Blog
尽管深度学习已经彻底改变了计算机视觉,但当前的方法仍存在几个主要问题:典型的视觉数据集需要大量的劳动力,并且创建成本很高,而只学习一组狭窄的视觉概念;标准视觉模型擅长且只擅长一项任务,并且需要花费大量的精力来适应新的任务;在 benchmark 测试中表现良好的模型在压力测试中的表现令人失望, 这让人们对计算机视觉的整个深度学习方法产生了怀疑。
我们提出了一种旨在解决这些问题的神经网络:它在各种各样的图像上进行训练,并在互联网上大量提供各种各样的自然语言监督。通过设计,该网络可以用自然语言指导执行各种分类benchmark,而无需直接优化 benchmark 的性能,类似于GPT-2和GPT-3的 zero-shot 学习能力。这是一个关键的变化:通过对 benchmark 的直接优化,我们表明它变得更具表征性:我们的系统在不使用任何原始1.28M标记样本的情况下,将 ResNet-50 在 ImageNet zero-shot 的性能匹配时,将此“robustness gap”缩小了75%。
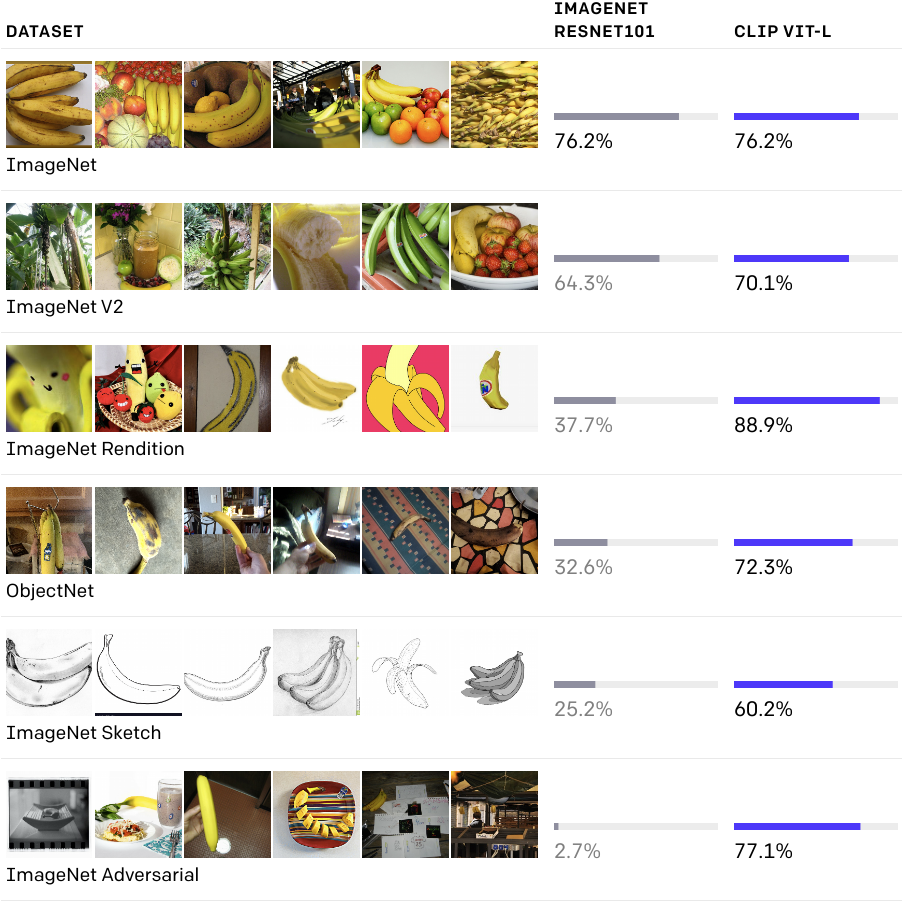
尽管两种模型在ImageNet测试集上具有相同的准确性, CLIP在不同的、非imagenet设置中数据集上的测量精度表明它更具表征性。例如,ObjectNet检查模型的能力通过识别家中许多不同姿态和不同背景的物体,而ImageNet Rendition和ImageNet Sketch检查模型识别物体的能力通过识别更抽象的描述。
Background and related work
CLIP (Contrastive Language–Image Pre-training)建立在 zero-shot 迁移,自然语言监督和多模态学习的大量工作之上。零数据学习的概念可以追溯到十多年前,但直到最近才主要在计算机视觉中 作为当一种不知道物体类别时的方法 被研究。一个关键的见解是利用自然语言作为一个 灵活的预测空间 来实现泛化和迁移。2013年,斯坦福大学的Richer Socher和他的合著者开发了一个概念证明,他们在CIFAR-10上训练了一个模型,在词向量嵌入空间中做出预测,并证明该模型可以预测两个没见过的类。同年,DeVISE对这种方法进行了扩展,并证明了对ImageNet模型进行微调是可能的,这样它就可以推广到正确预测原来1000个训练集之外的对象。
最鼓舞人心的CLIP 是李安和他的合著者在 FAIR 的工作,他们在2016年演示了使用自然语言监督使 zero-shot 迁移到几个现有的计算机视觉分类数据集,如典型的ImageNet数据集。他们通过对ImageNet CNN进行微调,从3000万张Flickr照片的标题、描述和标签文本中预测出更广泛的视觉概念(visual n-grams),并在ImageNet zero-shot中达到11.5%的准确性。
最后,CLIP是一组论文的一部分,这些论文回顾了过去一年里从自然语言监督中学习视觉表征。这项工作使用了更现代的架构,如Transformer,并包括VirTex,它探索了自回归语言建模,ICMLM,它研究了masked language modeling, 以及ConVIRT,它研究了我们用于CLIP的相同的对比目标,但是是在医学图像领域。
Approach
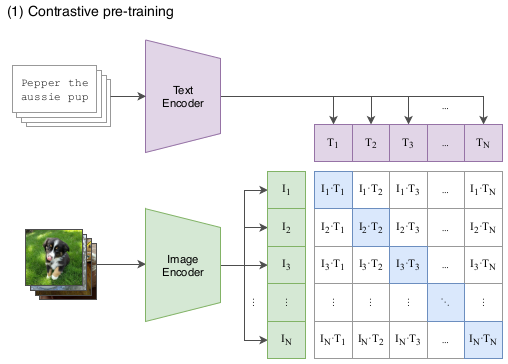
我们证明,缩放一个简单的训练前任务足以在多种图像分类数据集上实现有竞争力的 zero-shot 性能 我们的方法使用了大量可用的监督源: 在互联网上找到的匹配的文本和图片。该数据用于为CLIP创建以下代理训练任务: 给定一张图像,预测在32,768个随机抽样文本片段中,哪一个在我们的数据集中与之配对。
为了解决这个任务,我们的直觉是CLIP模型将需要学习识别图像中各种各样的视觉概念,并将它们与其名称联系起来。因此,CLIP模型可以应用于几乎所有的视觉分类任务。例如,如果数据集的任务是对狗和猫的照片进行分类,我们就会使用CLIP模型预测每个图像的文本描述”a photo of a dog” 或 “a photo of a cat” 哪个更可能和它配对。
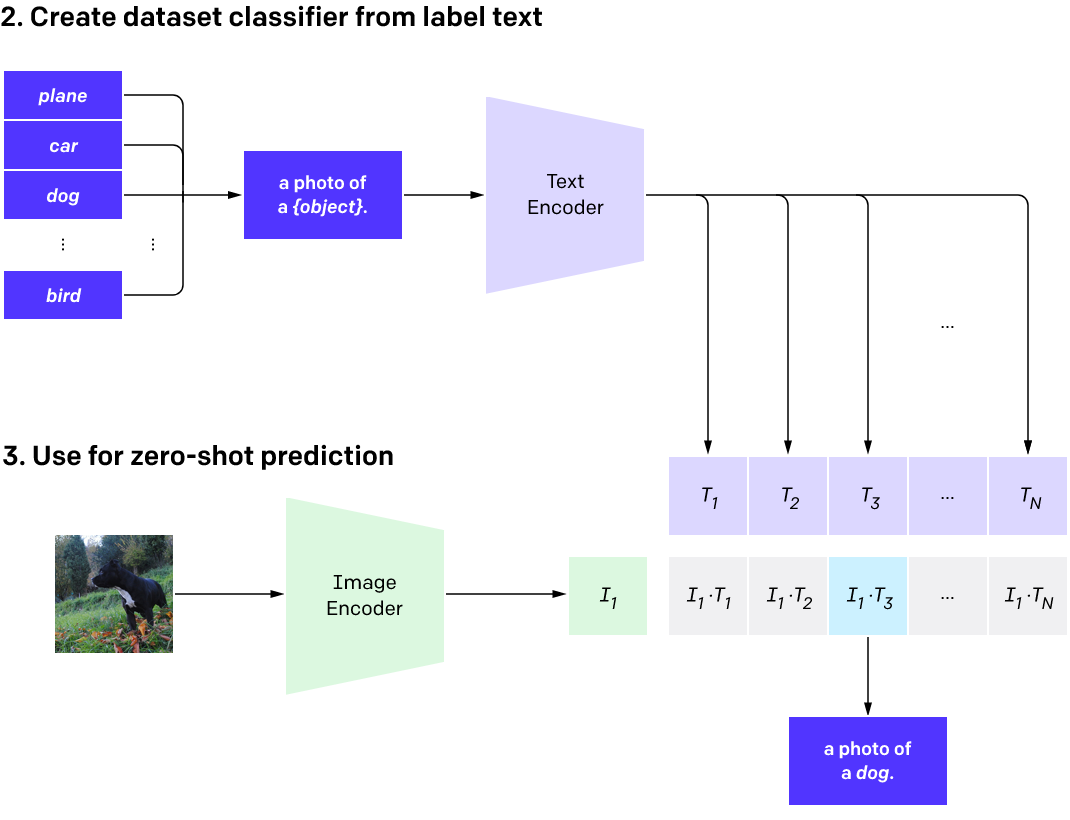
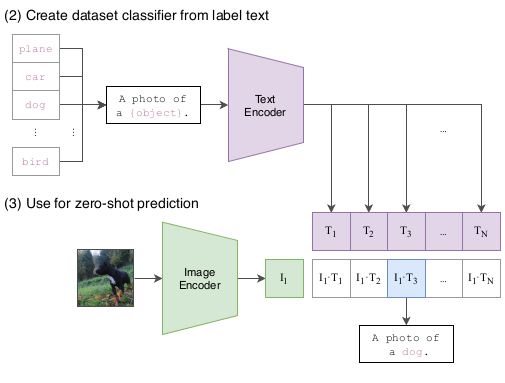
CLIP对图像编码器和文本编码器进行预处理,以预测数据集中哪些图像与哪些文本配对。然后,我们使用这个表现将CLIP转换为 zero-shot 分类器。我们将数据集的所有类转换为标题,比如“a photo of a dog” ,并预测 一张给定图像 CLIP估计最佳的 配对标题的种类。
CLIP的设计是为了缓解计算机视觉标准深度学习方法中的一些主要问题:
Costly datasets: 深度学习需要大量的数据,而视觉模型传统上是在人工标记的数据集上进行训练的,而这些数据集的构建成本昂贵,而且只能对有限数量的预先定义的视觉概念提供监督。ImageNet数据集是这一领域最大的努力之一,需要超过25000名工作人员为22000个对象类别注释1400万张图像。相比之下,CLIP从已经在互联网上公开的文本图像对中学习。减少对昂贵的大型标记数据集的需要已经在以前的工作中得到了广泛的研究,特别是自监督学习, 对比方法, 自训练方法, 以及生成模型。
Narrow ImageNet模型很擅长预测1000个ImageNet类别,但这就是它所能做的全部。如果我们希望执行任何其他任务,ML从业者需要构建一个新的数据集,添加一个输出头,并对模型进行微调。相比之下,CLIP可以用于执行各种各样的视觉分类任务,而不需要额外的训练示例。要将CLIP应用到新任务,我们所需要做的就是告诉CLIP文本编码器任务视觉概念的名称,然后它将输出CLIP视觉表征的线性分类器。这种分类器的准确性可以与完全监督模型相竞争。
