
Abstract
我们提出了一种 区域-自适应 规范化(SEAN), 一个以分割掩膜为条件的生成对抗网络简单却有效的块, 这个分割掩膜描述了我们想要输出图像的语义区域。使用SEAN规范化, 我们可以构造一个网络, 它可以分别控制每个语义区域的风格, 比如,我们可以为图像的每个区域指定一种风格。 在重构质量,变化多样性以及视觉效果上, SEAN比之前的方法更适合编码、迁移和生成风格。我们在多个数据集上评估了SEAN, 并且报告了了SEAN超出SOTA的量化指标(比如FID, PSNR)。 SEAN也推动了交互式图像编辑的前沿。 我们可以通过分割掩膜或者给定区域的风格交互式地编辑图像。 我们也能从两张图像的每个区域插值风格。Code:https://github.com/ZPdesu/SEAN。
Introduction
本文研究了利用条件生成对抗网络(cGANs)生成图像的问题。具体来说,我们希望使用一个分割mask来控制生成图像的布局,该mask为每个语义区域提供标签,并根据标签向每个区域“添加”真实风格。例如,人脸生成应用使用区域标签,如眼睛、头发、鼻子、嘴巴等。景观绘制应用使用诸如水、森林、天空、云等标签。虽然有多个非常好的框架可以解决这个问题[23,8,40,47],但目前最好的架构是SPADE[39](也称为GauGAN)。因此,我们决定以SAPDE作为研究的出发点。通过分析SPADE的结果,我们发现了两个不足之处,我们希望在工作中加以改进。
首先,SPADE只使用一个风格编码来控制图像的整个风格,这对于高质量的生成或详细的控制是不够的。例如,期望输出图像的分割mask很容易包含在输入风格图像的分割mask中不存在的标记区域。在这种情况下,缺少区域的样式是未定义的,这会产生低质量的结果。此外,SPADE不允许对分割mask中的每个区域使用不同风格的输入图像。因此,我们的第一个主要想法是分别控制每个区域的风格,即我们提出的架构接受每个区域(或每个区域实例)一个风格图像作为输入。
第二,我们认为仅在网络的开头插入风格信息不是一个好的架构选择。最近的体系结构[26,32,2]已经证明,如果在网络中的多个层中注入样式信息作为规范化参数,例如使用AdaIN[20\z],则可以获得更高质量的结果。然而,这些以前的网络都没有使用风格信息来生成空间变化的规范化参数。为了缓解这个缺点,我们的第二个主要想法是设计一个标准化构建块,称为SEAN,它可以使用风格输入图像来创建每个语义区域的空间变化的标准化参数。这项工作的一个重要方面是空间变化的归一化参数依赖于分割mask以及风格输入图像。
从经验上讲,我们对我们的方法在几个具有挑战性的数据集上进行了广泛的评估:CelebAMask HQ[29,25,33]、CityScapes[10]、ADE20K[53]和我们自己的Façades数据集。定量地,我们评估了我们在一系列指标上的工作,包括FID、PSNR、RMSE和分割性能;定性地,我们展示了生成图像的例子,可以通过visual inspection进行评估。我们的实验结果表明,与目前最先进的方法相比有很大的改进。总之,我们将介绍一种新的体系结构构建块SEAN,它具有以下优点:
- SEAN提升条件GAN的生成图像的质量。 我们比较了最先进的SPADE和Pix2PixHD方法,并在定量指标(如FID评分)和visual inspection方面取得了明显的改进。
