论文部分
Ian Goodfellow大牛的Generative Adversarial Networks[1],这篇paper算是这个领域的开山之作。
结构
GAN有一个生成器G(Generator)和一个判决器D(Discriminator)。
生成器使用高斯噪声Z作为原材料,生成出真实数据的假数据。
判决器判决收到的数据是真实数据,还是假数据。

在论文中有这样一个比喻
The generative model can be thought of as analogous to a team of counterfeiters, trying to produce fake currency and use it without detection, while the discriminative model is analogous to the police, trying to detect the counterfeit currency.
将生成器比喻成伪造者, 将判决器比喻成警察。
参数含义
$p_g(z)$:生成器G关于噪声z的一个概率密度 $p_z(z)$:噪声z的概率密度,一般是高斯分布 $G(z; θ_g)$:关于参数$θ_g$,输入为z的分布函数 $D(x; θ_d)$:关于参数$θ_d$,输入为x的分布函数
这里将参数讲成概率密度和分布函数我是心虚的,可能有失偏颇,先这么理解吧。
任务的目标是 \(\min_G \max_D V(D, G) =E_{x\thicksim p_{data}(x)}[logD(x)] + E_{z\thicksim{p_z}(z)}[log(1-D(G(z)))]\) 可以看作是目标是取到判决器极大值中生成器的极小值。
训练判决器时的损失函数:
\[D_{loss} = E_{x\thicksim p_{data}(x)}[logD(x)] + E_{z\thicksim{p_z}(z)}[log(1-D(G(z)))]\]训练生成器时的损失函数: \(G_{loss} = E_{z\thicksim{p_z}(z)}[log(1-D(G(z)))]\)
实现部分
引入相关的包
1
2
3
4
5
6
7
8
# coding=utf-8
import torch.autograd
import torch.nn as nn
from torch.autograd import Variable
from torchvision import transforms
from torchvision import datasets
from torchvision.utils import save_image
import os
引入相关的包,其中相关API的使用可以参考【机器学习】PyTorch学习笔记,可能不是特别完善,以后会继续完善。
算了我这个太垃圾了,还是推荐PyTorch中文文档吧。
创建文件夹
1
2
3
# 创建文件夹
if not os.path.exists('./img'):
os.mkdir('./img')
检测当前文件夹下是否有img这个文件夹,如果没有,就创建这个文件夹。
将一维输出转成图像
1
2
3
4
5
def to_img(x):
out = 0.5 * (x + 1)
out = out.clamp(0, 1) # Clamp函数可以将随机变化的数值限制在一个给定的区间[min, max]内:
out = out.view(-1, 1, 28, 28) # view()函数作用是将一个多行的Tensor,拼接成一行
return out
输入的x是一个Variable类型的数,这个数由img原始数据拉成一维组成,clamp是Variable的一个方法,将数值限定在一定范围。
view的作用是返回一个有相同数据但大小不同的tensor。 返回的tensor必须有与原tensor相同的数据和相同数目的元素,但可以有不同的大小。 参数-1表示该维度的数值,由其他维度决定,比如一个4x4的矩阵,view(-1,8),那么-1的地方就是代表着2。 这里的注释应该是写错了,这里view的作用是将将输入x的维度拉成28x28。
值得注意的是Variable类在Pytorch-0.4.0版本中已经和Tensor类合并,已经被废弃,但仍然可以用。
新版本中,torch.autograd.Variable 和 torch.Tensor 将同属一类。更确切地说,torch.Tensor 能够追踪日志并像旧版本的 Variable 那样运行; Variable 封装仍旧可以像以前一样工作,但返回的对象类型是 torch.Tensor。这意味着你的代码不再需要变量封装器。
图像预处理
1
2
3
4
5
6
7
8
batch_size = 128