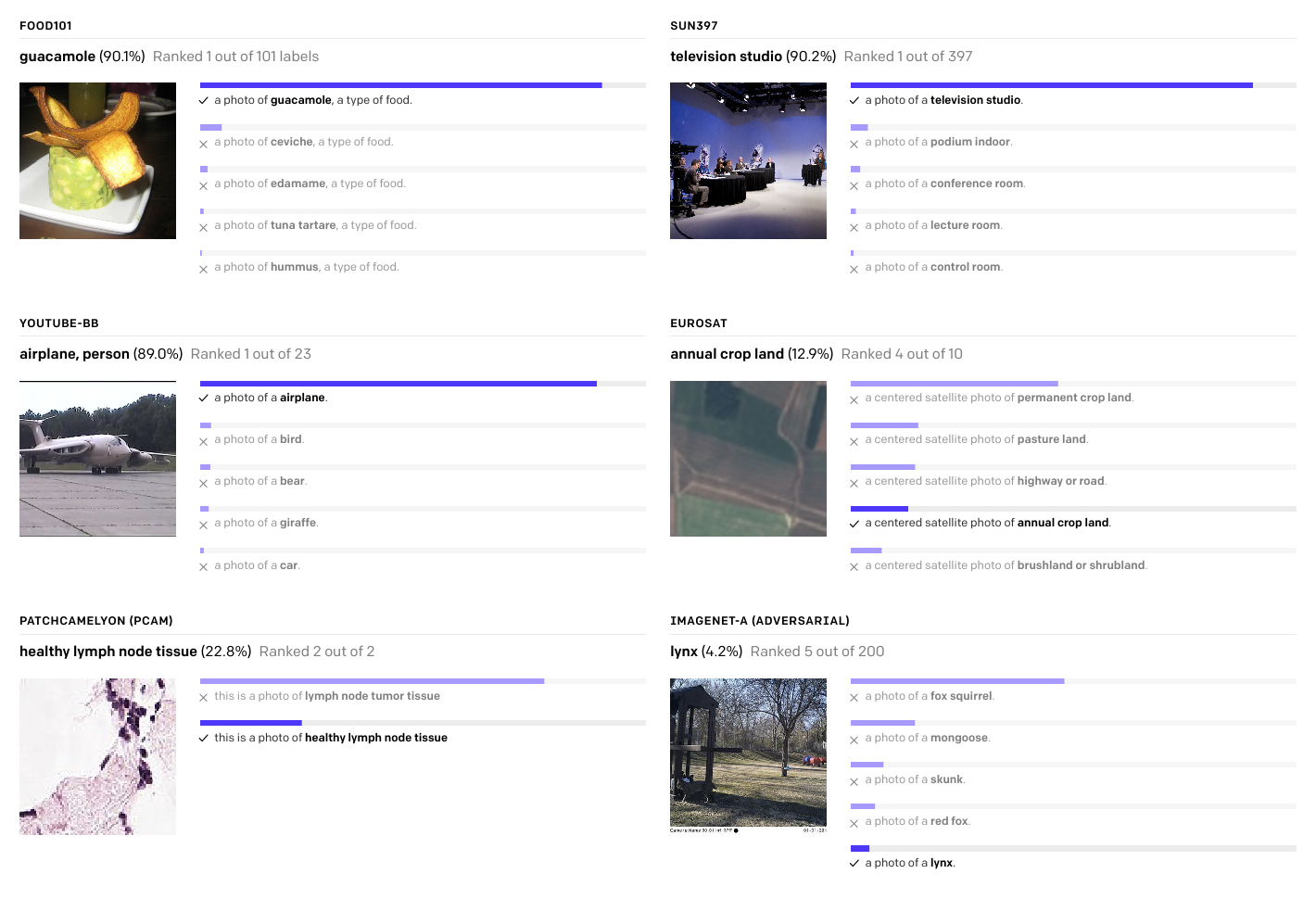
我们展示了随机的、非精心挑选的、 zero-shot CLIP分类器的预测,下面是来自不同数据集的例子。
Poor real-world performance: 据报道,深度学习系统通常可以实现人类甚至超过人类的表现 但当在部署时,它们的性能可能远远低于基准设定的预期。换句话说,基准性能和实际性能之间存在差距。我们推测之所以会出现这种差距,是因为模型只根据基准测试的表现进行了优化,就像一个学生只学习过去几年的考试问题就通过了考试一样。相比之下,CLIP模型可以在基准测试上进行评估,而不必对其数据进行训练,因此它不能以这种方式作弊。这使得它的基准性能更能代表其在部署时的性能。为了验证作弊假说,我们还测量了当CLIP可以ImageNet进行学习时,它的性能是如何变化的。当线性分类器被拟合在CLIP特征上时,它可以提高CLIP在ImageNet测试集上的准确率近10%。然而,在其他7个衡量“鲁棒性”性能的数据集的评估中,该分类器的平均性能并没有提高。
Key takeaways
CLIP is highly efficient
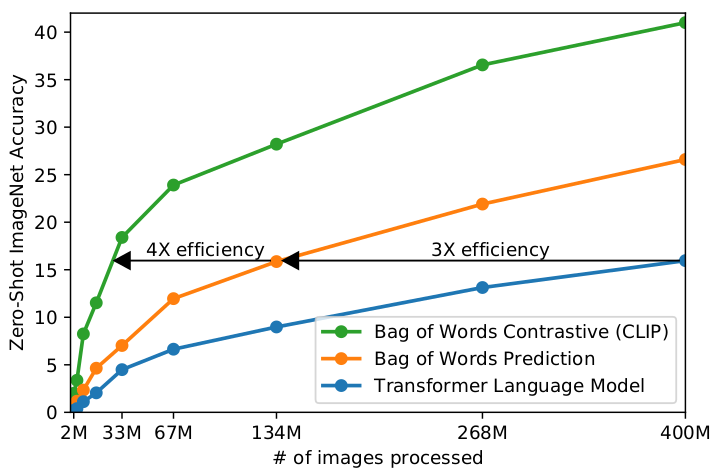
CLIP从未经过滤、高度变化和高度噪声的数据中学习,并旨在以 zero-shot 的方式使用。我们从GPT-2和GPT-3中知道,根据这些数据训练的模型可以实现令人信服的 zero-shot 性能。然而,这样的模型需要大量的训练计算。为了减少所需的计算量,我们着重研究了提高训练效率的算法方法。
我们报告了两种可显著节省计算的算法选择。第一种选择是采用对比目标来连接文本和图像。我们最初探索了一种类似于VirTex的图像到文本的方法, 但在扩展这一功能以实现最先进的性能方面遇到了困难。在小型到中型规模的实验中,我们发现CLIP使用的对比目标在 zero-shot 的ImageNet分类中效率是4到10倍。第二种选择是采用Vision Transformer,它使我们的计算效率比标准的ResNet提高了3倍。最后,我们的CLIP模型在256个GPU上运行了2周,与现有的大规模图像模型相似。
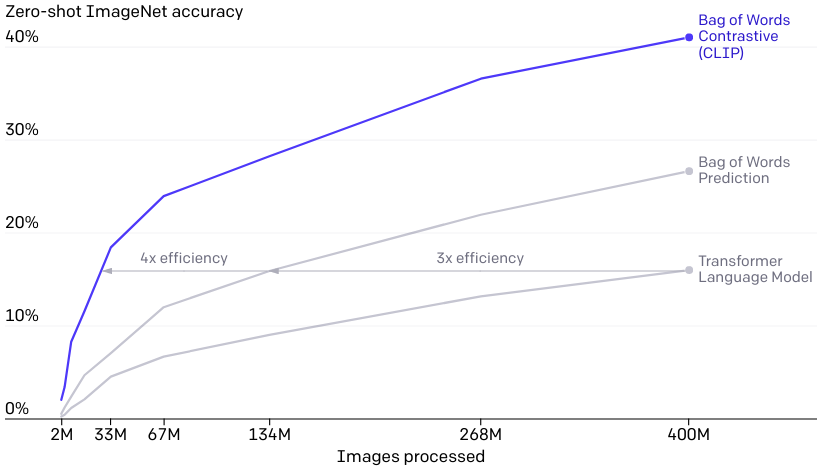
我们最初探索的是训练图像到标题的语言模型,但发现这种方法在 zero-shot 迁移方面遇到了困难。在这个16天的GPU实验中,一个语言模型在对4亿张图像进行训练后,在ImageNet上只能达到16%的准确率。CLIP的效率更高,达到同样的精度大约快10倍。
CLIP is flexible and general
因为他们直接从自然语言中学习了大量的视觉概念, CLIP模型比现有的ImageNet模型更加灵活和通用。我们发现他们能够 zero-shot 执行许多不同的任务。为了验证这一点,我们在30多个不同的数据集上测量了CLIP的 zero-shot 性能,这些数据集包括fine-grained对象分类、地理定位、视频中的动作识别和OCR。特别是,学习OCR是标准ImageNet模型中不会出现的令人兴奋的表现的一个例子。在上面,我们从每个 zero-shot 分类器中可视化一个随机非精心选择的预测。
这一发现也反映在使用 linear probes 的标准表征学习评价上。在我们测试26个不同的迁移数据集中的20个数据集中, 最好的CLIP模型优于最好的公共可用的ImageNet模型Noisy Student EfficientNet-L2。
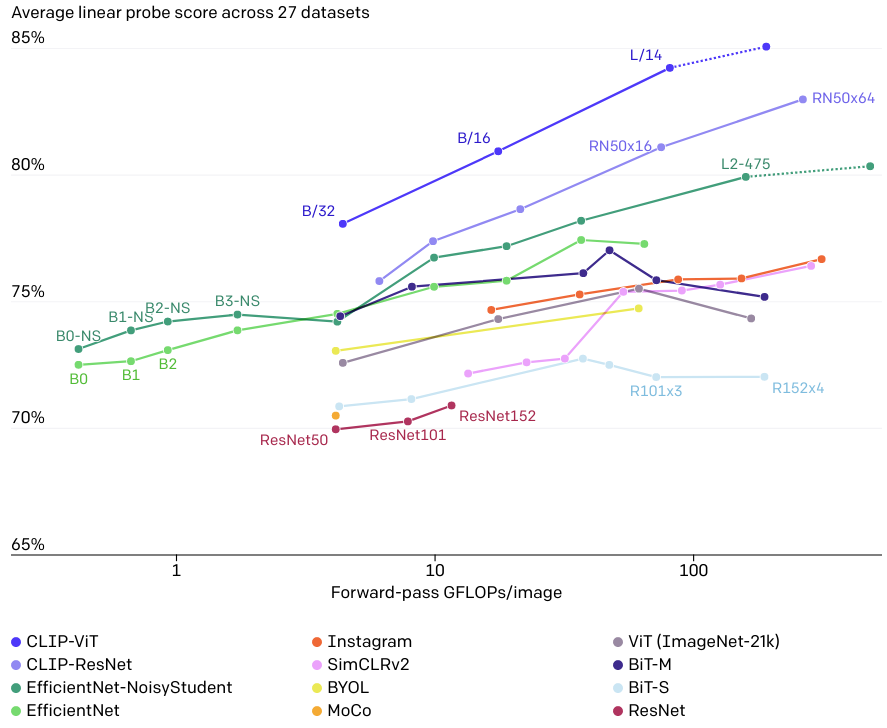
通过27个数据集的测试任务,如细粒度对象分类、OCR、视频中的活动识别和地理定位,我们发现CLIP模型可以学习更广泛有用的图像表征。CLIP模型的计算效率也比我们之前比较的10种方法的模型更高。
Limitations
虽然CLIP通常在识别普通物体上表现得很好,但在更抽象或更系统的任务(如计算图像中物体的数量)和更复杂的任务(如预测照片中最近的汽车有多近)上却表现得很困难。在这两个数据集上, zero-shot CLIP只比随机猜测好一点点。与特定任务模型相比,Zero-shot CLIP在非常细粒度的分类上也很困难,比如区分汽车模型、飞机变体或花卉品种之间的差异。
CLIP对于训练前数据集中未覆盖的图像仍有较差的泛化能力。例如,尽管CLIP学习了一个有能力的OCR系统,但当从MNIST数据集中对手写数字进行评估时, zero-shot CLIP只能达到88%的准确率,远低于数据集中人类的99.75%。最后,我们观察到CLIP的 zero-shot 分类器对 wording 或 phrasing 很敏感,有时需要trial 和 error “prompt engineering” 才能执行良好。
Broader impacts
CLIP允许人们设计自己的分类器,并消除了对特定任务训练数据的需要。这些类的设计方式会严重影响模型性能和模型偏差。例如,我们发现,当给定一组标签(包括Fairface race标签)和一些糟糕的标签(如“罪犯”、“动物”等)时,该模型倾向于将0-20岁的人的图像分类为糟糕的类别,分类率约为32.3%。然而,当我们将类的子类添加到可能的类列表中时,这种行为下降到~8.7%。
此外,由于CLIP不需要特定任务的训练数据,它可以更轻松地解锁特定的小众任务。其中一些任务可能会增加隐私或监视相关的风险,我们通过研究CLIP在名人识别方面的表现来探讨这一问题。CLIP在从100个候选人中选择名人图像时,其最高准确率为59.2%;在从1000个可能选项中选择时,其最高准确率为43.3%。虽然值得注意的是,通过 task agnostic pre-training 实现这些结果,但与广泛使用的生产级模型相比,这种表现并不具有竞争力。我们进一步探讨了CLIP在我们的论文中提出的挑战,我们希望这项工作能够推动未来对此类模型的能力、缺点和偏差的特性的研究。我们很高兴能在这类问题上与研究界接触。
