Abstract
深度神经网络的出色性能主要取决于数据集的属性,例如大小,多样性,完整性。但是,在某些情况下通常很难获得高质量的训练数据集。受到人类视觉认知过程的启发,小样本学习,而且鲁棒性强,我们认为经验知识比大规模数据更强大。为了结合知识和数据的力量,本文提出了一个知识导向的语义计算网络(SCN),它由一个主要的知识导向的语义树模块和一个辅助的数据驱动的轻量级神经网络模块构成。语义树模块可以通过正向计算过程快速计算分类结果。轻量级神经网络模块可以帮助语义树模块实现更高的分类能力。我们还提出了一种铰链交叉熵损失函数来训练SCN,这使SCN可以专注于那些分类错误的训练样本并进一步提高分类准确性。在MNIST和GTSRB数据集上的实验结果证明,与原始训练样本上的最新方法相比,SCN具有出色的分类精度,并且在很少训练的情况下比最新方法具有更高的分类精度采样。而且,在MNIST的BIM eps = 0.3和GTSRB对抗性测试样本的FGSM eps = 0.03的情况下,与原始CapsNet相比,提出的的SCN(1/4)和SCN(1/8)的准确度提高了75%和14%以上 。
Introduction
最近,一系列基于大型训练样本的深度学习模型,包括CNN [1-4],GAN [5-7],RNN [8,9]等在计算机视觉领域(例如图像分类[10,11],物体检测[12-14]等)做出了杰出贡献 。这些网络的性能在很大程度上取决于训练数据集的某些属性,例如数据集的规模,是否带有标签,多样性和完整性。此外,大数据网络的训练过程导致高能耗和大存储空间需求。在许多专业应用领域中,用户通常没有足够好的数据集用于学习。例如,在医学图像处理中,可以从医疗机构获得大的超声图像数据集,但是标注这样的大数据集非常具有挑战性,因为它只能由受过至少5年训练的专家来完成。对于军事目标识别或灾难评估,大数据集将是使用深度学习方法的最大困难。而且,大多数常见的深度学习模型都难以在由对抗算法生成的对抗样本上获得良好的性能[15-20]。
与深度学习模型不同,一个孩子可以通过“一次性学习” [21]进行有意义的概括。有影响力的观点解释说,在新的任务学习过程中,人类可以利用强大的先验知识[22]做出相关的推论。这使我们能够直接排除一些不合理的结果,并加快我们的学习过程。因此,将人类先验知识整合到神经网络中是小样本训练和快速学习的有效解决方案。然而,由于神经网络难以描述的黑盒模型,设计其架构,解释其特征和预测其性能非常困难,从而导致集成困难。
一直以来,研究人员都知道先验知识的重要性。为了描述先验知识,通常作为优化目标函数中的正则项来描述目标变量的分布。但是,我们不能总是获得先验知识的数学表达。有时,我们对物体有一些了解,例如汽车的结构。它具有四个圆形车轮和一个矩形车身。这样的知识不能用数学表达来描述,这使先验知识难以使用。
为了解决这个问题,人脑的视觉认知过程提供了一个很好的启发[23,24]。视觉信息通过眼睛传输到大脑后,将由人类视觉皮层进行处理。视觉皮层主要包括初级视觉皮层(V1,也称为条纹皮层)和额外的的三叶皮层(例如V2,V3,V4,V5等)。1962年,Hubel和Wiesel [25]发现,V1中的某些细胞仅对具有特定方向的亮条或暗条做出反应,并且对于每个细胞,都有一个最佳位置,在该位置细胞反应最强烈。然后,Livingstone和Hubel [26]提出,不同类型的V1细胞在V1中构成三种不同的结构,分别将有关颜色,形状,运动和立体视觉的信息传递给V2及其后续细胞。
