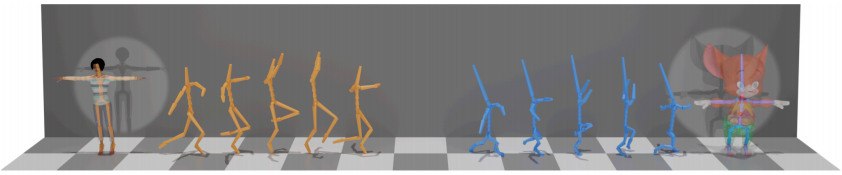
我们引入一种新的深度学习框架, 用于骨骼之间的运动重定位, 骨骼之间可能有不同的结构, 但是它们对应着相同的拓扑的图。重要的是,我们的方法学习了如何重定位,而无需在训练集中的运动之间进行任何明确的配对。
我们利用不同拓扑的骨骼可以使用一系列边缘合并的操作还原为一个通用的原始骨骼, 我们称其为骨骼池化。因此,我们的主要技术贡献是引入了新颖的可微分卷积,池化和解池化运算符。这些运算符具有skeleton-aware,这意味着它们明确地说明了骨骼的层次结构和关节邻接关系,并且它们一起用于将原始运动转化为与原始骨骼的关节相关的深度时间特征的集合。因此,可以简单地通过对该隐空间进行编码和解码来实现目标重定位。我们的实验表明,与现有方法相比,我们的运动重定向和总体处理框架的有效性。我们的方法还在合成数据集上进行了定量评估,该数据集包含应用于不同骨骼的成对运动。 据我们所知,我们的方法是第一个 在没有任何配对示例的情况下,具有不同采样运动链的骨架之间执行重新定位的方法。
INTRODUCTION
捕捉人体运动是运动分析,计算机动画和人机交互中的一项基本任务。运动捕捉(MoCap)系统通常要求表演者佩戴一组标记,这些标记的位置由磁性或光学传感器采样,从而产生3D骨架姿势的时间序列。由于不同的MoCap设置涉及不同的标记配置并使用不同的软件,因此,除了骨骼长度和比例的差异外,所捕获的骨骼在结构和关节数量上可能会有所不同,分别对应于所捕获的不同个体。因此,不仅在同一个MoCap设置中,而且在不同的设置中,为了将捕获的运动从一个关节角色转移到另一个关节角色, 运动重定位都是必要的。
深度神经网络彻底改变了许多计算机视觉任务的最新技术,它利用图像和视频的规则网格表示形式,非常适合卷积和池化操作。与图像不同,不同角色的骨骼表现出不规则的连通性。此外,骨架的结构通常是分层的。这些差异表明,CNN中常用的现有操作符可能不是关节运动分析和合成的最佳选择。在本文中,我们介绍了一个新的运动处理框架,该框架包括针对深度学习设计的铰接式骨骼运动表示形式,以及针对该表示形式进行运算的一些可微分运算符,包括卷积,池化和解池化。运算符具有骨架感知能力,这意味着它们会明确说明骨架结构(层次结构和联合邻接关系)。这些运算符构成了新的深层框架的构建块,其中较浅的层学习关节旋转之间的局部低层关联,而较深的层学习身体部位之间的高层关联。
所提出的运动处理框架可用于各种运动分析和基于合成学习的任务。在这项工作中,我们专注于在具有相同 end-effectors集的骨骼之间进行运动重新定向的任务,但是沿着运动链从根部到这些end-effectors的关节数量可能有所不同。这样的骨架可以由等效拓扑图表示。
尽管运动重定位是一个长期存在的问题,但是当前的方法无法在结构或关节数量不同的骨骼之间自动执行重定目标[Villegas等。 2018]。在这种情况下,应手动指定不同框架之间的对应关系,这通常会导致不可避免的重新定向错误。然后,动画师必须通过操纵关键帧来手动纠正此类错误,这是一个非常繁琐的过程。
我们将目标重定位问题视为未配对域之间的多模态翻译,其中每个域都包含一组由具有不同比例和骨骼长度的骨骼执行的运动集合,这些骨骼共享特定的骨骼结构(一组运动链)。因此,可以使用相同的图来表示给定域中的所有运动。不同的域包含具有不同结构的骨架,即用不同的图表示; 但是,这些图假定为同拓扑结构的。