Conclusion
通过CLIP,我们测试了在互联网规模的自然语言上的 task agnostic 预训练是否也可以用来提高其他领域的深度学习性能。我们对迄今为止将这种方法应用于计算机视觉的结果感到兴奋。就像GPT家族一样,CLIP在训练前学习各种各样的任务,我们通过 zero-shot 迁移来演示。我们在ImageNet上的发现也让我们感到鼓舞,该发现表明 zero-shot 评估是一个更有代表性的模型能力的衡量方法。
Paper
Abstract
最先进的计算机视觉系统训练预测一组固定的预定义对象类别。直接从原始文本中学习图像是一种很有前景的选择,它利用了更广泛的监督来源。我们展示了在从互联网上收集的4亿对(图像、文本)数据集上,预测哪个标题与哪个图像搭配的简单预训练任务 是 学习SOTA图像表征 的有效方法。在预训练之后,自然语言被用来引用学习到的视觉概念(或描述新的概念),从而实现模型到下游任务的 zero-shot 迁移。我们通过在30多个不同的现有计算机视觉数据集上进行基准测试来研究这种方法的性能,包括OCR、视频中的动作识别、地理定位和许多类型的细粒度对象分类等任务。例如,我们不需要使用128万个训练样本中的任何一个, 就可以在ImageNet zero shot上匹配原始ResNet-50的精度。
Introduction and Motivating Work
在过去的几年里,直接从原始文本中学习的预训练方法已经彻底改变了自然语言处理。Task-agnostic 目标(如autoregressive和masked language modeling )在计算、模型容量和数据方面已经扩展了许多数量级,稳步提高了能力。“文本到文本”作为标准化输入-输出接口的发展使得任务无关的体系结构能够 zero-shot 迁移到下游数据集,从而无需专门的输出头或特定数据集的定制。像GPT-3这样的旗舰系统现在在许多定制模型的任务中都具有竞争力,同时几乎不需要特定于数据集的训练数据。
这些结果表明,在互联网规模的文本集合中,现代预训练方法可获得的总体监督优于高质量的人类标记的NLP数据集。然而,在计算机视觉等其他领域,在人类标记数据集(如ImageNet)上预训练模型仍然是标准做法。直接从网络文本中学习的预训练方法能否在计算机视觉领域取得类似的突破?受到先前的工作的启发。Joulin等人(2016)对这一工作进行了现代化改造,并证明经过训练的CNN能够预测图像标题中的单词,从而学习有用的图像表征。
20多年前,Mori等人(1999)通过训练一个模型来预测与图像配对的文本中的名词和形容词,探索改进了基于内容的图像检索。Quattoni等人(2007)证明,通过训练分类器的权值空间中的流形学习,可以学习更有效的图像表征,以预测与图像相关的标题中的单词。Srivastava和Salakhutdinov(2012)通过在底层图像和文本标签特征的基础上训练多模态深度Boltzmann机器,探索了深度表征学习。他们将YFCC100M数据集中的图像的标题,描述和主题标签元数据转换为词袋式多标签分类任务,并表明对AlexNet进行预训练以预测这些标签学习的表征方式类似于基于ImageNet在迁移任务的预训练 。Li等人(2017)随后将该方法扩展到除单个单词外的短语n-gram预测,并通过根据学习的视觉n-gram字典对目标类进行评分并预测得分最高的目标类,证明了他们的系统能够将 zero-shot 迁移到其他图像分类数据集。VirTex、ICMLM和ConVIRT采用了最新的体系结构和预训练方法,最近展示了基于 Transformer 的 language modeling、masked language modeling和contrastive objectives从文本中学习图像表示的潜力。
虽然概念被证明是令人兴奋的 ,使用使用自然语言监督图像表示学习仍然十分罕见。这很可能是因为在常见的 benchmarks 上的表现远远低于其他方法。例如,Li等人(2017年)在 zero-shot 设置下,ImageNet的准确率仅为11.5%。这远远低于目前技术水平的88.4%的准确性(谢等,2020年)。它甚至低于经典计算机视觉方法50%的精确度(邓等,2012)。相反,范围更窄但目标明确的弱监督的使用提高了性能。Mahajan等人(2018)表明,预测Instagram图像与ImageNet相关的标签是一项有效的预训练任务。当在ImageNet上微调时,这些预训练的模型将精确度提高了5%以上,并改善了当时的整体技术水平。Kolesnikov等人(2019)和Dosovitskiy等人(2020)还通过预训练模型来预测带有噪声标签的JFT-300M数据集的类别,从而在更广泛的迁移 benchmarks 上证明了巨大的收益。
这些弱监督模型与最直接从自然语言学习图像表征之间的一个重要区别是规模。在这项工作中,我们大规模研究了在自然语言监督下训练的图像分类器的行为。借助互联网上这种形式的大量公开数据,我们创建了一个包含 4 亿(图像、文本)对的新数据集,并展示了从头开始训练的 ConVIRT 的简化版本,我们称之为 CLIP(Contrastive Language -Image Pre-training),是一种从自然语言监督中学习的有效方法。
Blog
介绍
OpenAI开放了一些与CLIP模型相关的代码,但我发现它令人生畏,它远不是什么简短和简单的东西。我还遇到了一个很好的教程,灵感来自Keras代码示例上的CLIP模型,我将其中的一些部分迁移到PyTorch中,完全用我们喜爱的PyTorch构建了这个教程!
