各种脸型的含义
全脸,中脸,半脸

猴哥没长毛的地方就是半脸,加上长毛的地方就是全脸,中脸比半脸多百分之三十左右的脸。

从左到有分别是半脸,中脸,全脸。越往右脸部面积越大。
不管哪种脸,都不包含额头,这就导致了,肤色问题,脸的颜色和额头颜色不一样,有一种割裂感,比如我训练的托尼老师。

上面黑,下面白。 这个问题可以通过风格迁移加上模糊运算解决。 在合成之间训练半个小时到一个小时面部的风格迁移。 再风格迁移之前,先保存一下模型,风格迁移可能会把模型破坏掉,脸变绿,脸型发生变化等等。这个不是必要的,也可以直接尝试模糊运算。
在合成之前,对mask进行模糊运算,可以让假脸和额头等部分过渡更加自然。
肤色的问题可以尝试风格迁移,或者合成时加上rct,lct等参数。
各种模型的不同
(1). AVATAR
这个模型的主要目的是换头,效果类似你做什么表情,被换的就做什么表情。你需要一个类似新闻播放一样的素材,然后素材的分辨率比例应该是相同的,配置要求比较高,使用较有难度,目前效果比较渣,不推荐使用。
(2). H64
H64这个模型是通用性最高的一种半脸模型,但是效果相对来说也比较差。64代表的是头像的分辨率是64px *64px,换出来的中近镜头会比较模糊,H64默认参数需要3G显存,如果开启Use lightweight autoencoder(轻量级)2G显存即可。
(3). H128
H128模型和H64的内部结构是一样的,只是这个模型的分辨率为128*128px,所以相对来说会更清晰一些,但是特写也是不要指望会有多好的效果。H128默认参数需要6G显存,H128Use lightweight autoencoder(轻量级)就只需要4G显存。
(4). DF
DF是一种全脸模型,不同于H64和H128的半脸模型(半脸可以大概理解为眉毛到嘴巴的区域),那么什么是全脸呢?可以大概理解为从眉毛上面一点点到下巴以上的区域,DF要求显存6G为宜。
(5). LIAEF128
LIAEF128是类似于DF的一种全脸模型,但是这个模型最大的问题在于它会改变你的SRC(替换者)的脸型,这样最终换出来的结果可能会不大逼真,比较适合脸型相近的面部之间进行。
(6). SAE
一个由多层编码器组成的网络模型,SAE可以自定义搭配出来任何的模型,因为它的参数非常多,你可以自由搭配组合,而且SAE模型最大的优势在于它会有一些“无中生有”的神奇感,默认分辨率是128*128px,理论上2G显存也可以玩,推荐6G显存。
(7). SAEHD
最新的模型,新的编码器,更好的效果,带来的是更多的时间!SAEHD类似于SAE模型,同样也是参数众多,可以自定义搭配出各种模型,比SAE模型最大的区别在于使用了新的编码器和增加了“True Face”模式,第一次训练的时候默认使用CA权重,好的效果需要好的显卡,推荐6G显存使用。 True face推荐最后三万次迭代再开启。
模型训练的参数
(1). H64 H128 DF

Enable autobackup? (y/n ?:help skip:n) :
自动备份模型,一小时备份一次,开启会自动备份最近15次模型。
Write preview history? (y/n ?:help skip:n) :
每10秒自动在model / history文件夹生成一张预览图。
Target iteration (skip:unlimited/default) :
训练次数,推荐默认设置。
Batch_size (?:help skip:0) :
Batch_size数值,一次有多少图像被发送到神经网络训练。
Feed faces to network sorted by yaw? (y/n ?:help skip:n) :
偏航排序,data_dst和data_src素材种类一致可以开启。 默认开启,建议不开启。
Flip faces randomly? (y/n ?:help skip:y) :
随机翻转脸部,data_src素材丰富时关闭会更自然,反之效果很差。 默认开启,建议开启。
Src face scale modifier % ( -30…30, ?:help skip:0) :
data_src面部比例大小,输入数值会改变data_src脸部大小。
Use lightweight autoencoder? (y/n, ?:help skip:n) :
是否使用轻量级编码模式,配置较低时使用,牺牲部分质量。
Use pixel loss? (y/n, ?:help skip: n/default ) :
是否使用像素丢失。开启后能增强细节,比如牙齿或其它需要增强的细节,但不宜过量,可以在合成之前开启一段时间。否则将有可能使模型损坏。
(2). SAE SAEHD