先前的工作表明,可以使用共享的隐空间有效执行多峰不成对的图像翻译任务[Gonzalez-Garcia et al 2018; Huang et al 2018]。在这些作品中,来自不同域的大小相同的图像被嵌入到一个共享空间中,该共享空间代表了, 例如, 与图像风格无关的图像内容。在图像上,使用标准卷积和池化运算符可以很容易地进行这种嵌入。 但是,对于具有不同结构的骨架却不是这样。 在这项工作中,我们利用我们的骨架感知运动处理框架(特别是骨架池化)将不同骨架执行的运动嵌入到共享的隐域空间中。
我们的关键思想通过合并成对的相邻边界/支架 将骨骼不同 但是拓扑结构相同的骨骼可以化为共同的骨骼, 这可以将其视为训练数据中所有不同骨骼的共同祖先。通过交错的骨架卷积和池化层,共享的隐空间包括与原始骨骼的关节相关联的一系列深层的时间特征。隐空间是由每个骨骼结构(域)的编码器/解码器对共同学习的。
此外,我们利用深度运动表示将运动属性与骨骼的形状属性区分开来,这使我们能够在深度特征空间中使用简单的算法执行运动重定位。类似于由静态(关节偏移)和动态(关节旋转)组成的运动的原始低级表示,我们的深度运动特征也分为静态和动态部分。但是,在原始输入运动中,这两个组件紧密耦合:特定的关节旋转顺序绑定到特定的骨骼长度和骨骼结构。相反,我们的编码器学会解耦:隐编码的动态部分与骨骼无关,而静态部分对应于普通的原始骨骼。隐空间的这一特性使得仅通过将A的编码器产生的隐编码馈送到B的解码器中,就可以将运动从骨骼A重新定位到骨骼B。
总而言之,我们在这项工作中的两个主要贡献是:
- 一个新的运动处理框架,由深度运动表示和可微的 skeleton-aware 卷积,池化和解池化操作组成。
- 一种新的体系结构,用于在可能具有不同关节数目的拓扑等效骨骼之间进行不成对运动重新定向。
除了在没有任何成对的例子下,提供第一种自动重新定位具有不同结构的骨骼之间的目标的方法外,我们还展示了新的深度运动处理框架用于运动去噪的有效性(第4.4节)。我们评估了运动重定位方法,并将其与第6节中的现有方法进行了比较。一个合成数据集包含了应用于不同骨骼的成对运动,用于对我们的方法进行定量评估。
RELATED WORK
Motion Retargeting
在他们的开创性工作中,Gleicher等人[1998]通过制定具有运动学约束的时空优化问题并解决整个运动序列问题,解决了角色运动的重新定向问题。Lee和Shin [1999]探索了一种不同的方法,该方法首先在每个帧上应用逆运动学(IK)来满足约束条件,然后通过拟合多级B样条曲线使运动平滑。Choi和Ko [2000]的在线重定目标方法在每帧执行IK,并计算与 end-effector 位置变化相对应的关节角度变化,同时确保很好地保留了原始运动的高频细节。Tak和Ko [2005]在他们基于物理的运动重定向过滤器中,利用动力学约束来实现物理上合理的运动。Feng等人[2012]提出了一种启发式方法,可以将任意关节映射到规范关节,并描述了一种算法,该算法可以将一组行为映射到任意人形骨骼上。