num_epoch = 100
z_dimension = 100
# 图像预处理
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # (x-mean) / std
])
class torchvision.transforms.Normalize(mean, std) 给定均值:(R,G,B) 方差:(R,G,B),将会把Tensor正则化。即:Normalized_image=(image-mean)/std。
按理说,nean和std应该传入两个三维的list。一般pytorch的教程都这么做
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
他这里传入了一个tuple 以下来自廖雪峰的Python教程使用list和tuple
当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来 如果要定义一个空的tuple,可以写成() 要定义一个只有1个元素的tuple,如果你这么定义t = (1), 定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。 所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义 Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
也就是说他这里仅传入了一个一维的tuple,不知该怎么解释。 私以为他输出转出的维度是一维,所以仅标准化了第一维。
加载数据集
1
2
3
4
5
6
7
8
9
10
# mnist dataset mnist数据集下载
mnist = datasets.MNIST(
root='./data/', train=True, transform=img_transform, download=True
)
# data loader 数据载入
dataloader = torch.utils.data.DataLoader(
dataset=mnist, batch_size=batch_size, shuffle=True
)
定义判决器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 定义判别器 #####Discriminator######使用多层网络来作为判别器
# 将图片28x28展开成784,然后通过多层感知器,中间经过斜率设置为0.2的LeakyReLU激活函数,
# 最后接sigmoid激活函数得到一个0到1之间的概率进行二分类。
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.dis = nn.Sequential(
nn.Linear(784, 256), # 输入特征数为784,输出为256
nn.LeakyReLU(0.2), # 进行非线性映射
nn.Linear(256, 256), # 进行一个线性映射
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid() # 也是一个激活函数,二分类问题中,
# sigmoid可以班实数映射到【0,1】,作为概率值,
# 多分类用softmax函数
)
def forward(self, x):
x = self.dis(x)
return x
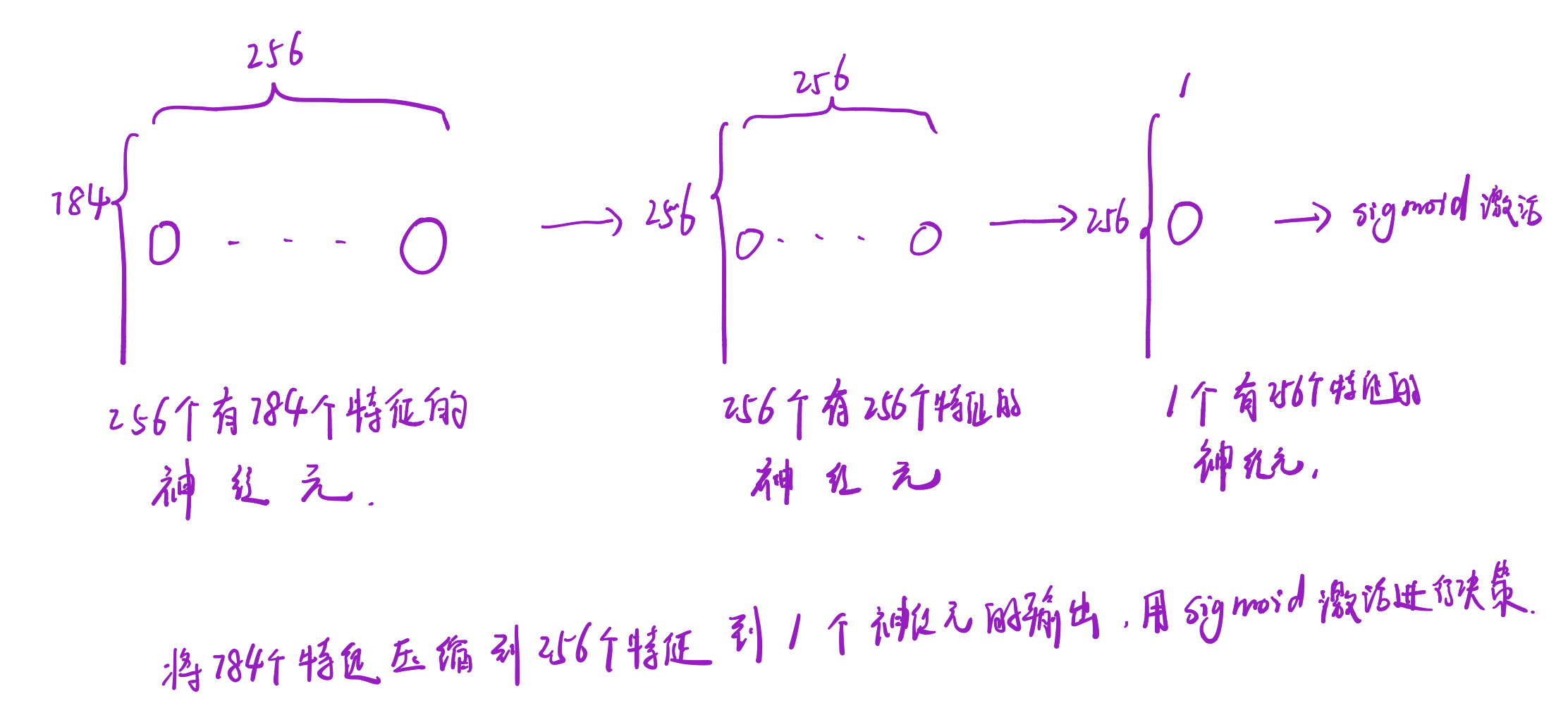
这里我觉得用一张图表示更清晰,不知道描述的对不对,如果有差错的地方,希望大家能多多指正。
定义生成器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# ###### 定义生成器 Generator #####
# 输入一个100维的0~1之间的高斯分布,然后通过第一层线性变换将其映射到256维,
# 然后通过LeakyReLU激活函数,接着进行一个线性变换,再经过一个LeakyReLU激活函数,
# 然后经过线性变换将其变成784维,最后经过Tanh激活函数是希望生成的假的图片数据分布
# 能够在-1~1之间。
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.gen = nn.Sequential(
nn.Linear(100, 256), # 用线性变换将输入映射到256维
nn.ReLU(True), # relu激活
nn.Linear(256, 256), # 线性变换
nn.ReLU(True), # relu激活
