalization,这些任务的输入通常是变长序列。
下面的代码片段按layer normalization 和 batch normalization 比较了不同维度上的标准化。
ln = nn.LayerNorm(2)
bn = nn.BatchNorm1d(2)
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
# Compute mean and variance from `X` in the training mode
print('layer norm:', ln(X), '\nbatch norm:', bn(X))
输出:
layer norm: tensor([[-1.0000, 1.0000],
[-1.0000, 1.0000]], grad_fn=<NativeLayerNormBackward>)
batch norm: tensor([[-1.0000, -1.0000],
[ 1.0000, 1.0000]], grad_fn=<NativeBatchNormBackward>)
现在,我们可以使用残差连接实现 AddNorm 类,然后进行层规范化。Dropout也用于正则化。
class AddNorm(nn.Module):
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
残差连接要求两个输入具有相同的形状,以便在加法运算后输出张量也具有相同的形状。
add_norm = AddNorm([3, 4], 0.5) # Normalized_shape is input.size()[1:]
add_norm.eval()
add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4))).shape
输出:
torch.Size([2, 3, 4])
Encoder
有了 transformer encoder的所有基本组件后,让我们先在encoder内实现一个单层。下面的EncoderBlock类包含两个子层:multi-head self-attention 和 positionwise feed-forward networks, 其中两个sublayer使用一个残差连接跟在layer normalization之后。
class EncoderBlock(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(key_size, query_size,
value_size, num_hiddens,
num_heads, dropout, use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
正如我们所看到的,transformerencoder中的所有层都不会改变其输入的形状。
X = torch.ones((2, 100, 24))
valid_lens = torch.tensor([3, 2])
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
encoder_blk(X, valid_lens).shape
输出:
torch.Size([2, 100, 24])
在下面的 transformer encoder实现中,我们堆叠 num_layers 个上述EncoderBlock类的实例。由于我们使用固定位置编码,其值总是在-1和1之间,因此在将输入embedding和位置编码相加之前, 我们将可学习的输入embeddings乘以embedding维数的平方根来重新缩放。
class TransformerEncoder(d2l.Encoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
# 位置编码信息
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(
"block" + str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
# Since positional encoding values are between -1 and 1, the embedding values are multiplied by the square root of the embedding dimension to rescale before they are summed up
#
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[
i] = blk.attention.attention.attention_weights
return X
下面我们指定超参数来创建一个两层 transformer encoder。transformerencoder输出的形状为 (batch size, number of time steps, num_hiddens)。
encoder = TransformerEncoder(200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
encoder(torch.ones((2, 100), dtype=torch.long), valid_lens).shape
torch.Size([2, 100, 24])
Decoder
如图10.7.1所示,transformerdecoder由多个identical层组成。 每一层都在以下DecoderBlock类中实现,它包含三个子层:decoder self-attention、encoder-decoder attention和positionwise feed-forward networks。这些子层使用其附近的残差连接,然后进行层规范化。
正如我们在本节前面描述的,在masked multi-head decoder 的自注意力(第一子层)中,queries、keys和values都来自前一个decoder层的输出。当训练序列到序列模型时,输出序列的所有位置(时间步)上的 tokens 都是已知的。然而,在预测过程中,输出序列是逐个token生成的; 因此,在任何decoder的时间步中,只有生成的tokens可以用于decoder的自注意力。为了在decoder中保留自回归,其掩masked self-attention 指定了dec_valid_lens,以便任何 query 只关注decoder中直到 query位置 的所有位置。
class DecoderBlock(nn.Module):
# The `i`-th block in the decoder
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = d2l.MultiHeadAttention(key_size, query_size,
value_size, num_hiddens,
num_heads, dropout)
self.addnorm1 = d2l.AddNorm(norm_shape, dropout)
self.attention2 = d2l.MultiHeadAttention(key_size, query_size,
value_size, num_hiddens,
num_heads, dropout)
self.addnorm2 = d2l.AddNorm(norm_shape, dropout)
self.ffn = d2l.PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm3 = d2l.AddNorm(norm_shape, dropout)
def forward(self, X, state):
"""
args:
X : input
state : (enc_outputs, enc_valid_lens, representations of the decoded output up to the current time step)
return:
output : decoder block 的输出
state : enc_outputs, enc_valid_lens,
"""
enc_outputs, enc_valid_lens = state[0], state[1]
# During training, all the tokens of any output sequence are processed at the same time, so `state[2][self.i]` is `None` as initialized.