经典的运动重定目标方法(例如上述方法)依靠针对特定运动的手工运动约束进行优化,并简化了假设。捕获的运动数据的可用性提高,使得数据驱动的方法更具吸引力。Delhaisse等人[2017]描述了一种将学习到的隐运动表示从一个机器人转移到另一个机器人的方法。 Jang等人[2018]训练了一个深层的自动编码器,其隐空间经过优化以创建所需的骨骼长度变化。 这些方法需要成对的训练数据。
受未配对图像到图像转换方法的启发[Zhu等人2017],Villegas等人[2018]提出了一种具有前向运动学层和基于循环一致性的对抗性训练目标的递归神经网络架构,用于使用未配对的训练数据进行运动重定向。Lim等人[2019]通过学习解开姿势和动作,报告了在未配对环境中更好的结果。Aberman等人[2019]将从视频中提取的2D人体运动分解为与角色无关的运动,视角和骨骼,从而能够在绕过3D重建的同时重新定向2D运动。所有这些数据驱动的方法都假定源关节结构和目标关节结构是相同的。
几项工作探索了将人类运动数据重新定向到非类人动物角色[Seol et al 2013; Yamane等,2010]。在这种情况下,源骨骼和目标骨骼可能会彼此大不相同,但是,上述方法需要捕获以目标角色样式操作的人类对象的动作。 为了学习映射,还需要从捕获的运动序列中选择一些关键姿势并将其与相应的角色姿势匹配[Yamane等,2010],或将相应的运动配对[Seol等,2013]。Celikcan等人[2015]将人的运动重新定位到任意网格模型,而不是骨骼。与前述方法相似,学习这种映射需要许多姿势到姿势的对应关系。
Abdul-Massih等人[2017]认为,角色的动作风格可能由身体各个部分(GBP)的动作表示。因此,可以通过在GBPs之间建立对应关系来跨骨骼结构完成运动风格重新定向,然后进行约束优化以保留原始运动。这要求为每对角色定义GBP以及它们之间的对应关系。
另一个与松散相关的问题是网格变形传递问题。 较早的作品,例如,[Baran et al 2009; Sumner andPopović 2004]要求网格之间有多个对应关系。Gao等人[2018]的最新方法使用未配对的数据集来训练学习形状空间之间映射的VAE-CycleGAN。我们还利用对抗训练来避免需要配对数据或对应关系,但是我们的工作设置有所不同,因为我们处理的是层次结构清晰的结构(骨骼)的时间序列,而不是网格。
Neural Motion Processing
Holden等[2016; 2015]是最早将CNN应用于3D角色动画的工作之一。运动表示为3D关节位置的时间序列,而卷积核在时间维度上是局部的,但在关节维度上是全局的(支持包括骨骼的所有关节)。因此,忽略了关节的连接性和骨架的层次结构。
此外,使用3D关节位置表示运动并不能完全描述运动,需要IK提取动画。Pavllo等人[2019]提出了QuaterNet,该系统处理关节旋转(四元数),但在骨架上执行正向运动学以惩罚关节位置,而不是角度误差。但是,仅从关节旋转中提取的卷积特征无法完全捕获3D运动,因为当应用于不同骨骼时,同一组关节四元数会导致不同的姿势。