CLIP是什么?为什么它有趣?
在Learning Transferable Visual Models From Natural Language Supervision 文章中, OpenAI介绍了他们的新模型,叫做CLIP,用于对比语言-图像预训练。简而言之,该模型学习整个句子与其描述的图像之间的关系;在某种意义上,当模型被训练时,给定一个输入句子,它将能够检索出与该句子最相关的图像。重要的是,它是在完整的句子中训练的,而不是像car, dog等单一的类别。直觉告诉我们,当对整个句子进行训练时,该模型可以学习更多的东西,并在图像和文本之间找到一些模式。
他们还表明,当这个模型在一个巨大的图像和相应的文本数据集上进行训练时,它也可以作为一个分类器。仅举一个例子,使用这种策略训练的CLIP模型对ImageNet的分类比那些在ImageNet上训练的SOTA模型更好,这些SOTA模型针对分类任务进行了优化。
让我们看看本文从头构建的最终模型能够实现什么: 给定 “a boy jumping with skateboard” 或 “a girl jumping from swing”这样的查询,模型将检索最相关的图像:

开始
首先,我们需要一个包含图像和一些描述它们的文本的数据集。网上有很多这样的网站。我们将使用Flickr 8k数据集(你可以使用30k版本,它更大,最终的模型将表现更好),它主要用于Image Captioning任务。但是,这是没有限制的,我们也可以使用它来训练CLIP模型。
关于这个数据集需要注意的一点是,每个图像都有5个标题。
数据集
我们需要对图像和它们的描述文本进行编码。因此,数据集需要返回图像和文本。当然,我们不会将原始文本提供给我们的文本编码器。 我们将使用来自 HuggingFace 库的 DistilBERT 模型(比BERT小,但性能几乎和BERT一样好)作为我们的文本编码器。 因此,我们需要用 DistilBERT tokenizer 对句子(标题)进行分词,然后将token id(input_ids)和attention masks提供给DistilBERT。因此,数据集还需要处理 tokenization。下面可以看到数据集的代码。下面我将解释代码中发生的最重要的事情。
关于config和CFG的注意事项:我用python脚本编写代码,然后把它转换成一个jupiter Notebook。 因此,在python脚本的情况下,config是一个普通的python文件,我放置所有的超参数,在jupiter Notebook的情况下,它是一个在 Notebook 的开始定义的类,以保存所有的超参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
import os
import cv2
import torch
import albumentations as A
import config as CFG
class CLIPDataset(torch.utils.data.Dataset):
def __init__(self, image_filenames, captions, tokenizer, transforms):
"""
image_filenames and cpations must have the same length; so, if there are
multiple captions for each image, the image_filenames must have repetitive
file names
"""
self.image_filenames = image_filenames
self.captions = list(captions)
self.encoded_captions = tokenizer(
list(captions), padding=True, truncation=True, max_length=CFG.max_length
)
self.transforms = transforms
def __getitem__(self, idx):
item = {
key: torch.tensor(values[idx])
for key, values in self.encoded_captions.items()
}
image = cv2.imread(f"{CFG.image_path}/{self.image_filenames[idx]}")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = self.transforms(image=image)['image']
item['image'] = torch.tensor(image).permute(2, 0, 1).float()
item['caption'] = self.captions[idx]
return item
def __len__(self):
return len(self.captions)
def get_transforms(mode="train"):
if mode == "train":
return A.Compose(
[
A.Resize(CFG.size, CFG.size, always_apply=True),
A.Normalize(max_pixel_value=255.0, always_apply=True),
]
)
else:
return A.Compose(
[
A.Resize(CFG.size, CFG.size, always_apply=True),
A.Normalize(max_pixel_value=255.0, always_apply=True),
]
)
在 __init__ 函数中, 我们接收一个 tokenizer object, 它实际上是一个 HuggingFace tokinzer; 这个 tokenizer 将在运行模型时加载。我们 padding 和 truncating 标题到一个指定的最大长度。在 __getitem__ 中, 我们将会首先加载一个编码后的 标题, 它是一个字典, key为 input_ids 和 attention_mask, 将它的值变为张量。然后我们将会加载对应的图像, 转换并增强它, 然后我们将它变成一个张量并且把它放入字典的key为 image 的value中。 最后,我们将标题的原始文本放入字典的 key 为 “caption”的 value 中,仅用于可视化目的。
图像编码器
图像编码器的代码很简单。我在这里使用的是PyTorch Image Models library (timm),它可以提供许多不同的图像模型,从ResNets到EfficientNets等。这里我们将使用ResNet50作为我们的图像编码器。如果你不想安装一个新的库,你可以很容易地使用torchvision库来使用ResNets。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class ImageEncoder(nn.Module):
"""
Encode images to a fixed size vector
"""
def __init__(
self, model_name=CFG.model_name, pretrained=CFG.pretrained, trainable=CFG.trainable
):
super().__init__()
self.model = timm.create_model(
model_name, pretrained, num_classes=0, global_pool="avg"
)
for p in self.model.parameters():
p.requires_grad = trainable
def forward(self, x):
return self.model(x)
该代码将每个图像编码为一个固定大小的向量,其大小为模型的输出通道的大小(在ResNet50的情况下,向量大小将是2048)。这是nn.AdaptiveAvgPool2d()层之后的输出。
文本编码器
我们使用 DistilBERT 作为文本编码器。 像BERT一样, 两个特殊的 tokens 将会被添加到真正的输入tokens: CLS 和 SEP 标记一个句子的开始和结束。 为了获取一个句子的整个表征(正如相关的 BERT 和 DistilBERT 论文指出的那样),我们使用CLS token的最终表征,我们希望这个表征能够捕获句子的整体含义(caption), 就像我们把图像转换成固定大小的向量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from transformers import DistilBertModel, DistilBertConfig
class TextEncoder(nn.Module):
def __init__(self, model_name=CFG.text_encoder_model, pretrained=CFG.pretrained, trainable=CFG.trainable):
super().__init__()
if pretrained:
self.model = DistilBertModel.from_pretrained(model_name)
else:
self.model = DistilBertModel(config=DistilBertConfig())
for p in self.model.parameters():
p.requires_grad = trainable
# we are using the CLS token hidden representation as the sentence's embedding
self.target_token_idx = 0
def forward(self, input_ids, attention_mask):
output = self.model(input_ids=input_ids, attention_mask=attention_mask)
last_hidden_state = output.last_hidden_state
return last_hidden_state[:, self.target_token_idx, :]
在 DistilBERT (以及BERT)的情况下,每个token的输出隐藏表征是一个大小为768的向量。因此,整个caption将被编码在大小为768的 CLS token 表征中。
Projection Head
我们已经将图像和文本编码成固定大小的向量(2048表示图像,768表示文本),我们需要将它们带到一个新的空间, 这个空间图像和文本具有相似的维度,以便能够进行比较,将不相关的图像和文本分开,并将匹配的图像和文本拉到一起。
因此,下面的代码将把2048维和768维的向量带入256维(投影维度)的空间,在那里我们可以比较它们:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import torch
from torch import nn
class ProjectionHead(nn.Module):
def __init__(
self,
embedding_dim,
projection_dim=CFG.projection_dim,
dropout=CFG.dropout
):
super().__init__()
self.projection = nn.Linear(embedding_dim, projection_dim)
self.gelu = nn.GELU()
self.fc = nn.Linear(projection_dim, projection_dim)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(projection_dim)
def forward(self, x):
projected = self.projection(x)
x = self.gelu(projected)
x = self.fc(x)
x = self.dropout(x)
x = x + projected
x = self.layer_norm(x)
return x
embedding_dim 是输入向量的大小(2048为图像,768为文本),projection_dim 是输出向量的大小,在我们的例子中是256。