- SEAN改进了逐区域风格编码,使重建图像与输入风格图像更为相似,通过峰值信噪比(PSNR)和visual inspection进行测量。
- SEAN允许用户为每个语义区域选择不同的风格输入图像。这使得图像编辑功能产生更高的质量,并提供比目前最先进的方法更好的控制。示例图像通过区域风格迁移和每区域风格插值 交互式编辑得到的(见图1、2和5)。
Related Work
Generative Adversarial Networks. 自2014年引入以来,生成性对抗网络(GANs)[15]成功地应用于各种图像合成任务,例如图像修复[51,11]、图像处理[55、5、1]\和纹理合成[30、45、12]。随着GAN结构[41,26,39]、损失函数[34,4]和正则化[17,37,35]的不断改进,GAN合成的图像越来越逼真。例如,StyleGAN[26]生成的人脸图像质量非常高,几乎不能被未专业的观众区分开。传统的GAN采用噪声向量作为输入,因此提供很少的用户控制。这推动了条件GAN(cGANs)[36]的发展,用户可以通过向生成器提供条件信息来控制合成。包括类标签[38、35、6]、文本[42、19、49]和图像[23、56、31、47、47、39]。本文的工作是以图像输入的条件GANs为基础,旨在解决图像对图像的翻译问题。
Image-to-Image Translation. 图像到图像的翻译是一个总括性的概念,可以用来描述计算机视觉和计算机图形学中的许多问题。作为一个里程碑,Isola等人[23]首先证明了图像条件GANs可以作为各种图像到图像翻译问题的通用解决方案。此后,他们的方法通过以下几项工作扩展场景,包括:无监督学习[56,31]、小样本学习[32]、高分辨率图像合成[47]、多模态图像合成[57,22]和多域图像合成[9]。在各种图像到图像的翻译问题中,语义图像合成是一种特别有用的类型,因为它可以通过修改输入的语义布局图像来方便用户控制[29,5,16,39]。迄今为止,SPADE[39]模型(也称为GauGAN)生成的结果质量最高。在本文中,我们将通过引入每区域风格编码来改进SPADE。
Style Encoding. 风格控制是各种图像合成和处理应用的重要组成部分[13、30、21、26、1]。风格通常不是由用户手动设计的,而是从参考图像中提取的。在大多数现有方法中,风格被编码在三个地方:i)图像特征的统计[13,43]\;ii)神经网络权重(例如快速样式转换[24,54,50]);iii)网络规范化层的参数[21,28])。当应用于风格控制时,第一种编码方法通常耗时,因为它需要一个缓慢的优化过程来匹配图像分类网络提取的图像特征统计信息[13]。第二种方法实时运行,但每个神经网络只对选定参考图像的风格进行编码[24]。因此,对于每一种风格的图像,都需要单独训练一个神经网络,这就限制了它在实际中的应用。到目前为止,第三种方法是最好的,因为它可以实时实现任意风格的迁移[21],并且被StyleGAN[26]、FUNIT[32]和SPADE[39]等高质量网络使用。我们将展示我们的方法生成更高质量的结果,并支持更详细的用户控制。
Per Region Style Encoding and Control
给定输入风格图像及其相应的分割mask,本节说明 i)如何根据mask从图像中提取每区域风格,以及ii)如何使用提取的每区域风格编码来合成照片真实感图像。
How to Encode Style?