由于关节角色的骨骼可以表示为图,因此可以考虑使用图卷积网络(GCN)处理运动数据。 在这样的网络中,卷积滤波器直接应用于图节点及其邻居(例如,[Bruna等,2013; Niepert等,2016])。Yan等人(2018)提出了一种基于骨架的动作识别的时空GCN(ST-GCN),其中将空间卷积滤波器应用于骨架中每个节点的1个邻居,并将时间卷积应用于连续位置 每个关节的时间。在这种方法中,没有在空间维度上进行合并,而仅在时间维度上进行。此外,根据手工制作的策略,每个节点的1个邻居的集合被分成几个集合,以便为每个集合分配可学习的卷积权重。 Ci等人[2019]应用了局部连接网络(LCN),它可以对全连接网络和GCN进行概括,以解决3D姿态估计问题。这项工作没有解决3D运动的处理。这项工作没有解决3D运动的处理。
并非基于卷积的另一种选择是使用深度RNN在时空图上进行学习[Jain et al 2015]。Wang等人[2019]提出了一种时空RNN,其中使用骨架图结构上的分层神经网络将骨架编码到隐空间中。层次结构是手工制作的,而学习了将不同节点合并在一起的全连接层的权重。因此,骨架卷积和骨架池化都不会发生。这种方法的目标也不同于我们的目标(运动预测,而不是重定位)。
OVERVIEW
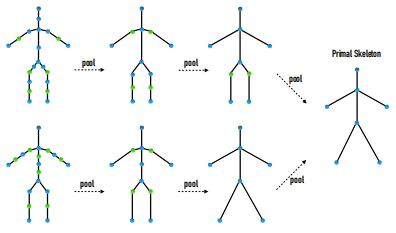
我们的目标是应对可能具有不同结构但在拓扑上等效的骨骼之间进行运动重定向的任务。关键思想是利用拓扑等效的骨架可以由拓扑结构图表示。通过消除沿线性分支的度为2节点,可以将一对这样的图简化为一个共同的最小图,如图2所示。我们将由简化的通用图表示的骨架称为原始骨架。
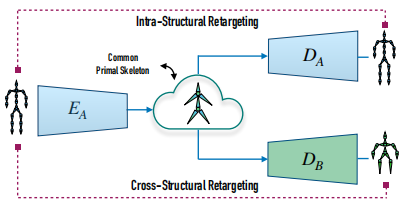
该观察结果表明,将不同的同拓扑骨骼执行的运动编码为与原始骨骼结构或骨骼比例无关的深层表示。因此,所产生的隐空间是具有不同结构的骨骼执行的运动所共有的,我们使用它来学习数据驱动的运动重新定向,而无需任何成对的训练数据。如图3所示,重定位过程使用在运动域上训练的编码器 $E_A$(由具有相同结构的骨骼执行)将源运动编码到公共隐空间中。从该空间,隐表征可以被解码为由目标骨架执行的运动。目标骨架可能具有相同的结构,但骨骼长度不同,在这种情况下,解码是由在相同域上训练的解码器 $D_A$ 完成的。但是,使用在不同域上训练的解码器 $D_B$,还可以跨不同的骨骼结构将目标重定向。
为了实现上述方法,我们引入了一个新的深度运动处理框架,该框架包含两个新的组件:
(1) Deep Motion Representation. 我们将运动序列表示为组成图的转子的时间集,其中每个转子都由动态的,与时间相关的特征向量(通常称为关节旋转)以及静态的,与时间无关的静态向量( 通常称为偏移),如图4所示。静态-动态结构是角色动画中常见的低级表示形式,我们的框架在处理链中将其保留下来。具体来说,我们使用两个分支(静态和动态)将低级信息转换为运动特征的深层,静态-动态表示。
(2)Deep Skeletal Operators。我们定义了可以应用于动画骨架的新的可微运算符。运算符是 skeleton-aware ,即运算符考虑了骨骼结构(层次结构和联合邻接关系)。将这些运算符连接到一个可优化的神经网络中,可以学习深层的时间特征,这些深层的时间特征代表浅层中的低层,局部关节相关性,而深层中代表高级的全局人体部分相关性。
我们的运动处理框架,包括新的表征和 skeleton-aware 运算符,在第4节中进行了描述,而实现数据驱动的跨结构运动重定向的体系结构和损失函数在第5节中进行了描述。
Questions
什么是fbx文件, 它包含了哪些内容?
什么是bvh文件, 它包含了哪些内容?