Resolution ( 64-256 ?:help skip:128) :
默认128pix,建议普通视频默认分辨率即可,追求特写脸部可以尝试192或者256pix.
Learn mask? (y/n, ?:help skip:y ) :
学习掩膜。脸部边缘更贴合。默认开启。不建议开启,或者建议训练一万步后关闭以增加效率。后期合成时使用FAN-dst遮罩更佳。
Optimizer mode? ( 1,2,3 ?:help skip:1) :
默认选项1为不打开。2 为训练网络x2,需要更多系统内存。3 为训练网络x3更大,需要更多系统内存和CPU处理器。数值越大训练越慢。
AE architecture (df, liae ?:help skip:df) :
神经网络结构类型, 默认df,建议df.
AutoEncoder dims (32-1024 ?:help skip:256) :
网络维度数值大小,数值越大细节越准确,也越需要更高的硬件配置。
Encoder/Decoder dims per channel (10-85 ?:help skip:21) :
解码器维数。越大效果越好,也越需要更高的硬件配置。 默认21,建议21,但如果分辨率提高也应提高。
Use CA weights? (y/n, ?:help skip:n ) :
是否使用CA权重,开启会更精准。(SAEHD默认开启)
Use pixel loss? (y/n, ?:help skip:n ) :
是否使用像素丢失。开启后能增强细节,比如牙齿或其它需要增强的细节,但不宜过量,可以在合成之前开启一段时间。否则将有可能使模型损坏。
Enable random warp of samples? ( y/n, ?:help skip:y) :
是否使用随机扭曲。 默认开启,建议开启。后期可以关闭,使效果更准确。
Face style power ( 0.0 .. 100.0 ?:help skip:0.00) :
学习人物风格,体现在面部细节和光照。 默认不开启,建议合成之前开启,数值不宜过大。 这个在模型训练完毕后,对模型进行备份。然后启用这个调节脸部颜色,需要变的颜色越多值越大,一般半小时到一小时就可以了。
Background style power ( 0.0 .. 100.0 ?:help skip:0.00) :
学习人物背景风格,体现在边缘。 默认不开启,建议合成之前开启,数值不宜过大。 这个在模型训练完毕后,对模型进行备份。然后启用这个调节脸部边缘的颜色,需要变的颜色越多值越大,一般半小时到一小时就可以了。
Color transfer mode apply to src faceset. ( none/rct/lct/mkl/idt/sot, ?:help skip:none) :
更改接近dst样本的src样本的颜色分布。尝试所有模式去找到最佳模式(可以参考合成的颜色调整经验)。老版本默认是lct,在一些数据集上表现并不好。
Enable gradient clipping? (y/n, ?:help skip:n) :
是否开启梯度剪切。使用会减少模型损坏几率,但会影响效率。 默认不开启,建议中后期开启防止模型崩溃。
Pretrain the model? (y/n, ?:help skip:n) :
是否使用预训练,开启预训练会使用_internal\pretrain_CelebA文件夹下的24711个脸部图片进行训练,适当训练可以达到一个尚可的角度值。 默认不开启,不建议过度预训练,如开启可训练1-10万迭代后正式训练。
FAN-X
 希亚·拉博夫的手指被托尼的脸给覆盖了。这显然不是我们要的结果。我们希望的是手指能露出来,但是脸是托尼的。
希亚·拉博夫的手指被托尼的脸给覆盖了。这显然不是我们要的结果。我们希望的是手指能露出来,但是脸是托尼的。
将遮罩模式(Mask mode)切换成 Fan-dst