Per-Region Style Encoder. 为了提取每个区域的风格,我们提出了一种新的风格编码器网络,从输入图像的每个语义区域同时提取相应的风格(参见图4(a)中的子网络风格编码器)。
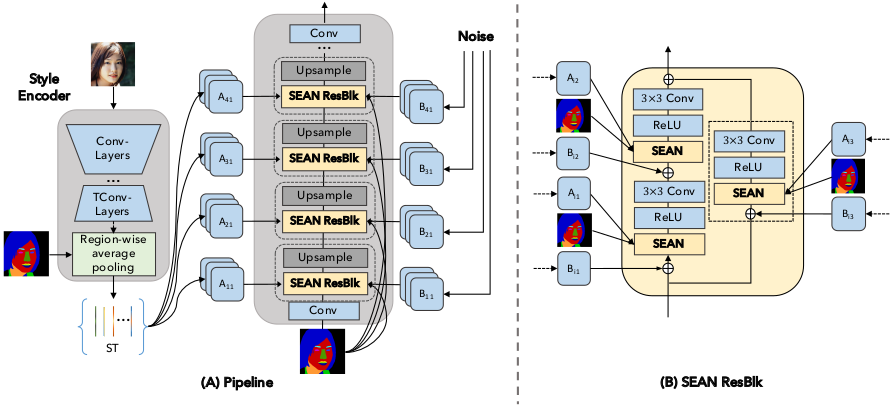
Figure 4: SEAN生成器。 (A) 在左侧, 风格编码器以一张图像作为输入, 输入一个风格矩阵 ST。 右侧的风格矩阵由SEAN ResBlocks 和 上采样层交替组成。 (B) 在(A)中SEAN ResBlock的具体细节。风格编码器的输出是 $512 \times s$ 维的风格矩阵ST, 其中 $s$ 是输入图像语义区域的数量。 矩阵的每一列和语义区域的风格相关。 不同于标准编码器建立在一个简单的降尺度卷积神经网络,我们的每区域风格编码器采用了一个“bottleneck”结构,以消除输入图像中信息无关的风格。结合风格应该独立于语义区域形状的先验知识,我们将由网络块 TConv-layers 生成的中间特征映射(512个通道)通过区域平均池层,并将它们简化为512维向量的集合。作为实现细节,我们想指出的是,我们使用 $s$ 作为数据集中的语义标签数,并将与输入图像中不存在的区域相对应的列设置为0。作为这种架构的一个变体,我们还可以为具有实例标签的数据集(例如CityScapes)提取每个区域实例的风格。
Q: Tconv-layers 是怎么做的?
A:
Q: Region-wise average pooling 是怎么做的?
A:
How to Control Style?
以区域风格编码和分割mask为输入,提出了一种新的条件归一化技术,称为语义区域自适应归一化(SEAN),以实现对真实感图像合成风格的详细控制。类似于现有的规范化技术[21, 39], SEAN的工作方式是调整生成器激活的scales和biases。与现有的方法相比, SEAN的调整参数同时依赖于风格编码和分割mask。 在SEAN块(图3)中,首先根据输入的分割mask将风格编码广播到相应的语义区域,从而生成风格图。输入的分割mask的风格图然后分别通过两个分开的卷积神经网络学习两组调整参数。 它们的加权和用于最后SEAN调整生成器激活的参数 scales和biases。权重在训练期间是可以学习的。 SEAN的正式定义如下。
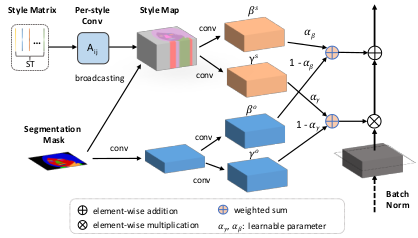
Figure 3: SEAN规范化。 输入是风格矩阵 ST 和 分割mask M。在上半部分中, ST 中的风格编码进行 Per-style Conv, 然后根据M广播到它们相应的区域以产生Style map。 Style map 通过卷积层处理产生 per-pixel 的规范化值 $\gamma^s$ 和 $\beta^s$。 下面的部分(天蓝色层)产生 per-pixel 规范化值的方法和SPADE类似。
Semantic Region-Adaptive Normalization (SEAN). 一个SEAN块有两个输入: 一个风格矩阵ST 编码 per-region 的风格编码 以及 一个分割mask M。 用 h 表示 一个 batch N个样本的一个卷积神经网络 当前SEAN块的输入激活。 令 H、 W和C表示激活图的高、宽和通道数。 调整激活的值由以下计算得到$(n \in N, c \in C, y \in H, x \in W)$:
\[\gamma_{c, y, x}(ST, M) \frac{h_{n, c, y, x} - \mu_c}{\sigma_c} + \beta_{c, y, x}(ST, M)\]其中 $h_{n, c ,y, x}$ 是规范化之前的激活, 调整参数 $\gamma_{c, y, x}$ 和 $\beta_{c, y, x}$分别是 $\gamma_{c, y, x}, \gamma_{c, y, x}^o$ 和 $\beta_{c, y, x}, \beta_{c, y, x}^o$的加权和(见图3中的 $\gamma$ 和 $\beta$ 变量的定义)。