BVH是BioVision等设备 对人体运动进行捕获后 产生文件格式的文件扩展名。
BVH文件 包含角色的骨骼和肢体关节旋转数据。BVH 是一种通用的人体特征动画文件格式,广泛地被当今流行的各种动画制作软件支持,如3DMax。
文件格式
文件主要部分
骨架信息 和 数据块
- 骨架信息: 按照层次关系,定义了如root hip leg等位置和旋转分量,从而形成一个完整的骨架
- 数据块: 对应上面的骨架各部位标出每帧的数据信息
一个BVH文件包含两部分,头部部分 和 数据部分,头部部分 描述了骨架的层次关系和初始姿势,数据部分 包含了动作(motion)的数据.
文件示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
HIERARCHY
ROOT Hips
{
OFFSET 0.00 0.00 0.00
CHANNELS 6 Xposition Yposition Zposition Zrotation Xrotation Yrotation
JOINT Chest
{
OFFSET 0.00 5.21 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT Neck
{
OFFSET 0.00 18.65 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT Head
{
OFFSET 0.00 5.45 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
End Site
{
OFFSET 0.00 3.87 0.00
}
}
}
JOINT LeftCollar
{
OFFSET 1.12 16.23 1.87
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT LeftUpArm
{
OFFSET 5.54 0.00 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT LeftLowArm
{
OFFSET 0.00 -11.96 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT LeftHand
{
OFFSET 0.00 -9.93 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
End Site
{
OFFSET 0.00 -7.00 0.00
}
}
}
}
}
JOINT RightCollar
{
OFFSET -1.12 16.23 1.87
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT RightUpArm
{
OFFSET -6.07 0.00 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT RightLowArm
{
OFFSET 0.00 -11.82 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT RightHand
{
OFFSET 0.00 -10.65 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
End Site
{
OFFSET 0.00 -7.00 0.00
}
}
}
}
}
}
JOINT LeftUpLeg
{
OFFSET 3.91 0.00 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT LeftLowLeg
{
OFFSET 0.00 -18.34 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT LeftFoot
{
OFFSET 0.00 -17.37 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
End Site
{
OFFSET 0.00 -3.46 0.00
}
}
}
}
JOINT RightUpLeg
{
OFFSET -3.91 0.00 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT RightLowLeg
{
OFFSET 0.00 -17.63 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
JOINT RightFoot
{
OFFSET 0.00 -17.14 0.00
CHANNELS 3 Zrotation Xrotation Yrotation
End Site
{
OFFSET 0.00 -3.75 0.00
}
}
}
}
}
MOTION
Frames: 2
Frame Time: 0.033333
8.03 35.01 88.36 -3.41 14.78 -164.35 13.09 40.30 -24.60 7.88 43.80 0.00 -3.61 -41.45 5.82 10.08 0.00 10.21 97.95 -23.53 -2.14 -101.86 -80.77 -98.91 0.69 0.03 0.00 -14.04 0.00 -10.50 -85.52 -13.72 -102.93 61.91 -61.18 65.18 -1.57 0.69 0.02 15.00 22.78 -5.92 14.93 49.99 6.60 0.00 -1.14 0.00 -16.58 -10.51 -3.11 15.38 52.66 -21.80 0.00 -23.95 0.00
7.81 35.10 86.47 -3.78 12.94 -166.97 12.64 42.57 -22.34 7.67 43.61 0.00 -4.23 -41.41 4.89 19.10 0.00 4.16 93.12 -9.69 -9.43 132.67 -81.86 136.80 0.70 0.37 0.00 -8.62 0.00 -21.82 -87.31 -27.57 -100.09 56.17 -61.56 58.72 -1.63 0.95 0.03 13.16 15.44 -3.56 7.97 59.29 4.97 0.00 1.64 0.00 -17.18 -10.02 -3.08 13.56 53.38 -18.07 0.00 -25.93 0.00
头部部分:
- 头部部分开头包含 ”HIERARCHY“ 关键词
- 接着一行开头为 ”ROOT” 关键词,后面跟着root的名字. 当然,一个root段(segment)之后,允许再定义另一个段,也可以定义为 ”ROOT”. 原理上,BVH文件能够包含任何数量的骨架段.
