Learning with Different Output Space Y
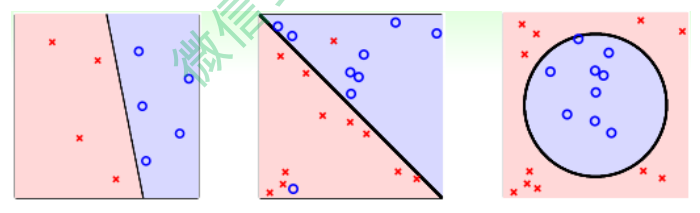
二元分类: 输出只有两个, 一般$y = {-1, +1}$。二元分类是机器学习领域非常核心和基本的问题。
多元分类: 多元分类的输出多于两个, $y = {1, 2, …, K}, K>2$。一般多元分类的应用有数字识别、图片内容识别等。
二元分类和多元分类都属于分类问题, 它们的输出都是离散值。
对于另外一种情况, 比如训练模型、预测房屋价格、股票收益多少等, 这类问题输出$y = R$, 即范围在整个实数空间, 是连续的。 这类问题, 我们把它叫做回归(Regression)。 最简单的线性回归是一种典型的回归模型。

除了分类和回归问题, 在自然语言处理等领域中, 还会用到一种机器学习问题: 结构化学习(Structured Learning)。
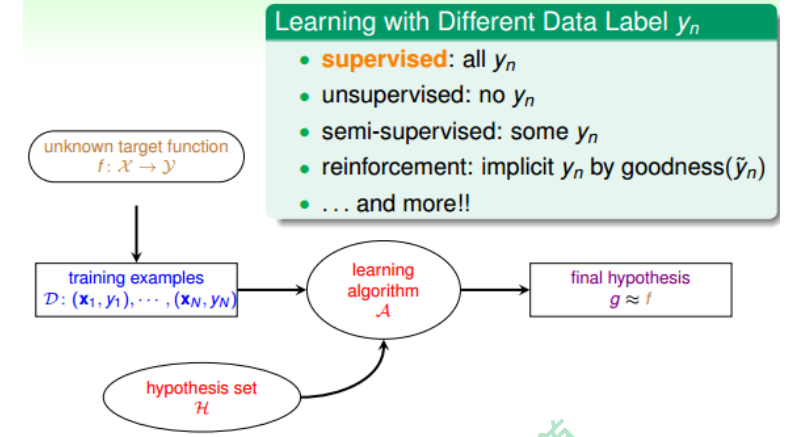
Learning with Different Data Label $y_n$
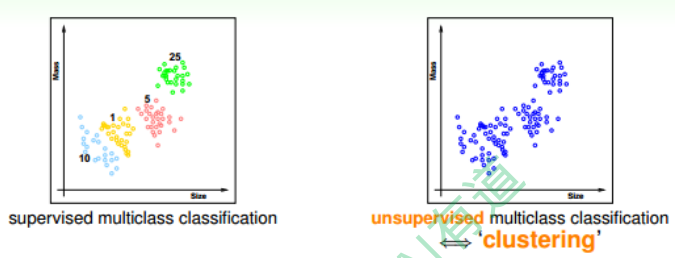
监督学习(Supervised Learning): 如果我们拿到的训练样本D既有输入特征$x$, 也有输出$y_n$, 那么我们把这种类型的学习称为监督式学习。
非监督学习(Unsupervised Learning):非监督学习没有输出标签$y_n$, 典型的非监督学习包括 聚类问题(clustering), 比如对网页上新闻的自动分类; 密度估计, 比如交通路况分析; 异常检测, 比如用户网络流量监测。
半监督学习(Semi-supervised Learning):半监督学习就是一部分数据有输出标签$y_n$, 而另一部分数据没有输出标签$y_n$。比如医药公司对某些药物进行检测, 考虑到成本和实验人群限制等问题, 只有一部分数据有输出标签。
强化学习(Reinforcement Learning):强化学习中,我们给模型或系统一些输入, 但是给不了我们希望的真实的输出y, 根据模型的输出反馈, 如果反馈结果良好, 更接近真实输出, 就给其正向激励, 如果反馈结果不好,偏离真实输出, 就给其反向激励。 不断通过“反馈-修正”这种形式, 一步一步让模型学习的更好, 这就是强化学习的核心所在。 强化学习的例子也很多, 比如根据用户点击、选择而不断改进的广告系统。
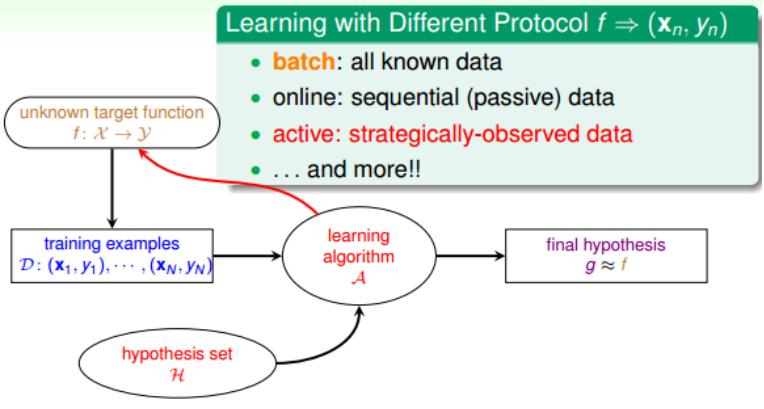
Learning with Different Protocol $f(x_n, y_n)$
按照不同的协议, 机器学习可以分为三种类型:
- Batch Learning
- Online
- Active Learning
Batch Learning:Batch Learning获得的训练数据D是一批的, 即一次性拿到整个D, 对齐进行学习建模, 得到我们最终的机器学习模型。
Online: Online是一种在线学习模型, 数据是实时更新的, 根据数据一个个进来, 同步更新我们的算法。 比如在线邮件过滤系统, 根据一封一封邮件的内容, 根据当前算法判断是否为垃圾邮件, 再根据用户反馈, 既是更新当前算法。 PLA和强化学习都可以使用online模型。
Active Learning: acitve learning 是近年来新出现的一种机器学习类型, 即让机器具备主动问问题的能力, 例如手写数字识别, 机器自己生成一个数值或者对它不确定的手写字主动提问。
Learning with Different Input Space X
Concrete features: 比如硬币分类问题中硬币的尺寸、重量等; 比如疾病诊断中病人信息等具体特征。
Raw features:比如手写数字识别中每个数字所在图面的$m \times n$维像素值; 比如语音信号的频谱等。raw features一般比较抽象, 经常需要人或机器来转换为其对应的concrete features, 这个转换的过程就是Feature Transform。
Abstract features: 比如某购物网站做购买预测时, 给参赛者的时抽象加密过的资料编号或者ID, 这些特征X完全时抽象的, 没有实际的物理意义。 所以对于机器学习来说是比较困难的, 需要对特征进行更多的转换和提取。