\[\gamma_{c, y, x}(ST, M) = \alpha_\gamma \gamma_{c, y, x}^s(ST) + (1 - \alpha_\gamma)\gamma_{c, y, x}^o(M)\] \[\beta_{c, y, x}(ST, M) = \alpha_\beta \beta_{c, y, x}^s(ST) + (1 - \alpha_\beta)\beta_{c, y, x}^o(M)\]$\mu_c$ 和 $\sigma_c$ 是激活 通道 $c$ 的均值和标准差。
\[\mu_c = \frac{1}{NHW} \sum_{n, y, x} h_{n, c, y, x}\] \[\sigma_c = \sqrt{\frac{1}{NHW} (\sum_{n, y, x} h_{n, c, y, x}^2) - \mu_c^2}\]Experimental Setup
Network Architecture
图 4 (A) 展示了我们的生成器网络的概况, 它是建立在SPADE[39]的基础上的。和[39]相似, 我们使用由几个SEAN RsNet blocks (SEAN ResBlk) 和 上采样层组成的生成器。
SEAN ResBlk. 图 4 (B) 展示了我们 SEAN ResBlk 的结构, 它由三个卷积层组成,其 scales 和 biases 分别由三个SEAN块调制。每个SEAN块有两个输入: 一组每区域风格编码 ST 和 一个语义mask M。 注意输入在开始时调整: 输入的分割mask降采样到和某一层的特征图相同的高和宽; 输入的风格编码 ST 使用 1x1 卷积 转换为 每区域。 我们观察到初始转换是架构中不可或缺的组成部分,因为它们根据每个神经网络层的不同角色转换风格编码。例如,前面的层可能控制人脸图像的发型(例如波浪形、笔直),而后面的层可能指的是灯光和颜色。另外,我们观察到在SEAN的输入中加入噪声可以提高合成图像的质量。类似于StyleGAN[26],这种噪声的scale由训练期间学习的 每通道的scale factor B来调整。
Training and Inference
Training 我们将训练过程视为图像重构问题。 也就是说,风格编码器被训练成根据相应的分割mask从输入图像中提取每个区域的风格。以提取的区域风格编码和相应的分割mask作为输入,训练生成网络重构输入图像。和SPADE[39]和Pix2PixHD[47]一样,输入图像和重建图像之间的差异通过由三个损失项组成的总体损失函数来测量:条件对抗损失、特征匹配损失[47]和感知损失[24]。有关损失函数的详细信息,请参见补充资料。
Inference 在推理过程中,我们以任意分割mask作为mask输入,通过为每个语义区域选择一个单独的512维风格编码作为风格输入来实现每个区域的风格控制。这使得各种高质量的图像合成应用成为可能,这些应用将在下一节中介绍。
Results
下面我们将讨论我们的框架的定量和定性结果。
Implementation details. 和SPADE[39]一样,我们同时在生成器和判别器上使用谱规范化[37]。 生成器中额外的规范化由 SEAN 执行。 我们分别给生成器和判别器设定学习率为 0.0001 和 0.0004 。 对于优化器, 我们选择ADAM $\beta_1 = 0, \beta_2 = 0.999$。 所有的实验在四块Tesla v100 GPUs上训练。 为了更好的性能, 我们在SEAN规范化块上使用了同步版本的batch normalization[52]。