- BVH文件的格式为递归的格式,层次结构的每一个segment包含了一些相关数据,该segment要递归定义它的子segment.
- 关键词 ”ROOT“ 后以大括号开头,下行以tab填充,能够增加可读性.
- segment的第一个信息是 该segment相对于父segment的偏移量(OFFSET), 如果是根ROOT segment则偏移量OFFSET则通常为0,OFFSET指定了X,Y,Z方向上与父segment的偏移量,偏移量也指示用于绘制父segment的长度和方向.
- BVH文件中没有明确的信息能够描述一个segment该怎样画,通常通过从第一个segment的偏移量来定义父segment,典型的,只有ROOT和上部主体的segment将有多个子segment.
- 接下来一是 ”CHANNEL“ 头部信息,后面跟着的数字表明channels的数目,后面的标签表明每一个channel的类型.
- 一个BVH文件解析器必须跟踪channel的数目和channel的类型,在后面MOTION信息被解析的时候,这个顺序在解析每一行的MOTION数据的时候需要用到.这种格式规定很明显具有灵活性,能够允许segment拥有任何数目的channel,且能够按照任何顺序.
- channel旋转的次序是:Z X Y,
- 接下来能看到 ”JOINT“ 和 ”END SITE“ 关键词,一个JOINT的定义和ROOT的定义是相同的,除了CHANNEL的数目不同,JOINT正是递归开始的地方,剩下部分对JOINT的解析和ROOT一样的.
- END SITE结束了递归,它的定义还包含了一些数据,它提供了前segment的长度,就像前面子segment提供了offset用于绘制父segment的长度和方向
- JOINT的结尾以右括号结束,BVH中,空间被定义成了右旋坐标系与Y轴作为世界矢量.
数据部分
- 数据部分以”MOTION”开头,后面的数字表示了帧率,下一行”Frame Time“定义了采样频率
- 文件剩余的部分包含了motion的数据,每一行是一个motion数据的样本
关键词
- HIERARCHY: 开头
- ROOT:根关节
- JOINT : 根关节下的关节
- OFFSET:子关节相对父关节的偏移,也可以表示对应父关节的长度和方向,当子关节不止一个时,采用第一个子关节的数据.
- CHANNELS: 给出了关于channel的个数和名称(ROOT总是拥有6个channels,而一般JOINT只有3个,较之ROOT缺少了XYZ的position信息,因为子关节只需要根据它相对于父关节的偏移就可以算出它在坐标系中的具体位置了)
注意
- rotation channel的顺序是:Zrotation Xrotation Yrotation
- BVH格式的运动采取的旋转方式比较特别
-
- End Site 表示终结递归,该关节的定义到此为止,可看作一个终端效应器
- 数据块以 MOTION 关键字开始
-
- Frames: 定义帧数,Frame Time:定义数据采样速率-每帧的时间长度,如0.033333则表示BVH文件的一般采样速率,每秒30帧
- 接下来的数据就是实际的运动数据,对应骨架信息的层次结构
- 对于子关节来说,平移信息存储在骨架信息的OFFSET中,旋转信息则来自于MOTION部分;
- 对于根结点来说,平移量是OFFSET和Motion section中定义的平移量之和。
- BVH不考虑Scale变换。
数据
计算segment的位置,需要从局部的平移和旋转信息创建一个变换矩阵.对于任何joint,平移的信息将会是层次部分中定义的offset,旋转信息则从motion部分得到
对于根ROOT,平移数据为offset的总和,而旋转的消息来自motion部分,BVH不需要考虑比例因子的计算.
创建变换矩阵的直接方法是创建3个单独的旋转矩阵,每个矩阵对应每根轴 vR = vYXZ。
什么是MoCap数据集?
什么是Mixamo数据集?
References
-
Previous
【深度学习】Pix2PixHD论文阅读 -
Next
【深度学习】Neural Kinematic Networks for Unsupervised Motion Retargetting