# When decoding any output sequence token by token during prediction, `state[2][self.i]` contains representations of the decoded output at the `i`-th block up to the current time step
if state[2][self.i] is None:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
if self.training:
batch_size, num_steps, _ = X.shape
# Shape of `dec_valid_lens`: (`batch_size`, `num_steps`), where every row is [1, 2, ..., `num_steps`]
dec_valid_lens = torch.arange(1, num_steps + 1,
device=X.device).repeat(batch_size, 1)
else:
dec_valid_lens = None
# Self-attention
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# Encoder-decoder attention. Shape of `enc_outputs`:
# (`batch_size`, `num_steps`, `num_hiddens`)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
为了便于在encoder-decoder注意中进行scaled dot-product 操作,在残差连接中进行加法操作,decoder的特征维数(num_hiddens)与encoder相同。
decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
decoder_blk.eval()
X = torch.ones((2, 100, 24))
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
decoder_blk(X, state)[0].shape
输出:
torch.Size([2, 100, 24])
现在我们构造由 num_layers 层 DecoderBlock 类的实例组成的整个 transformer decoder。最后,一个全连接的层计算所有可能输出 tokens 的词汇表大小的预测。decoder的 self-attention 权值和encoder-decoder attention 权值都被存储起来以供以后的可视化使用。
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module(
"block" + str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
"""
args:
enc_outputs : 编码器的输出
enc_valid_lens : 编码器的输入
return:
state : enc_outputs, enc_valid_lens, [None] * self.num_layers]
"""
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range(2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
# Decoder self-attention weights
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# Encoder-decoder attention weights
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
Training
让我们通过 transformer 结构来实例化一个encoder-decoder模型。这里我们指定 transformer encoder 和 transformer decoder 有 2 层使用 4-head 注意力。与第9.7.4节相似,我们在 English-French 机器翻译数据集上训练 transformer 模型进行序列到序列学习。
输出:
loss 0.031, 4786.0 tokens/sec on cuda:0
训练结束后,我们使用 transformer 模型将一些英语句子翻译成法语,并计算它们的BLEU分数。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
输出:
go . => va !, bleu 1.000
i lost . => j’ai fait signe ., bleu 0.000
he's calm . => il est calme ., bleu 1.000
i'm home . => je suis chez moi ., bleu 1.000
让我们把最后一个英语句子翻译成法语时的 transformer 注意力权重可视化。encoderself-attention 权重的形状为 (number of encoder layers, number of attention heads, num_steps or number of queries, num_steps or number of key-value pairs)。
enc_attention_weights = torch.cat(net.encoder.attention_weights, 0).reshape((num_layers, num_heads, -1, num_steps))
enc_attention_weights.shape
输出:
torch.Size([2, 4, 10, 10])
在encoder的self-attention中,queries 和 keys 都来自相同的输入序列。由于填充 tokens 不携带意义,在指定输入序列的有效长度时,没有 query 涉及填充 tokens 的位置。接下来, multi-head attention 权重逐行呈现。每个head根据queries、keys和values的单独表示子空间 独立参与。
d2l.show_heatmaps(enc_attention_weights.cpu(), xlabel='Key positions',
ylabel='Query positions',
titles=['Head %d' % i
for i in range(1, 5)], figsize=(7, 3.5))
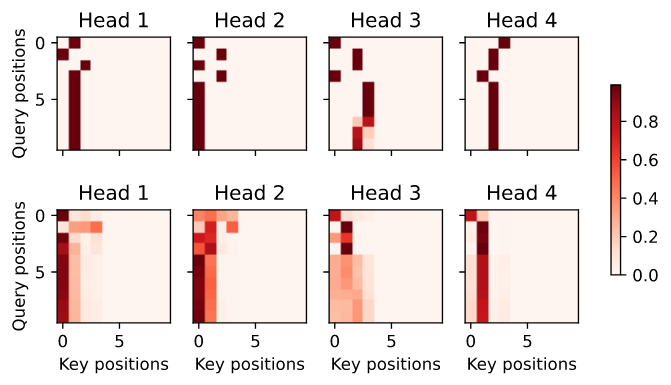
为了将decoder的 self-attention 权重 和 encoder-decoder 的注意力权重可视化,我们需要更多的数据操作。例如,我们用零填充masked注意力权重。注意,decoder self-attention 和encoder-decoder attention 权重都具有相同的queries : the beginning-of-sequence token followed by the output tokens。
dec_attention_weights_2d = [
head[0].tolist() for step in dec_attention_weight_seq for attn in step
for blk in attn for head in blk]
dec_attention_weights_filled = torch.tensor(
pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values)
dec_attention_weights = dec_attention_weights_filled.reshape(
(-1, 2, num_layers, num_heads, num_steps))
dec_self_attention_weights, dec_inter_attention_weights = \
dec_attention_weights.permute(1, 2, 3, 0, 4)
dec_self_attention_weights.shape, dec_inter_attention_weights.shape
输出:
(torch.Size([2, 4, 6, 10]), torch.Size([2, 4, 6, 10]))
由于decoder self-attention的自回归特性,没有 query 关注 query 位置后的 key-value 对。
# Plus one to include the beginning-of-sequence token
d2l.show_heatmaps(
dec_self_attention_weights[:, :, :, :len(translation.split()) + 1],
xlabel='Key positions', ylabel='Query positions',
titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))

与encoder self-attention的情况类似,通过指定输入序列的有效长度,输出序列的 query 不会关注输入序列中的填充 tokens。
d2l.show_heatmaps(dec_inter_attention_weights, xlabel='Key positions',
ylabel='Query positions',
titles=['Head %d' % i
for i in range(1, 5)], figsize=(7, 3.5))
虽然 transformer 结构最初是为序列到序列学习而提出的,但正如我们将在本书后面发现的那样,transformer encoder 或 transformer decoder通常分别用于不同的深度学习任务。
Summary
- transformer 是 encoder-decoder 结构的一个实例,但实际上 encoder 或 decoder 都可以单独使用。
- 在transformer中,尽管 decoder 必须通过一个 masked version 来保持自回归属性, 但输入序列和输出序列均采用 multi-head self-attention 表示。
- transformer的残差连接和层规范化对于训练一个非常深入的模型是很重要的。
- transforms 模型中的 positionwise feed-forward network 使用相同的MLP变换所有序列位置的表示。
Exercises
- 在实验中训练一个更深层的 transformer。它是如何影响训练速度和翻译性能的?
- 在 transformer 中用 additive attention 来代替 scaled dot-product attention 是一个好主意吗?为什么?
- 对于语言建模,我们应该使用transformer encoder、decoder,还是两者都使用? 如何设计这种方法?
- 如果输入序列很长,transformers 会面临什么挑战?为什么?
- 如何提高 transformers 的计算和存储效率? 提示: 你可以参考Tay等人的综述论文[Tay等人,2020]。
- 我们如何在不使用CNNs的情况下为图像分类任务设计基于transformer的模型? 提示: 你可以参考vision transformer[Dosovitskiy等人,2021]。