Datasets 在实验中我们使用如下数据集: 1) CelebAMask-HQ[29, 25, 33]包含30000张CelebAHQ人脸图像数据集的分割mask。 它们有19种不同的区域种类。 2) ADE20K[53]包含22210标注的图像, 它们有150个不同的区域标签。 3) Cityscapes[10]包含3500张标注的图像, 它们有35中不同的区域标签。 4) Facades 数据集。 我们从Google Street View[3]中收集了30000张facade图像。 没有手工标注, 而是使用预训练好的分割模型 DeepLabV3+ [7] 自动得到分割mask。
我们根据建议分割每个数据集, 论文中所有的图像都是仅从测试集生成的。 无论是分割mask还是风格图像在训练中都没有见过。
Metrics. 我么您使用下面的metrics来和SOTA比较我们的结果: 1) 由平均交并比(mIoU)和像素准确率(accu)度量语义分割准确率, 2) FID[18] 3) 峰值信噪比(PSNR), 4) 结构相似性(SSIM)[48] 5) 均方根误差(RMSE)。
Quantitative comparisons. 为了便于与SPADE进行公平比较,我们报告了仅使用单一风格图像的重建性能。我们为四个数据集中的每一个训练一个网络,并在表1和表2中报告前面描述的度量。在比较中我们选择SPADE[39]作为最先进的方法以及 pix2pixHD[47]作为第二好的方法。 基于visual inspection的结果, 我们发现FID分数最能反映结果的视觉效果,并且FID分数越低(但不总是)对应的视觉效果越好。一般来说,我们可以观察到我们的SEAN框架在所有数据集上都明显优于最新技术。

Table 1: 重构质量的量化比较。 我们的方法在所有数据集上SSIM、RMSE和PSNR等性能指标更好。 SSIM和PSNR越高越好。 RMSE越低越好。
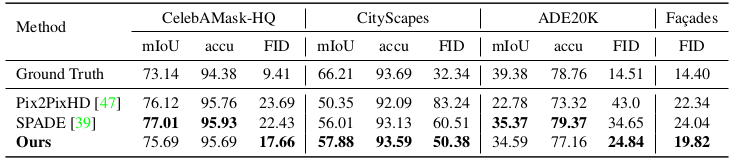
Table 2: 由mIoU和accu度量的语义分割性能和由FID度量的生成性能量化比较。 我们的方法在所有数据集上FID都更好。
Qualitative results. 我们在图6中展示了四个数据集的视觉比较。 我们可以观察到,我们的作品和SOTA之间的质量差异是显著的。例如,我们注意到SPADE和Pix2Pix不能处理更极端的姿势和老年人。我们推测,由于我们改进了风格编码,我们的网络更适合学习数据中更多的可变性。因为对于生成模型视觉效果是非常重要的, 我们推荐读者查看补充材料和视频获取更多的细节。我们的每区域风格编码还支持新的图像编辑操作: 使用每区域风格控制可迭代图像的编辑(参见图1和2), 风格插值和风格交叉(见图5和7)。

Figure 2: ADE20K 数据集的编辑序列。 (a) 源图像, (b)源图像的重构图像, (c-f) 展示了使用最上面一行风格图像的各种编辑。受编辑影响的区域显示为小插图。

Figure 5: 风格插值。 我们从源图像获取mask 并且 使用两种不同的风格图像重构(风格1 和 风格2), 这两种风格和源图像非常不同。 然后我们展示了每区域风格编码插值的结果。

Figure 7 : 风格交叉。 除了风格插值外(最下面一行), 我们可以对每个ResBlks选定不同的风格实现风格交叉。 我们在最上面两行显示两种转移。 图片上面蓝色/橙色的条指示六个ResBlk使用的风格。 我们能够观察到前面的层对大的特征影响大, 后面的层主要决定色彩等。