人脑的这种分层传输和视觉信息过程为研究人员带来了极大的启发。近年来,已经有许多从目标的层次结构角度出发构建识别网络的研究。S. C. Zhu等人提出了用于目标识别的“与或模板”(AOT)[27,28]。它是一个分层的可重配置图像模板,并通过概率方法学习了目标的结构语义组成。Dileep George等人提出了一种递归皮质网络,该网络是将AOT与条件随机场结合在一起的生成模型[29]。它打破了基于文本的验证码的防御,并且在场景文本识别方面比神经网络更有效。此外,Hinton提出了CapsNet [30,31]来处理部分和目标之间的空间层次表示,这是卷积神经网络(CNN)的一个问题。CapsNet使用称为capsule的向量或矩阵表示一组具有不同属性的神经元。每个capsule都可以视为一种特定类型的实体,例如目标或目标的部分,其长度表示capsule实体存在的可能性。CapsNet还使用动态路由算法来更新耦合系数,这使CapsNet在MNIST数据集上实现了出色的性能。
先前的研究对模仿人类的决策[32]和视觉认知过程进行了一些初步的研究。但是相应的网络由于需要大量数据而变得更加复杂,因为它们本质上仍然是数据驱动的方法。迄今为止,仍然没有有效的机制来利用人类的先前经验和知识。因此,必须探索一种方法,将先验知识和经验整合到神经网络中,如此可以减少训练样本并增强模型的鲁棒性。
为了更好地刻画先验知识,在本文中,我们使用语义树对人类的视觉认知过程进行建模。这是具有多个级别的语义,语义关系表和语义关系模板的树状结构。我们提出了一种用于分类任务的新型分类网络,称为语义计算网络(SCN)。SCN由两个模块组成:知识导向的语义树模块和数据驱动的轻量级神经网络模块。在MNIST和德国交通标志识别基准(GTSRB)数据集上进行的大量实验结果表明,我们的SCN具有与原始训练样本上的最新方法相当的出色分类精度,并且在少数训练样本上具有比其他方法更高的分类精度 。而且,与数据驱动的神经网络相比,我们的模型对对抗攻击具有更强的鲁棒性。
总的来说,这项研究的贡献主要在三个方面:
- 我们首先探索了一种使用语义树对人类视觉认知过程进行建模的方法。该语义树对对象具有良好的层次描述。特别是,这是一个前向计算过程,可以快速计算分类结果。
- 我们提出了一个知识导向的语义计算网络(SCN),它结合了两个模块:知识导向的语义树和数据驱动的轻量级神经网络。语义树模块完成了对象的基本识别,而轻量级神经网络模块可以学习一些难以描述的特征,作为对语义树模块的良好补充。
- 我们为语义计算网络提出了一种具有铰链交叉熵的损失函数。如果对培训样本进行了正确分类,并且校正后的概率超出了边际阈值,则损失将为零,并且学习将停止。这使SCN可以专注于那些易于分类的样本以外的复杂而模糊的样本,从而可以进一步提高SCN的分类能力。
Related work
Image classification
众所周知,图像分类是计算机视觉领域的基础和核心技术。当前,有许多传统的优化算法[33-35]和基于深度学习的方法[1,10,36,37,30,31,38]用于图像分类。LDA方法基于类成员的最大后验估计[33]。Sagnik Majumder等人提出了一个简单的模型“弹性匹配”,以识别手写数字[35]。Fatin Zaklouta等。 提出使用k-d树和具有不同大小的直方图直方图(HOG)的随机森林对GTSRB数据集进行分类[34]。这些传统的优化算法通常会花费很长时间并且精度较低。为了提高MNIST数据集的分类准确性,Ye LeCun等人提出了一种基于梯度的学习算法来优化MNIST数据集的多层神经网络,从而获得了极好的准确性[1]。Hinton为MNIST数据集提出了一种具有动态路由算法的新颖CapsNet,可以进一步提高分类准确性[30]。刘涛等人提出了一种实用的基于时间的多层加标神经形态结构,称为“ MT-Spike”,用于现实的识别任务[36]。此外,Amirhossein Tavanaei等人提出了一种依赖于尖峰时序的可塑性(STDP)方法来训练多层尖峰卷积神经网络[37]。在GTSRB数据集上,CNN已显示出令人印象深刻的识别准确性[39,2,40,41]。特别是,由20个卷积神经网络组成的集成分类器[40]获得了最新的准确性。但是,这些基于CNN的方法具有大量的调整参数(时间和空间复杂度较高),并且取决于图像增强操作(例如缩放,旋转等)所生成的大量训练样本。