nn.Linear(256, 784), # 线性变换
nn.Tanh() # Tanh激活使得生成数据分布在【-1,1】之间,因为输入的真实数据的经过transforms之后也是这个分布
)
def forward(self, x):
x = self.gen(x)
return x
这个过程和上面类似,将100个特征的输入,经过网络后输出成784个特征的输出
训练准备
1
2
3
4
5
6
7
# 创建对象
D = discriminator()
G = generator()
if torch.cuda.is_available():
D = D.cuda()
G = G.cuda()
首先创建对象,将数据送入GPU
1
2
3
4
5
# 首先需要定义loss的度量方式 (二分类的交叉熵)
# 其次定义 优化函数,优化函数的学习率为0.0003
criterion = nn.BCELoss() # 是单目标二分类交叉熵函数
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)
定义损失函数和优化器
训练判决器
1
2
3
4
5
6
7
8
9
10
11
# ##########################进入训练##判别器的判断过程#####################
for epoch in range(num_epoch): # 进行多个epoch的训练
for i, (img, _) in enumerate(dataloader):
num_img = img.size(0)
# view()函数作用是将一个多行的Tensor,拼接成一行
# 第一个参数是要拼接的tensor,第二个参数是-1
# =============================训练判别器==================
img = img.view(num_img, -1) # 将图片展开为28*28=784
real_img = Variable(img).cuda() # 将tensor变成Variable放入计算图中
real_label = Variable(torch.ones(num_img)).cuda() # 定义真实的图片label为1
fake_label = Variable(torch.zeros(num_img)).cuda() # 定义假的图片的label为0
注意这里的label是将每个像素点都打了label。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# ########判别器训练train#####################
# 分为两部分:1、真的图像判别为真;2、假的图像判别为假
# 计算真实图片的损失
real_out = D(real_img) # 将真实图片放入判别器中
d_loss_real = criterion(real_out, real_label) # 得到真实图片的loss
real_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好
# 计算假的图片的损失
z = Variable(torch.randn(num_img, z_dimension)).cuda() # 随机生成一些噪声
fake_img = G(z).detach() # 随机噪声放入生成网络中,生成一张假的图片。 # 避免梯度传到G,因为G不用更新, detach分离
fake_out = D(fake_img) # 判别器判断假的图片,
d_loss_fake = criterion(fake_out, fake_label) # 得到假的图片的loss
fake_scores = fake_out # 得到假图片的判别值,对于判别器来说,假图片的损失越接近0越好
# 损失函数和优化
d_loss = d_loss_real + d_loss_fake # 损失包括判真损失和判假损失
d_optimizer.zero_grad() # 在反向传播之前,先将梯度归0
d_loss.backward() # 将误差反向传播
d_optimizer.step() # 更新参数
这里有几个比较关键的参数 real_out: 真实图片送入判决器D的输出 d_loss_real:利用loss函数计算判决器D对于真图片的损失 real_scores:这里的值其实和real_out相等,因为经过sigmoid激活,所以值在0~1之间。 fake_out:将高斯噪声Z送如生成器G得到的输出 d_loss_fake:利用loss函数计算判决器D对于假图片的的损失 fake_scores:这里的值其实和fake_out相同,因为经过tanh激活,所以值在-1~1之间 d_loss:就是d_loss_real和d_loss_fake相加的值 回忆一下这个公式 \(\min_G \max_D V(D, G) =E_{x\thicksim p_{data}(x)}[logD(x)] + E_{z\thicksim{p_z}(z)}[log(1-D(G(z)))]\)