Variations of SEAN generator (Ablation studies). 在表3中, 我们的结构的变体和之前的工作在CelebAMask-HQ数据集上进行了比较。
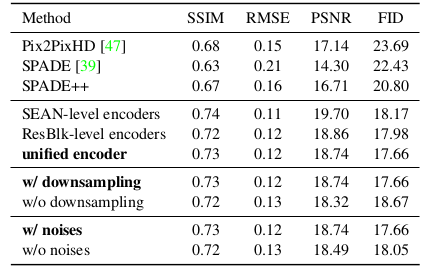
Table 3: 在CelebAMask-HQ数据集上的消融实验。 更多细节参见补充材料。
根据我们的研究, Pix2PixHD 比 SPADE 有一个更好的风格提取子网络(因为PSNR重构值更高), 但是SPADE有一个更好地生成器子网络(因为FID分数更高)。我们因此构造了一格网络,这个网络结合了Pix2PixHD的风格编码器和SPADE的生成器, 我们叫它SPADE++。我们可以看到SPADE++提升了SPADE一点, 但是我们所有的结构变体仍然有着更好的FID和PSNR分数。
为了评估我们的设计选择, 我们汇报了我们编码器的变体的表现。 首先我们比较了三种编码风格的变体: SEAN-level 编码器, ResBlk-level 编码器, 以及联合的编码器。 一个基本的设计选择是如何将风格计算拆分成两个部分: 在风格编码器共享计算 以及 在每个SEAN block 中的每层计算。 前两个变体执行每层的所有风格提取,而统一编码器是本文主要部分描述的体系结构。另外两种编码器具有更好的重建性能,但会导致较低的FID分数。基于视觉效果,我们也证实了统一的编码器可以带来更好的视觉质量。这对于困难的输入尤其明显(见补充材料)。其次,我们 评估 风格编码器中下采样是否是一个 好的想法,并评估具有bottleneck(具有下采样)的风格编码器和使用较少下采样的另一个编码器。这个测试证实了在风格编码器中引入 bottleneck 是一个好的想法。最后,我们测试了可学习噪声的影响。我们发现可学习噪声可以帮助提高相似性(PSNR)和FID性能。补充材料中提供了可替代的体系结构的更多细节。
Conclusion
我们提出语义区域自适应规范化(SEAN), 一个用于 以语义分割masks为条件的生成对抗网络 的 简单且有效的块, 该语义分割mask描述了想要输出图像的语义区域。 我们的想法是拓展目前最好的网络SPADE,以分别控制每个语义区域的风格。 我们引入一个新的块, SEAN规范化, 它能够从一个给定风格图像提取风格用于语义区域, 并且处理风格信息变成空间变化的规范化参数形式。 我们在多个数据集上评估了SEAN 并且 汇报了比目前SOTA更好的量化结果(比如 FID, PSNR) 。 尽管SEAN用于分别为每个区域指定风格, 我们对所有区域提供一种风格的这种设置上也取得了巨大的提升。总之, 根据重构质量、多样性以及视觉效果, SEAN=比之前工作更适合编码、迁移以及合成。SEAN也推动了图像交互式编辑的前沿。 在未来的工作中,我们计划将SEAN扩展到处理网格、点云和曲面上的纹理。
Appendix
A. Additional Implementation Details
Generator. 我们的生成器由几个SEAN ResBlks组成。 它们之间都跟着一个最近邻插值上采样层。 注意, 我们只在前 6 个 SEAN ResBlks 插入风格编码 ST。 其他的输入被注入所有的 SEAN ResBlks。 生成器的结构如图8所示。
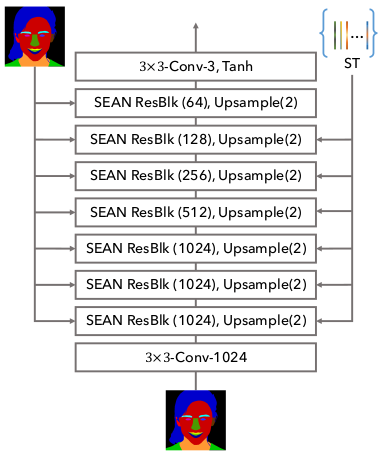
Figure 8 : SEAN生成器。 风格编码 ST 以及 分割 masks 送入生成器 通过提出的 SEAN ResBlks。特征图通道数在每个SEAN ResBlk后的括号中。 为了更好地描述结构, 我们在图中省略了可学习的噪声输入 以及 每风格的卷积层。 这些细节在 论文的图3中(见 $A_{ij}$ 和 $B_{ij}$)。