Lightweight neural network
最近,一些研究人员对更紧凑和更简单的网络越来越感兴趣[42-45]。Han等人介绍了一种“深度压缩”方法[42],它需要一个三阶段的流程:修剪,训练量化和霍夫曼编码。Landola等。 提出了一种名为SqueezeNet的小型DNN架构,该架构在ImageNet上实现了AlexNet级的准确性,而参数却减少了50倍[43]。郝力等人提出了一种CNN的加速方法,他们从CNN修剪掉那些对输出精度影响较小的卷积核[44]。Xiangxiang Zhang等人为移动设备介绍了一种名为ShuffleNet的计算效率极高的CNN架构。ShuffleNet的实际速度是AlexNet的13倍,同时保持了相当的准确性[45]。
Adversarial attacks
最近,一些研究人员越来越关注神经网络的安全性问题[46,47]。Marco Barreno等人提出了一个框架,用于分析对机器学习系统的攻击并对其进行防御。一些研究还发现,大多数神经网络非常容易受到对抗性攻击[18,48,49,17,20,50]。C. Szegedy等人发现,通过施加一定程度的不可察觉的扰动,可以使神经网络对图像进行错误分类[50]。A. Fawzi等人提供了一个理论框架,用于分析分类器对对抗性摄动的鲁棒性,并显示了分类器鲁棒性的基本上限[51]。对抗样本是以某种方式对其进行了非常轻微的修改的输入数据。尽管人类不会注意到任何修改,但是神经网络很容易将这种对抗性样本误分类。FGSM [16]方法被认为是一种生成对抗性样本的简单明了的策略,它会大大降低卷积神经网络中图像分类任务的准确性。同样,BIM [16]方法是一种更复杂的对抗攻击,在FGSM攻击中只需采取多个较小的步骤即可创建对抗样本。
通常,这些特征也反映在人类视觉识别机制的过程中。人类视觉识别机制可以解释目标识别过程,这也是一个简单的前向计算过程。先验知识具有很强的泛化能力,并且可以在很少的训练样本上很好地学习。人的视觉识别机制也具有非常强的鲁棒性。 由于这些优点,我们将探索如何将先验知识整合到神经网络中。为此,也有一些学者进行了有关将先验知识集成到神经网络中的类似研究。Wang-Zhou Dai等人提出了一种诱导学习框架,该框架借助试错性的诱导过程同时学习知觉和推理[52]。Ivan Donadello等人提出了一种逻辑张量网络,该网络将神经网络和一阶模糊逻辑集成在一起,可以在存在逻辑约束的情况下有效地从嘈杂的数据中学习[53]。严格来说,这些方法使用概率逻辑代替先验知识。它们本质上仍然是数据驱动的方法,需要进一步改进。
在本文中,我们提出了一种用于分类任务的新型语义计算网络(SCN)。SCN由两个模块组成:知识导向的语义树模块和数据驱动的轻量级神经网络模块。为了构建语义树模块,我们首先构造了多个层次的语义。然后我们定义了语义之间的几种空间结构关系,并通过统计样本上的统计方法得到了一组语义关系模板。最后,我们为分类任务建立了语义树模型。在分类过程中,对输入图像进行语义原始检测器获取对应的语义关系表。然后,语义树通过语义关系表和语义关系模板之间的点积来给出分类概率,这是一种前向计算操作。语义树是基于知识的,可以容易地解释和扩展,而用更多细节完全表示那些特殊的复杂图像会有些困难。
为了减轻这个问题,我们使用轻量级神经网络来学习这些复杂的图像细节。特别地,由于CapsNet与语义树的高度兼容性,因此我们选择CapsNet作为辅助网络。为了训练SCN,我们为语义计算网络提出了一个铰链交叉熵损失函数。如果对训练样本进行了正确分类,并且校正后的概率超出了边际阈值,则损失将为零,并且学习将停止。这使SCN可以将其能力正确地用于对训练样本进行分类,而不是使正确的预测更加正确,这使SCN可以专注于那些困难的训练样本,从而进一步提高了SCN的分类能力。在MNIST和GTSRB数据集上的实验结果证明,与原始训练样本上的最新方法相比,SCN具有出色的分类精度,并且在少数训练样本上的分类精度高于最新方法。而且,与数据驱动的神经网络相比,我们的模型对对抗攻击具有更强的鲁棒性。