可以非常清楚的看到,手指出来了,脸往后贴了

FAN-X背后的原理
FAN的实现主要体现在FANSegmentator,而这个FANSegmentator其实是基于TernausNet。
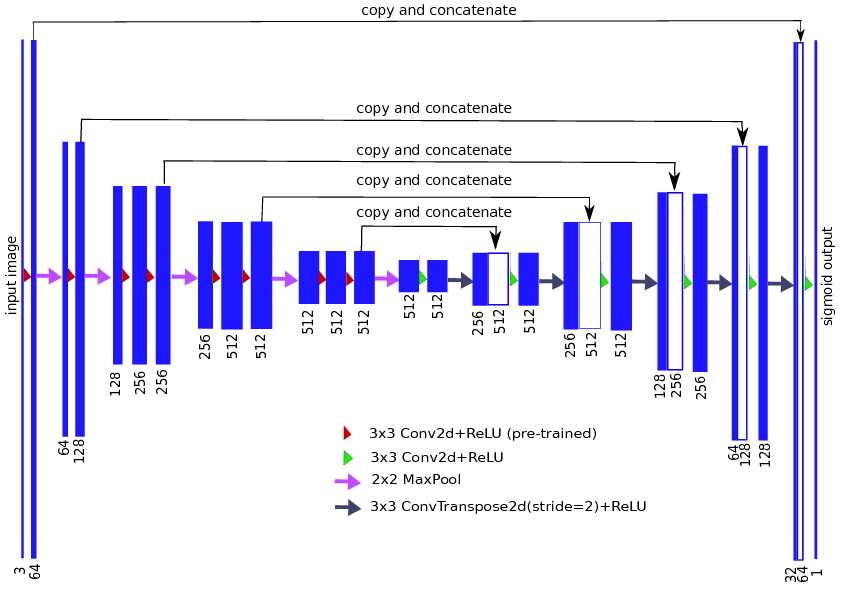
大概意思是,这是一个使用Vgg11编码器的U-NET网络,使用ImageNet进行了预训练,主要应用于图像分割。
convert mode
合成模式其实主要可以分为3类:overlay,histmatch,seamless
overlay
可以简单的理解为叠加覆盖。在DFL中有不少人喜欢使用这个模式,但是这个模型往往让人感觉有一层淡淡薄膜,最终导致“脸色”不是太好。
seamless
泊松图像编辑是一种全自动的“无缝融合”技术,由Microsoft Research UK的Patrick Perez,Michel Gangnet, and Andrew Blake在论文“Poisson Image Editing”中首次提出。opencv3.0 photo 模块加入了seamless_cloning类。


但是用在DFL中,并不是非常理想。首先他很容易出现类似“乌云密布”的感觉,就是脸上偏灰色,偏暗淡。还有合成视频时候容易出现闪烁,也有人描述成抖动。不过当遇到遮挡的时候,似乎这种算法出来的结果最佳,对于单图的处理结果往往也不错。
histmatch
直方图匹配又称为直方图规定化,是指将一幅图像的直方图变成规定形状的直方图而进行的图像增强方法。即将某幅影像或某一区域的直方图匹配到另一幅影像上。使两幅影像的色调保持一致。可以在单波段影像直方图之间进行匹配,也可以对多波段影像进行同时匹配。两幅图像比对前,通常要使其直方图形式一致。

在DFL中的表现还是非常不错的。从图中看以看出来,两张脸的色彩非常接近,这一点其实很重要。
Reference
- 一张图看懂DeepFaceLab的全脸,中脸,半脸!
- 选择合适的模型 H64 -H128 -DF -SAE -SAEHD
- DeepFaceLab不同模型的参数含义
- deepfacelab SAE SAEHD模型训练参数详解
- https://github.com/ternaus/TernausNet
- https://arxiv.org/abs/1801.05746