CLIP Model
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
import torch
from torch import nn
import torch.nn.functional as F
import config as CFG
from modules import ImageEncoder, TextEncoder, ProjectionHead
class CLIPModel(nn.Module):
def __init__(
self,
temperature=CFG.temperature,
image_embedding=CFG.image_embedding,
text_embedding=CFG.text_embedding,
):
super().__init__()
self.image_encoder = ImageEncoder()
self.text_encoder = TextEncoder()
self.image_projection = ProjectionHead(embedding_dim=image_embedding)
self.text_projection = ProjectionHead(embedding_dim=text_embedding)
self.temperature = temperature
def forward(self, batch):
# Getting Image and Text Features
image_features = self.image_encoder(batch["image"])
text_features = self.text_encoder(
input_ids=batch["input_ids"], attention_mask=batch["attention_mask"]
)
# Getting Image and Text Embeddings (with same dimension)
image_embeddings = self.image_projection(image_features)
text_embeddings = self.text_projection(text_features)
# Calculating the Loss
logits = (text_embeddings @ image_embeddings.T) / self.temperature
images_similarity = image_embeddings @ image_embeddings.T
texts_similarity = text_embeddings @ text_embeddings.T
targets = F.softmax(
(images_similarity + texts_similarity) / 2 * self.temperature, dim=-1
)
texts_loss = cross_entropy(logits, targets, reduction='none')
images_loss = cross_entropy(logits.T, targets.T, reduction='none')
loss = (images_loss + texts_loss) / 2.0 # shape: (batch_size)
return loss.mean()
def cross_entropy(preds, targets, reduction='none'):
log_softmax = nn.LogSoftmax(dim=-1)
loss = (-targets * log_softmax(preds)).sum(1)
if reduction == "none":
return loss
elif reduction == "mean":
return loss.mean()
在这里,我们将使用之前构建的用于实现主模型的模块。在前向函数中,我们首先将图像和文本分别编码为固定大小(不同维度)的向量。在此之后,使用单独的投影模块,我们将它们投射到前面提到的共享空间中。这里的编码将变成相同的形状(在我们的例子中是256)。然后我们再计算损失。
在线性代数中,衡量两个向量是否具有相似特征(它们彼此相似)的一种常见方法是计算它们的点积(将匹配项相乘,然后取它们的和);如果最终的数字大,它们是相似的,如果它小,它们就不相似(相对而言)。
注: 单位向量的是话成立的,因为点积就是余弦距离,越大夹角越接近于0。否则不成立。亦或,在过完归一化类型的激活函数之后,大体也能成立,因为 ||vector|| 不会太大。
现在我们有图像嵌入矩阵, 形状为(batch_size,256)和文本嵌入矩阵, 形状为(batch_size,256)。这意味着我们有两组向量,而不是两个单独的向量。我们如何度量两组向量(两个矩阵)之间的相似性?使用点积。为了能把这两个矩阵相乘,我们把第二个矩阵转置。我们得到一个形状为(batch_size, batch_size)的矩阵,我们称之为logits。现在我们有了logits,我们需要target。
让我们考虑一下我们希望这个模型能学到什么:我们想让它对给定的图像和描述它的标题学习类似的表征(向量)。也就是说,我们给它一个图像或者描述它的文本,我们想让它们产生相同大小的256维的向量。
所以,在最好的情况下,文本嵌入和图像嵌入矩阵应该是相同的,因为它们描述的是相似的东西。我们现在想想,如果发生这种情况,logits矩阵会是什么样的?我们来看一个简单的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import torch
from torch import nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
batch_size = 4
dim = 256
embeddings = torch.randn(batch_size, dim)
out = embeddings @ embeddings.T
print(F.softmax(out, dim=-1))
-----------
# tensor([[1., 0., 0., 0.],
# [0., 1., 0., 0.],
# [0., 0., 1., 0.],
# [0., 0., 0., 1.]])
因此在这个最好的例子中, 如果我们对它取softmax, 对角线上将会为1.0(一个单位矩阵)。 由于损失函数的工作是使模型预测类似于目标(至少在大多数情况下!),我们需要这样一个矩阵作为我们的目标。这就是为什么我们在上面的代码块中计算图像相似度和文本相似度矩阵的原因。
现在我们已经得到了目标矩阵,我们将使用简单的交叉熵来计算实际损失。我们已经把交叉熵的完整矩阵形式写成了一个函数,可以在代码块的底部看到。
我承认在PyTorch中有一个更简单的方法来计算这个损失; 通过这样做:nn.CrossEntropyLoss()(logits, torch.arange(batch_size))。为什么我没有在这里使用它? 有两个原因:
- 我们使用的数据集对单个图像有多个标题; 因此,在一个batch中有可能存在两个相似标题的相同图像(这是罕见的,但它可能发生)。使用这种简单方式的loss将会忽略这种可能性并且模型学习将两个实际相同的分成两种不同的表征。 显然, 我们不希望这种情况发生, 因此我们以这种方式计算整个 target matrix 来处理这种极少见出现的情况。
- 这样做,让我们更好地理解这个损失函数中发生了什么;
训练
这里有一个方便的函数来训练我们的模型。这里仅仅是加载batches, 将它们喂给模型, 然后更新优化器,以及 lr_scheduler。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def train_epoch(model, train_loader, optimizer, lr_scheduler, step):
loss_meter = AvgMeter()
tqdm_object = tqdm(train_loader, total=len(train_loader))
for batch in tqdm_object:
batch = {k: v.to(CFG.device) for k, v in batch.items() if k != "caption"}
loss = model(batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step == "batch":
lr_scheduler.step()
count = batch["image"].size(0)
loss_meter.update(loss.item(), count)
tqdm_object.set_postfix(train_loss=loss_meter.avg, lr=get_lr(optimizer))
return loss_meter
我们完成了对模型的训练。现在,我们需要进行推理,在我们的例子中,将给模型一段文本,并希望它从一个没有见过的验证(或测试)集中检索最相关的图像。
得到图像嵌入
在这个函数中,我们将加载训练后保存的模型,将图像输入验证集,并返回图像嵌入(valid_set_size, 256)和模型本身。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def get_image_embeddings(valid_df, model_path):
tokenizer = DistilBertTokenizer.from_pretrained(CFG.text_tokenizer)
valid_loader = build_loaders(valid_df, tokenizer, mode="valid")
model = CLIPModel().to(CFG.device)
model.load_state_dict(torch.load(model_path, map_location=CFG.device))
model.eval()
valid_image_embeddings = []
with torch.no_grad():
for batch in tqdm(valid_loader):
image_features = model.image_encoder(batch["image"].to(CFG.device))
image_embeddings = model.image_projection(image_features)
valid_image_embeddings.append(image_embeddings)
return model, torch.cat(valid_image_embeddings)
Finding Matches
这个函数完成了我们希望模型能够完成的最后一个任务:它获得模型、图像嵌入和文本查询。它将显示验证集中最相关的图像!是不是很神奇?让我们看看它到底表现如何
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
def find_matches(model, image_embeddings, query, image_filenames, n=9):
tokenizer = DistilBertTokenizer.from_pretrained(CFG.text_tokenizer)
encoded_query = tokenizer([query])
batch = {
key: torch.tensor(values).to(CFG.device)
for key, values in encoded_query.items()
}
with torch.no_grad():
text_features = model.text_encoder(
input_ids=batch["input_ids"], attention_mask=batch["attention_mask"]
)
text_embeddings = model.text_projection(text_features)
image_embeddings_n = F.normalize(image_embeddings, p=2, dim=-1)
text_embeddings_n = F.normalize(text_embeddings, p=2, dim=-1)