本文的其余部分安排如下:在第三部分中,我们简要介绍了语义计算网络和一些相关概念。在第4节中,我们设计SCN的网络体系结构并描述其工作机制。在第5节中,我们对原始MNIST,GTSRB数据集,相应的少量训练样本和对抗样本进行了一系列实验评估。最后,我们在第6节中总结了这篇论文。
Semantic computing network
与自然语言处理任务中的语义不同,本文中的语义通常表示一些具有特定含义的空间结构单元。对于人类的视觉识别过程,我们认为语义是图像的重要组成部分。它具有层次结构,语义层次意味着多层次语义的包含关系,这意味着语义可以分解为许多子语义(图1)。我们以汽车为例使用语义树来表示目标知识。目标车被视为顶层语义,可以分解为轮子,窗口等中层语义(关键组件)。此外,中层语义也可以分解为低层语义(简单形状),例如圆形,三角形,矩形等。通过这种方式,逐层分解顶级语义,直到最低的语义(我们称为语义基元),例如弧,线,颜色等。语义树的好处主要是可描述和可理解的。因此用语义树表示目标结构信息非常有用。语义基元是图像中基本的有意义的单元,也是人类对V1细胞可以感知的基本视觉感知(例如线条和颜色)。
为了描述两个相同级别语义之间的结构关系,我们定义了一组结构关系表,包括距离关系表,位置关系表等。此外,我们通过模板匹配和统计方法为每个顶级语义设置了语义关系模板。语义关系模板描述了分类样本中所有级别的语义及其关系。因为树状结构可以很好地描述上下语义之间的包含关系,所以我们基于语义关系表和语义关系模板来构建语义树。语义树仅通过前向计算方法即可轻松预测分类结果,该方法包括检测图像中的最低语义,计算语义关系表并输出分类概率。这样,分类过程从数据驱动方法变为知识驱动方法。与CNN的黑匣子模型不同,人类更易于理解这种分类过程。
但是,分类样本中的大多数对象都有各种详细信息,例如姿势,方向,背景等。知识的表示是有条理的,但有局限性。某些先验知识和经验很难描述一些复杂的特征。因此,通过语义树不足以来描述目标的所有特征。基于学习的神经网络具有学习复杂特征的独特表示的能力,这些复杂特征很难通过先验知识和经验来描述(我们称其为难以描述的特征)。因此,我们需要寻找一种基于学习的方法来帮助语义树学习这些难以描述的特征。在SCN中,我们选择CapsNet作为辅助网络。因为capsule和语义是相互对应的。CapsNet在某些方面与我们的语义树高度兼容,并且两个模块可以轻松组合。首先,CapsNet使用活动向量来表示特定类型实体的实例化参数[30]。类似地,语义树使用向量来描述语义及其关系。其次,它们都是层次结构。低层的capsule 表示“部分”,而高层的capsule表示“目标”,这与语义树的低层语义和高层语义完全相似。最后,两个模块的分类过程是相同的,它们都基于实体的得分完成了分类结果。为了在少量训练样本和对抗样本上实现更高的准确性,我们通过结合语义树和轻量级神经网络来设计语义计算网络(SCN)(图2)。在这里,我们以GTSRB数据集的50 km / h交通标志为例。将其输入到语义树时,语义基元检测(第4.1节中的详细信息)可以检测到语义基元,包括线,弧,白色,红色。双向蓝色箭头表示同一级别上两个语义之间的空间结构关系。此外,根据不同语义原语的空间结构关系,可以获得诸如五,零,杆,红环之类的底层语义。我们还可以根据不同底层语义之间的关系,获得字符50和木板等中层语义。最后,我们获得了最高的语义,例如50 km / h,30 km / h,80 km / h交通标志。当训练样本输入到轻量级神经网络时,我们可以通过输入层,隐藏层和输出层获得最终的输出概率。最后,可以通过判别规则获得分类结果(第4.4节中的详细信息)。特别地,语义树完成了初步和主要图像分类过程。辅助轻量级神经网络可以学习难以描述的特征的表示以补充语义树。