训练生成器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# ==================训练生成器============================
# ###############################生成网络的训练###############################
# 原理:目的是希望生成的假的图片被判别器判断为真的图片,
# 在此过程中,将判别器固定,将假的图片传入判别器的结果与真实的label对应,
# 反向传播更新的参数是生成网络里面的参数,
# 这样可以通过更新生成网络里面的参数,来训练网络,使得生成的图片让判别器以为是真的
# 这样就达到了对抗的目的
# 计算假的图片的损失
z = Variable(torch.randn(num_img, z_dimension)).cuda() # 得到随机噪声
fake_img = G(z) # 随机噪声输入到生成器中,得到一副假的图片
output = D(fake_img) # 经过判别器得到的结果
g_loss = criterion(output, real_label) # 得到的假的图片与真实的图片的label的loss
# bp and optimize
g_optimizer.zero_grad() # 梯度归0
g_loss.backward() # 进行反向传播
g_optimizer.step() # .step()一般用在反向传播后面,用于更新生成网络的参数
关键参数: z: 高斯噪声 fake_img: 由生成器生成的假图像 output:判决器得到的结果 g_loss:生成器的loss
问题 为什么不生成器和判决器一起训练? 为什么训练判决器时加上了fake_img的loss却不把生成器一起训练了? 注意生成器训练和判决器训练中的fake_img的标签是不一样的,所以loss也是不一样的。
打印及保存结果
1
2
3
4
5
6
7
8
9
10
11
12
# 打印中间的损失
if (i + 1) % 100 == 0:
print('Epoch[{}/{}],d_loss:{:.6f},g_loss:{:.6f} '
'D real: {:.6f},D fake: {:.6f}'.format(
epoch, num_epoch, d_loss.data.item(), g_loss.data.item(),
real_scores.data.mean(), fake_scores.data.mean() # 打印的是真实图片的损失均值
))
if epoch == 0:
real_images = to_img(real_img.cpu().data)
save_image(real_images, './img/real_images.png')
fake_images = to_img(fake_img.cpu().data)
save_image(fake_images, './img/fake_images-{}.png'.format(epoch + 1))
保存模型
1
2
3
# 保存模型
torch.save(G.state_dict(), './generator.pth')
torch.save(D.state_dict(), './discriminator.pth')
实验结果
经过100个epoch后,生成MNIST图像如下:
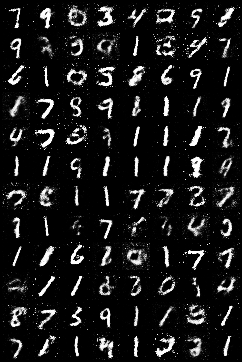
而真实图像如下:
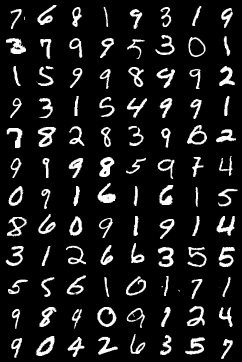
总结
事实上,这个实验复现并不完全是文章的内容。 比如损失函数就不是Paper中的损失函数,应该算是GAN的一种,但不是原文中提出的GAN了。
Reference
- Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in neural information processing systems. 2014: 2672-2680.
- pytorch实现GAN
- 【机器学习】PyTorch学习笔记
- PyTorch中文文档
- 使用list和tuple
- 生成对抗网络Generative Adversarial Nets(译)