Discriminator. 和 SPADE [39] 和 Pix2PixHD [47] 一样, 我们使用了两种尺度的判决器, 它使用了实例规范化(IN)以及Leaky ReLU (LReLU)。 类似于 SPADE, 我们在判决器的所有卷积层使用了谱规范化 [37]。 判决器的结构如图9所示。
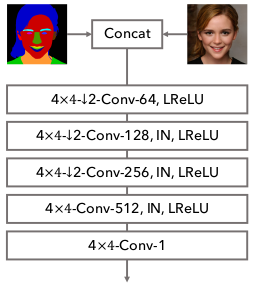
Figure 9: 和 SPADE 和 Pix2PixHD 一样, 我们的判决器将分割mask 和 风格图像的拼接 作为输入。 损失函数的计算方式 和 PatchGAN [23] 一样。
Style Encoder. 我们的风格编码器 由一个 “bottleneck”卷积神经网络 和 区域级 平均池化层(图11) 组成。 输入是风格图像 以及相关的分割mask, 它的输出是风格编码 ST。
Loss function. 我们的损失函数的设计是受到SPADE和Pix2PixHD的灵感启发的, 它包含3个部分:
(1) 对抗损失。 用 $E$ 表示风格编码, $G$ 表示 SEAN 生成器, $D_1$ 和 $D_2$ 是两个不同尺度[47]的判决器, $R$是给定的风格图像, $M$R的分割mask, 我们的条件对抗损失如下:
\[\min_{E, G} \max_{D_1, D_2} \sum_{k=1, 2} L_{GAN} (E, G, D_k)\]特别地, $L_{GAN}$使用Hinge loss 构造:
\[\begin{aligned} L_{GAN} &= E[max(0, 1 - D_k(R, M))] \\ &+ E[max(0, 1 + D_k(G(ST, M), M))] \end{aligned}\]其中 ST 是 在 $M$ 的引导下 由 E 提取出来的 R 的风格编码:
\[ST = E(R, M)\](2) 特征匹配损失 [47]。 用 $T$表示判决器 $D_k$ 的总层数, $D_k^{(i)}$ 和 $N_i$ 是分别是 输出特征图 以及 $D_k$的第 $i^{th}$层的元素数量, 我们用 $L_{FM}$ 表示特征匹配损失:
\[L_{FM} = E \sum_{i=1}^T \frac{1}{N_i} [\|D_{k}^{(i)}(R, M) - D_{k}^{(i)}(G(ST, M), M)\|_1]\](3) 感知损失[24]。 用 $N$ 表示用于计算感知损失的层的数量, $F^{(i)}$是 VGG网络[44]第 $i^{th}$ 层的输出特征图, $M_i$ 是 $F^{(i)}$ 的元素数量, 我们表示感知损失 $L_{percept}$:
\[L_{percept} = E \sum_{i=1}^N \frac{1}{M_i} [\| F^{(i)}(R) - F^{(i)}(G(ST, M)) \|_1]\]在我们的实验中最终的loss函数为上述提到的三项损失:
\[\min_{E, G} ((\max_{D_1, D_2} \sum_{k = 1, 2} L_{GAN}) + \lambda_1 \sum_{k=1, 2} L_{FM} + \lambda_2 L_{percept})\]和SPADE和 Pix2PixHD一样, 在我们的实验中设置 $\lambda_1 = \lambda_2 = 10$。
Training details. 我们对本文中提到的所有数据集进行了50个epoch的训练。在训练过程中,所有输入图像的分辨率都将调整为256×256,但CityScapes数据集[10]的图像将调整为512×256。我们使用Glorot初始化[14]来初始化我们的网络权重。
B. Additional Experimental Details