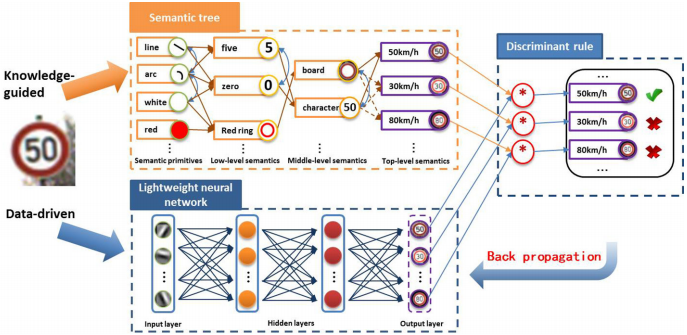
Network architecture: The semantic tree, the CapsNet
在本文中,我们提出了一种用于分类任务的新型语义计算网络,该网络包括一个主语义树模块和一个辅助轻量级神经网络模块(CapsNet)。
Semantic primitive detection and semantic relation table
给定图像,我们选择传统的图形形状,例如直线,圆形,椭圆形,弧形,三角形,矩形,四边形,多边形及其颜色等作为语义基元。在本文中,为了获得语义基元并检测其长度,角度等特性,我们采用了一些常规的图像处理方法,例如阈值分割法,膨胀腐蚀法,模板匹配法。我们称此过程为语义基元检测。
找到图像的所有语义基元之后,下一个任务是描述较低语义如何构成较高语义。为此,我们提出了四个语义关系表来描述语义基元的结构关系:相交关系表,距离关系表,夹角关系表和位置关系表,它们可以缩写为int,dis,ang ,loc。int描述两个基元是否相交。dis描述了两个基元坐标之间的距离。ang是不同语义基元的夹角关系。loc 包含上,下,左和右关系。在这里,我们以一个位置关系表为例(表1)。这些关系表可以通过等式(1)通过简单的语义计算获得。关系表中的每个元素代表两个特定语义基元之间的关系值, 我们在语义关系表 $c$ 中将 $r_i^c$ 表示为第 $i$ 个关系值, 其中 $c \in {int ,dis, ang, loc}$。 在一幅图像中, 如果它具有相应的语义基元和关系,$r_i^c = 1$; 否则 $r_i^c = 0$。 例如,两个特定语义基元之间的距离是否超出了先验知识所设置的阈值。然后, 关系表 $R^c$ 能够呗表示为 $R^c = (r_1^c, r_2^c, …, r_{\infty_c}^c)$, 其中$\alpha_c$ 表示 关系表 $c$ 的维度。 相关的语义关系表为:
\[R = (R^{int}, R^{dis}, R^{ang}, R^{loc}) \tag{1}\]如表1所示,我们以三种语义为例。两个相同的原语之间没有任何关系,因此使用“空”来表示这种关系。相对于基元2,基元1和基元2之间的关系为下。以相同的方式,相对于基元1,基元2和基元1之间的关系为上。其他语义基元之间也存在类似的关系。
为了表示高级语义,我们在以下集合中给出其原语:
\[\text{Upper semantic} = \{\text{primitive 1, primitive 2, ..., primitive n}\}\]最后,我们获得基元集 (Eq(2)) 和不同基元的语义关系 (Eq(1)) 的上层语义。
Semantic relation template: the definition of semantic tree
在构建语义树的过程中,语义关系模板是极其重要的部分。它描述了特定类的上层语义的标准关系。我们使用统计方法来构建特定类的语义关系模板。这种方法可以表示为:
\[\begin{aligned} T &= (\sum_{k=1}^K r_1(k), \sum_{k=1}^K r_2(k), ..., \sum_{k=1}^K r_\alpha(k))\alpha \\ &= \alpha_{int} + \alpha_{dis} + \alpha_{ang} + \alpha_{loc} \end{aligned} \tag{3}\]其中 $k$ 表示第 $k$ 个 训练样本 $(k = 1, 2, …, K)$。