dot_similarity = text_embeddings_n @ image_embeddings_n.T
# multiplying by 5 to consider that there are 5 captions for a single image
# so in indices, the first 5 indices point to a single image, the second 5 indices
# to another one and so on.
values, indices = torch.topk(dot_similarity.squeeze(0), n * 5)
matches = [image_filenames[idx] for idx in indices[::5]]
_, axes = plt.subplots(math.sqrt(n), math.sqrt(n), figsize=(10, 10))
for match, ax in zip(matches, axes.flatten()):
image = cv2.imread(f"{CFG.image_path}/{match}")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
ax.imshow(image)
ax.axis("off")
plt.show()
让我们来看一些例子!这个模型实际上是在学习图像和文本之间的关系, 那种感觉简直不可思议。
1
2
3
4
5
find_matches(model,
image_embeddings,
query="one dog sitting on the grass",
image_filenames=valid_df['image'].values,
n=9)
现在我们调用这个函数, 结果如下:

当然这不是完美的,因为一些图片中有两只狗,但是考虑到小的训练集和短的训练时间,我认为这很好。
让我们看看其他的输出。查询被写在每个图像的顶部。

它还能计算, 把这个和之前的比较一下。该模型知道“2”的含义,与之前的查询对比, 带来了包含两只狗的图像。


对于下面的例子,模型犯了一些错误,但总的来说,它显然对文本和图像都有很好的理解。

Video
前言
左上这张图片是一个分类器, 对Food101数据集中一张图片的预测结果。 其中预测概率最高的标签是 “a photo of guacamole, a type of food”, 它的预测概率比第二个标签 “a photo of ceviche, a type of food” 高很多。

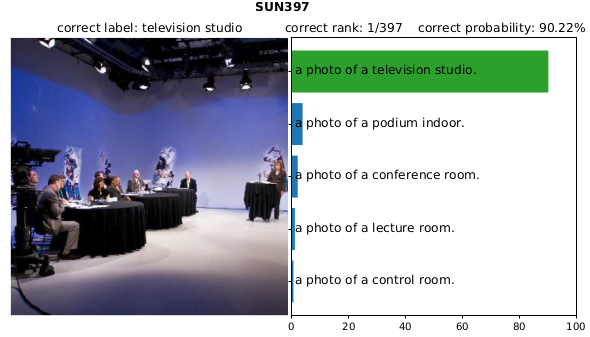
接着看下这个分类器, 对SUN397数据集中一张图片的分类结果, 能正确分类出这是电视演播室。
这里有很多不同数据集上分类的示例, 这是一张飞机的照片, 对于这些图片的分类结果, 只要第一个预测是绿色的那么就是分类正确。而如果第一个是橙色, 那么就是预测了错误的标签, 其中的绿色标签才是正确的标签。 从这些了例子中可以看到, 有些分类器对其中一些样本的分类精度还是不错的, 有些则不太行。
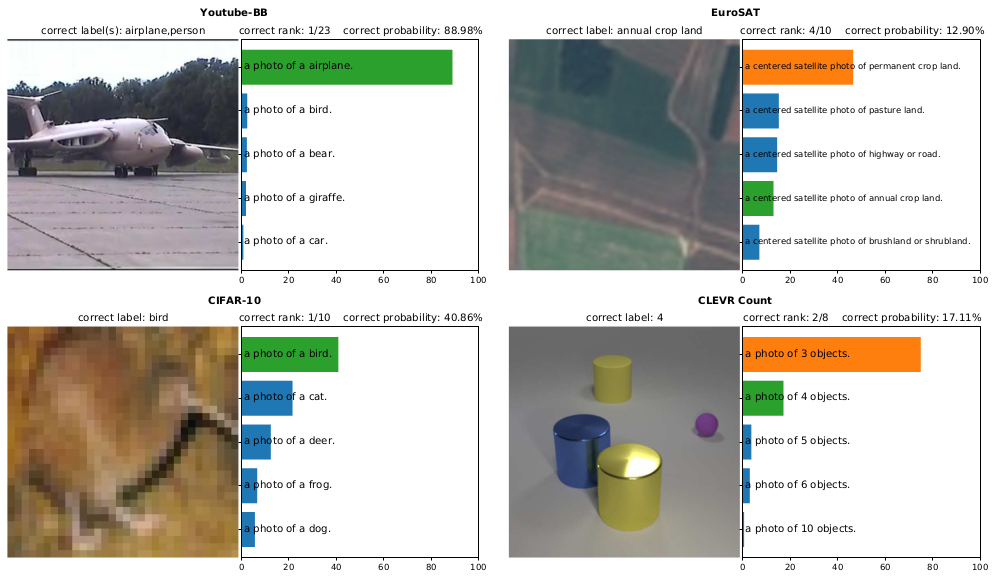
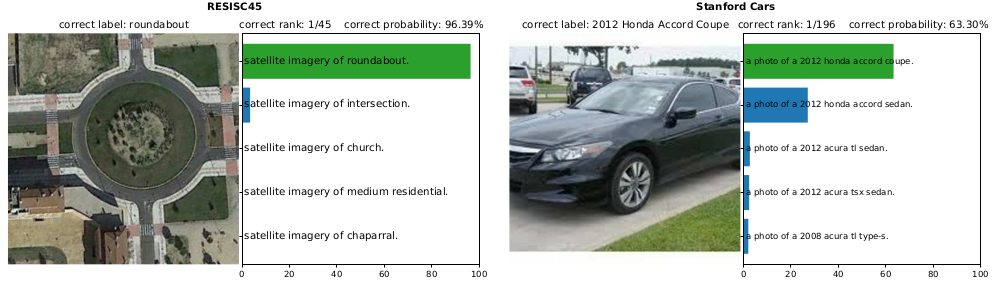
不过这些图片都是来自不同的数据集和任务。比如这是一样卫星图片, 而这是一张车的图片。同时这个任务需要分类这是什么品牌的车, 而不仅仅是分类成一辆车。。
这里包含了各种各样的任务, 而有趣的是这些分类结果都是来自同一个分类器。 这个分类器并没有在这些任务上做微调, 这是一个zero-shot分类器, 能够处理这些所有的不同的测试集。
不过你可能已经注意到了, 这些图片的分类标签和通常的分类器并不一样。比如上面的 Food101 数据集, 这张图片上面显示的原标签是 guacamole。 有趣的地方是, 分类器分类的标签并不只是一个单词, 而是一个句子, “a photo of guacamole, a type of food”, 而这里预测概率第二高的标签是 “a photo of ceviche, a type of food”。
不过句子并不总是 “a photo of xxx”。 对于这张图片, 分类其赋予概率最高的标签是 “a centered satellite photo of permanent crop land”。不过这里正确的标签应该是一下面这个绿色的 “a centered satellite photo of annual crop land”。所以这里展示的事情很有趣,这些分类结果都是来自同一个分类器, 而且并没有在这些数据集上作微调。 这意味着这个分类器并没有在这些数据集上训练, 但是看起来分类的准确性还是不错的, 同时这些标签看起来也有点奇怪。
正文
这个模型是与DALL·E一起放出来的, DALL·E可以根据文字生成图像, 比如把一把由鳄梨制作而成的椅子等等。DALL·E是生成模型, 可以生成图像。 CLIP更像是判别模型, CLIP能以非生成的方式,将图片与文字联系在一起。 接下来我会解释这是什么意思。
这篇文章的想法是把文本和图像结合到一起, 之前已经有许多工作尝试过这个想法。 即使是这篇文章提出的想法, 之前其实也已经有类似的工作了。我觉得这篇文章对于相关工作的介绍, 做得非常地彻底, 同时讨论也很充分, 所以从这可以看出文章的作者对于前人的工作的调研做得非常的细致。
这里的目标是, 得到一个能非常好的表达图片和文字的模型。 那么该如何把文字和图像联系到一起呢?假设我们现在有一个图像和文字结合的数据集, 然后作者构建了一个新的数据集,里面的样本是比如有一张猫的图片, 同时配有一段小文字: “my cute cat”。这类数据集可以在社交媒体上收集, 比如 pinterest 或者 flickr 这类图片分享网站, 用户一般都会给分享的图片配上文字描述。所以从互联网上收集这些不需要标注的图片文字成对的数据应该不难。而这篇文章的动机是, 一般训练一个图片分类模型,通常都是需要把训练样本划分为固定的类别, 比如imagenet 数据集包含有 1000 或者 22000 个类别, 而 mnist 数据集包含有 10 个类别。而如果我们能以某种方式学习把图像和文字联系起来, 那么我们就不会被分类器能预测的标签所限制, 同时也能学到很好的特征表示。所以之前一些工作的思路是, 根据图像预测文字描述。 而DALL·E这个工作则是反过来, 从文字预测图像。重点是如果模型能够根据图片正确地预测文字描述, 我们得到不仅仅是一个能标注图片的模型, 而是更想从这个过程中得到非常好的特征表达器。就是比如一张图片输入一个多层网络, 然后输出文字描述, 比如 “my cat”。那么神经网络的中间层特征表示, 一定可以很好地表达图像中的内容。网络的中间层表示一定是学会了猫这个概念, 不然的话是没办法预测出猫这个词的。因此想法是得到一个很好的特征表达器, 接着基于这个表达在下游任务上作微调。
实验结果表明这个方法非常的有效, 之前已经有文章是关于如何根据给定图像预测文字的了,但是它们的效果都不是很好,那么CLIP是怎么做的呢?我们先来看这张图。首先尝试给定图像预测文字, 该图中的纵坐标是 zero-shot imagenet Accuracy, 接下来我会解释 zero-shot imagenet Accuracy是什么意思。 图中的蓝色线是用 transformer 模型来根据图像预测文字, 是在 Imagenet 数据集上做的验证。橙色的线是用 bag of words 预测的实验结果。bag of words 预测的意思是, 并不需要把句子中每个单词都按顺序预测出来, 只需要预测出词就够了, 乱序也可以。比如给定一张图片, 只要模型能预测出, “cat”, “my”,和 “cute” 这些词语, 即使顺序是错的也算正确。可以看到采用 bag of words 预测的方式, 效率比原来 transformer 模型提升三倍, 同时可以看到虽然蓝线的趋势是同上的, 但是应该是无法赶上橙线的。图中绿线就是文章中提出的CLIP, 可以看到效率又有了很大的提升。接下来解释 zero-shot Accuracy是什么意思,同时为什么简单根据图像预测文字并不是一个好的想法。