Table 3 (main paper). 补充正文表3第5行和第6行。 图10显示了样式编码器的两个变体(即SEAN-level 编码器和ResBlk-level 编码器)如何在SEAN ResBlk中使用。具体地说,SEAN0level 编码器为每个SEAN块提取不同的风格,而由ResBlk-level 编码器提取的相同风格编码被SEAN ResBlk内的所有SEAN块使用。
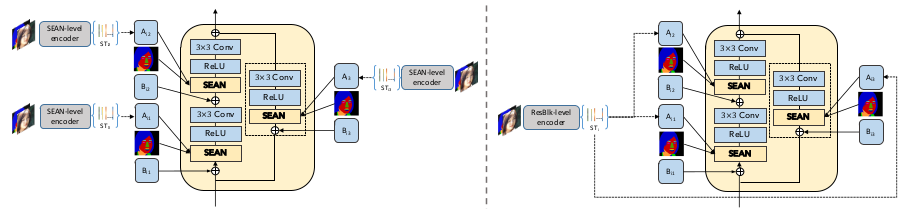
Figure 10: SEAN-level 编码器 和 ResBlk-level 编码器 在一个 SEAN ResBlk 中的详细使用。
Figure 6 (main paper). 我们使用真实数据作为所有方法的风格输入(论文中图6第二列)。对于 Pix2PixHD, 我们通过以下方式生成结果: (i) 编码风格图像为一个风格向量; (ii)广播这个风格向量并把它拼接到mask上作为生成器的输入。
Justification of Encoder Choice
图12展示了通过同一编码器生成的图像比SEAN-level的编码器生成的图像有更好的视觉效果, 尤其是有挑战性的输入(比如, 极限姿势, 没有标签的区域), 这证实了我们统一编码器的选择。

Figure 12: 证明编码器的选择。 Encoder1 是 SEAN-level 编码器 并且 Encoder2 是统一编码器。 SEAN-level编码器由于过拟合对风格图像的姿势和未标注的区域更加敏感。使用统一编码器能够得到更加健壮的风格迁移结果。
Additional Analysis
ST-branch vs. Mask-branch. ST-branch 和 mask-branch 的贡献有一个线性组合决定(参数 $\alpha_\beta$ 和 $\alpha_\gamma$)。 参数的结果通常在 0.35 到 0.7 意味着 两个分支都对结果有贡献。 如图13所示。丢掉 mask-branch 是完全有可能的, 但是它的结果将会变差。 我们的直觉是 mask 分支提供了大致的结构 而 ST-branch 提供了额外的信息。 然而,最终,相互作用是相当复杂的,不能仅仅通过改变混合参数来理解。
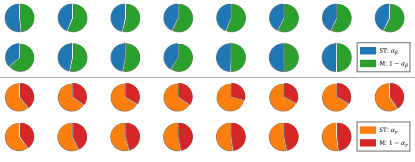
Figure 13: ST-branch 和 Mask-branch 对于每个 SEAN 规范化块的贡献。 饼状图和SEAN规范化块是一一对应的关系。
Extreme Cases. 为了进一步验证SEAN在纹理迁移中的作用, 我们展示了将艺术图像的高度复杂纹理迁移到人脸中(图 14)。

Figure 14: 复杂纹理迁移。
此外, 我们的方法是高度灵活的, 它允许用户在任意不合理的位置添加语义区域(图 15)。

Figure 15: Spatially-flexible painting. 我们的方法允许用户把眼睛放在脸上的任意一个地方。
User Study
我们使用Amazon Mechanical Turk(AMT)进行了用户偏好研究,以说明我们优于现有方法的重建结果(表4)。具体来说,我们创建了600个问题供AMT员工回答。最后,575名AMT工人回答了我们的问题。针对每个问题,我们向用户展示了一组5幅图像:真实图像、相应的分割mask和我们的方法、Pix2PixHD[47]和 SPADE[39] 所获得的3幅重建图像。 然后要求用户选择最接近真实情况且伪影最少的重建图像。为了减轻图像顺序的影响,进行公平比较,我们随机选取了100个图像集,通过列举每个图像集中3个重建图像的6个可能顺序,产生了600个问题。

Table 4: 用户偏好调研(CelebAMask-HQ dataset)。 我们的方法比 Pix2PixHD 和 SPADE 好很多。
QA
Q1: 风格插值是怎么做的?
Q2: 风格交叉是怎么做的?