假设现在已经有一个可以根据图像预测文字的模型。一般情况下, 这个模型输出的是一些概率。如果这是一个transformer模型, 你可以根据模型的输出计算给定标签的概率。如果有了这么一个模型, 就可以做到文章中提到的想法。
假设现在有一个能够从图中预测文字的模型。你可以把一张图片输入这个模型做编码, 接着询问该模型, 是狗这个词的概率有多大, 是猫这个词的概率有多大, 或者老鼠这个词的概率有多大, 那么就能得到一些概率了。比如对于狗,猫和老鼠的预测概率, 就相当于构建了一个分类器。如果我有一个模型, 能够预测一段文字和图片的关联程度, 那么我就可以询问模型所有与任务有关的可能类别。那么就相当于得到了一个分类器。我们不仅仅只想用猫或者狗作为标签,所以需要生成一些句子, 如果这是一个Imagenet分类器, 那么我就需要放1000个类别在这里, 同时询问模型, 某个标签和图片的关联程度。模型不仅仅可以生成单个词 “dog”, 还可以给出 “a photo of a dog” 或者 “a photo of a cat” 这个句子的可能性。所以这里分类器的结果, 可能会依赖于句子的构成。同样的类别设置, 采用不同的句子构成方式, 会得到不同性能的分类器。假如已经知道输入图片都是照片, 那么句子构成采用 “a photo of xxx” 应该会让分类器的精度更高。因为我们可以通过询问模型, “a photo of a dog” 和 “a photo of a cat” 哪个句子与输入图片的关联更大得到一个更好的分类精度, 所以采用句子的方式比单个词噪声更少。 因为这个模型是用从网络搜集的数据来训练的, 而社交网络上, 人们上传猫的图片, 一般都会打上猫的标签, 或者写上 “a photo of my cat”。这也是为什么, 图中分类器由数据集中的标签进行构造, 但是对应的文本的具体内容却是进过人工修改的。其实就是使得修改标签之后的分类器在该数据集上表现得更好。这就是如何将一个能预测文本的模型转换成一个 zero-shot 的分类器。针对实际任务, 并不需要重新训练这个分类器, 而只需要修改分类器的类别就可以了。
但是如果模型的目标函数仅仅是预测文本还是不够的。接下来将是修改模型架构, 使得 zero-shot 分类器的属性保留的同时, 分类效果能更好, 也就是接下来介绍的CLIP。CLIP不再是预测文本, 那它作了一件什么事情呢?首先将图片经过一个编码器, 得到图片的特征表示, 也就是隐空间中的向量。这里的 $I_1 \thicksim I_N$ 表示一个 batch 图像的特征表示。 接着对于文本数据, 同样有一个文本编码器, 比如这里将一段文本输入编码器, 就会得到一个表示这段文本的向量。同时我们已经知道在同一 batch 中, 第一段文本就对应第一张图片, 第二段文本对应第二张图片, 这是从网上搜集数据的时候就已经知道的。之前的方法是, 根据图像预测文本, 也就是根据图像编码器得到的特征预测文本, 但是CLIP并不这样做, CLIP做的事情就是, 将图片和文本的特征表示做匹配。这就是为什么称它是对比方法的原因。因为对于训练数据, 我们知道文本和图片的对应关系, CLIP的训练方式是, 将图片特征与文本特征做匹配, 也就是要让原本对应的图像和文本距离相近。最后的训练结果是, 要让对应文本和图像特征之间的距离越近越好,不对应的文本和图像特征之间距离越远越好。所以这也是为什么CLIP是对比学习的原因, 矩阵对角线上的就是对应的文本和图像, 其它位置则是不对应的。不过实际上我们并不知道, 其他图像对应的文本描述是否真的和当前图像不一样。但是可以做一个较为安全的假设, 一个 batch 中的样本都是随机采样的, 所以 batch 中其他图片对应的文本都可以看成是随机的, 所以大概率和当前图片样本对应的文本描述对应不上。所以从图中可以看到, 对于每个图像输入在行方向上, 都相当于是一个分类器, 对于文本输入则是列方向上是分类器。图中矩阵的内容就是将文本和图像特征分别做内积, 然后训练的目标就是, 最大化对应的文本和图像特征内积, 同时最小化不对应的文本和图像特征内积。通过将文本和图像特征做内积, 然后分别在行和列方向上计算softmax。所以这是一个对称的分类问题, 从文本和图像里两个不同角度看。可以看到这需要依赖足够大的batch,所以batch越大, 那么对整个数据集的估计也就越准确。 比如图中batch第一句文本 “pepper the aussie pup” 与 第一张图片的距离最近, 那么它应该与数据集中所有其他图片距离都很远。
在推理阶段, 模型用法和训练阶段差不多, 可以同时分别构建图像和文本的分类器, 比如在推理阶段同样有一个文本与图片对的数据集, 那么可以对称地做这个事情。推理阶段, 首先将图片输入编码器得到特征表示, 把该任务的所有标签列出来, 接着对于每个标签都人为地构造一段文本, 接着把所有经过构造之后的文本通过编码器得到特征表达,接着将所有文本特征与输入特征作内积, 而内积分数最高的, 所对应的标签就是图像分类的结果。 这就是在推理阶段预测图像标签的方式, 对于实际任务, 不需要重新训练。推理阶段的数据集与训练阶段可以是完全不同的, 所以CLIP提出的思路真的非常有趣。
现在网上有一些帖子, 有人用这个思路去引导 StyleGAN 来根据一段描述生成图片。这个思路的可能性是非常大的。 这就是CLIP这个模型的总体架构, 编码图像和文本特征, 然后还有这个对比目标函数。所以可以想到CLIP这个架构所提取的特征可能会比在ImageNet上预训练的模型所提取的特征要好。因为如果你在imagenet分类任务上预训练模型, 模型其实会简单的把所有关于狗的概念都聚集到一起。如果这是分类任务, 模型会倾向于把所有狗的概念都聚集在一起, 因为不需要区分不同的狗。模型会把不同狗的概念都聚集在一起, 而忘记了它们其实是不同的。同时模型也会忘记所有与分类无关的内容。而这里, 随着模型的能力越来越好, 它能识别更多的文本内容。比如一开始模型还很弱, 它只会关注与 “pup” 这个词,相当于就是一个狗的分类器。 随着训练的进行, 模型开始能识别 “aussie pup” 这个词了, 那么其实就能和其它狗区分开了。甚至模型最终能学会这只狗的真名等等,可以看到随着模型的能力越强, 它能学会数据集中更多的细微差别。 文章的作者在很多任务上测试了CLIP。
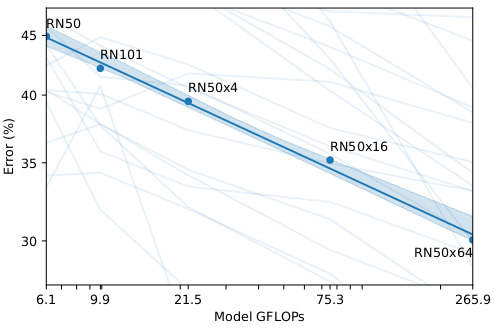
对于图像编码部分, 采用了不同类型的编码器。文本编码器部分则是一个transformer, 且模型并不大。 然后是取文本最后一个词对应的输出的特征作为文本的编码特征。对于图像编码器, 文章作者测试了resnet的多个变体, 也测试了最近很火的 visual transformer的多个变体。 同一个模型通过改变计算量和模型大小来得到不同的变种。文章中还对文本作了ensemble, 我们知道通过构造更好的文本可以获得性能上的提升。而这里的ensemble就是指通过构造不同的文本, 然后综合这些文本特征和图像特征。 从这个图中可以看到, 这样能带来性能的提升。
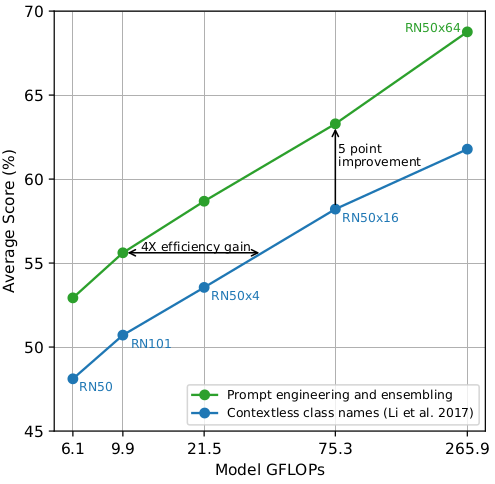
RN50x4, RN50x16, 和 RN50x64 是 ResNet-50 使用 EfficientNet-style 的模型 scaling 以及 使用 ResNet-50 大约 4x,16x,和 64x 的计算量。
这里竖线对应点的是同一个模型, 所以计算量是一样的。这是其中能做的一件有趣的事情, 而我认为对于文本构造是更相关的。
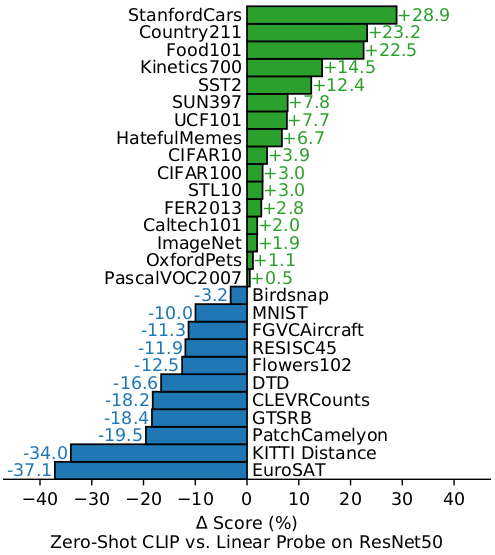
这个图是 zero-shot CLIP 和 resnet50 有监督训练的baseline模型在16个数据集上的性能对比。这个baseline模型并不是最好的。 在这16个数据集上, resnet50 骨干参数固定用于提取特征, 只训练网络最后一层分类器。resnet50是一个常用的骨干网络, 不过这里对比并不是用性能最好的版本。这个resnet50骨干是在imagenet上作预训练, 网络最后一层是1000类全连接层。接着基于这个特征提取骨干网络, 再在新任务上训练一个简单的线性分类器, 这就是Linear probe。Linear probing也可以在中间做, 不过这里表示从网络第二层开始到最后一层分类器之前。所以假设前面红色这段是一个很好的特征表示函数, 在新任务上训练的时候保持参数不变, 只在最后加一层线性分类器。而fine-tuning是整个网络都放开训练, 不过论文中的大部分实验都是选择linear probing, 因为这可以更好地说明骨干网络的特征表示能力。 在这16个数据集对比实验中, 包括了imagenet数据集。 由于这个resnet50骨干网络是在imagenet上预训练的, 所以按道理应该会在imagenet上表现地不错。而且应该能和在imagenet上预训练的性能相同, 这个图就是CLIP和基于resnet50座linear prob的对比。CLIP并没有在这些数据集上做finetune, 可以看到在很多数据集上都超过了resnet50, 而resnet50是在这里数据集上作了linear prob的。zero-shot也就是不需要训练, 虽然说CLIP的预训练数据非常大。这和GPT-3很像, 只需要在一个非常大的数据集上预训练一次, 然后就可以做很多下游任务。这里对比结果可以看到CLIP在imagenet数据集上表现比resnet50还要好。不过resnet50在不少任务上还是表现的比CLIP要好。而在STL10数据集上, CLIP取得了目前最好的结果, 比之前所有有监督的性能都要好。原因是这个STL10数据集, 每一类的样本都很少。所以有监督的迁移学习还是挺难的。所以zero-shot CLIP在哪些包含与网上图片相似的数据集上表现的就会很好。同时有标注样本又很少的话, 那么CLIP就是一个很好的应用。不过在更专业的数据及上, 比如肿瘤分类或卫星图像等等, CLIP的表现就不太好了。可能的原因是, 因为这类图片加文字描述的数据很难在网上找到。 非常有趣的地方是,CLIP在MNIST这个很简单的数据及上表现地也比resnet50要差。 文章分析了下这些不同的数据集, 把CLIP与resnet50和visual n-grams都作了对比。

然后我发现这一段很有趣, 大多数图像分类数据集类别的命名方式让基于自然语言的 zero-shot 迁移学习成为可能。 绝大多数的数据集, 标注图片的方式都是给一个数字id然后会有一个文件, 是数字id到类别英文名字的映射。而有些数据集, 比如Flowers102或者GTSRB(德国街道路标)并没有提供类别数字id到英文名字的映射, 也就没办法进行 zero-shot 迁移学习。 所以文章的作者在做实验的时候, 必须要自己去标注这些没有数字id到英文名字映射的数据集。 比如这个街道路标数据集分类标注信息是只有这张图片是路标类型1, 这是路标类型2。 Alec在这个项目完结的时候,学到了很多关于花的物种和德国交通标志相关的知识。 这篇文章的幽默风格我挺喜欢的, 所以我做了这个表情包。右上角的这个标志是说, 卡车禁止装载超过 3.5 吨的重量?我想知道CLIP这个模型在这个表情包上的表现如何。

下面这个图表是 CLIP 与 few-shot linear probes 方法的对比,在这里可以看到, zero-shot CLIP的性能超过了很多 few-shot learning的模型性能, 当每一类提供的标注样本很少的情况下。当没类有标注样本是16个的时候, CLIP和最新公开的性能最好的BiT-M的性能是差不多的。所以zero-shot CLIP的性能还是很强的。而如果基于CLIP去做Linear prob, 那么性能会远超 BiT-M。 有趣的地方是, CLIP在做linear probe的时候, 性能是先下降, 然后随着有标注样本增加再重新提升。 这其实挺直观的, 因为CLIP的 zero-shot 分类器与一般的有监督线性分类器不同。zero-shit CLIP其实是相当于已经训好了最后一层的分类器。而在做linear probing的时候, 需要扔掉文本编码器部分, 接着在图像编码器之后加一层线性分类器。所以分类方式不再是看图像特征与文本特征最相近, 而是重新训练一个线性分类器。而因为新加的一层线性分类器是随机初始化的, 所以没类一个有标注样本是不够的。 所以这也是为什么一开始性能会变差, 然后当没类有标注样本有4个的时候会超过其他模型。
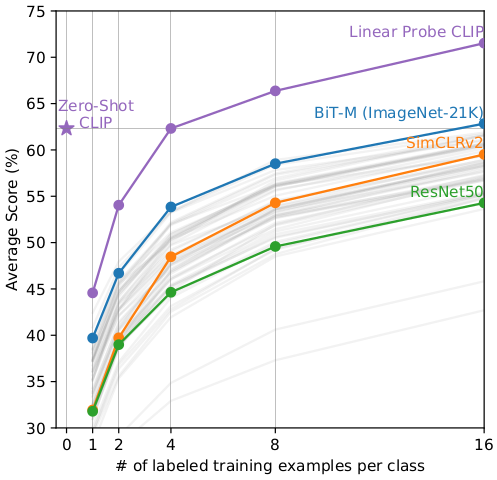
文章中也对不同数据集做了实验, linear probing CLIP 每类需要多少有标注样本才能达到 zero-shot CLIP 的性能。所以我感觉这个有点变成了研究网络上什么类型的图片最多。
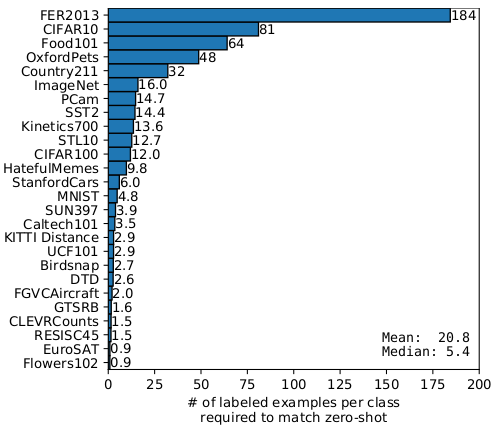
在机器学习中, 随着训练数据和模型计算量的增加, 误差会同步下降。 从这个图上可以很清晰的看到这个趋势, 加粗的蓝线上是 图像编码器使用 resnet 的系列模型。 Zero-shot CLIP 的性能和模型大小呈一个正比关系。 这个加粗的蓝线是平均了很多任务上的结果。 图上浅色的线就是在其他任务上的结果, 可以看到噪声挺多。导致噪声的原因可能有, 数据集的构成, 文本编码器部分, 输入文本的句型构造方式等等。
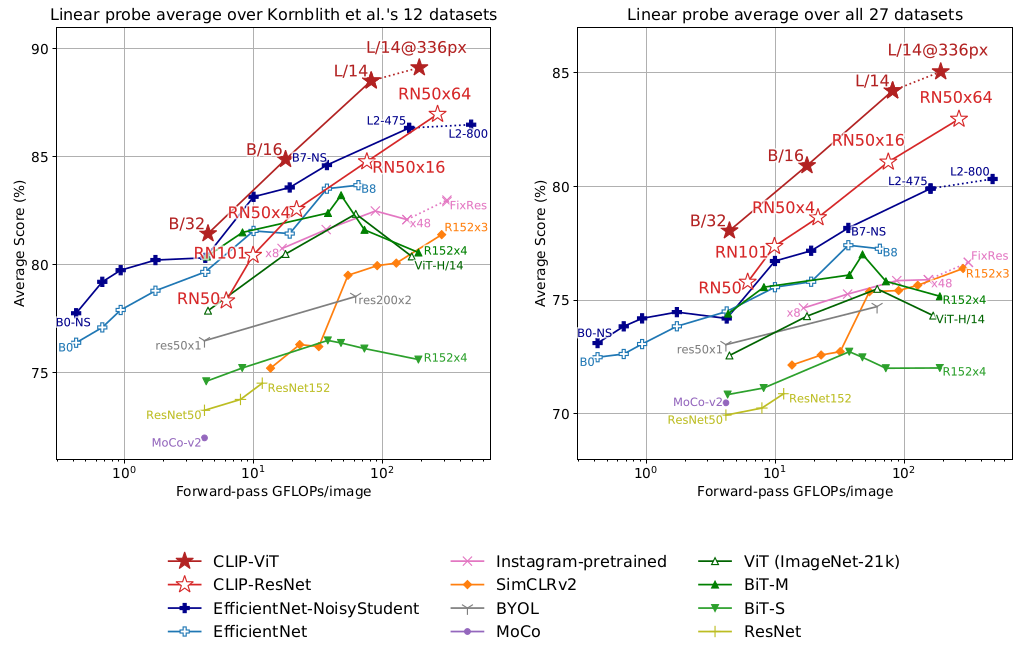
这里的实验结果是 linear probe CLIP 和 最新的视觉模型做对比, 可以看到CLIP性能是最好的。这里的数据是在12个数据集上的实验结果, 这12个数据集和imagenet是类似的。而右边这个图表是更多数据集上的平均结果, CLIP的性能会更好, 当然数据集的选择会有一些选择偏见。最上面的红色的线就是CLIP。
所以这看起来是一个挺大的进步, 普通用户可以基于CLIP构建自己的分类器。 现在我基于CLIP可以很方便地构建我想要的分类器。文章中也对CLIP的鲁棒性作了一些实验。 之前的模型都是在imagenet上训练过的。同时大家也发现当把这些在imagenet上预训练的模型直接在其他数据集上测试的时候, 性能就会下降非常多。比如这里的ImagenetV2就是从Imagenet数据集中筛选出新的数据集, 使得新的数据集更接近原来的测试集。 而这些在Imagenet上预训练的模型在这个Imagenet V2上的测试性能都下降了不少。然后作者们还构造了更难的数据集, 比如imagenet sketch的都是素描的图片, 还是 Imagenet-A包含很多对抗样本。 这看起来非常困难, 但是对于人类来说还是能识别的。仔细观察这些数据集图片, 其实其类别和imagenet数据集一样, 所以一个在imagenet上训练的模型,应该是能够分类这些图片的。这里对比的是 resnet101 和 zero-shot CLIP。 顺便说一句, 我觉得这是一个很大的进步, 即使resnet101并不是目前最好的模型,但是也是在imagenet上训练过的, 而CLIP是没有在imagenet上finetune过的, 直接在imagenet上测试的精度就能和resnet101一样。而且从实验结果可以看到, 随着数据集的难度增加, resnet101的分类精度一致在下降。而zero-shot CLIP 并没有随着数据集难度的增大而有性能下降很多的情况, 所以CLIP的鲁棒性更加的好。而这个resnet101训练的目的只是为了区分imagenet中的不同类别。 所以它只需要学会区分不同类的实例就够了, 置于同类别内的差别不需要学习。 这就会导致这个分类器严重退化, 而无法识别一个香蕉的素描图, 它只能识别黄色的香蕉。
