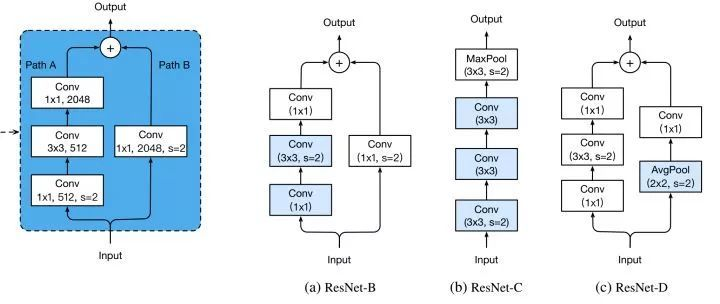
ResNet A、B、C、D
改进downsample部分,减少信息流失。
每个stage的第一个conv都有下采样的步骤,我们看左边第一张图左侧的通路,input数据进入后在会经历一个stride=2的1*1卷积,将特征图尺寸减小为原先的一半,请注意1x1卷积和stride=2会导致输入特征图3/4的信息不被利用,因此ResNet-B的改进就是就是将下采样移到后面的3x3卷积里面去做,避免了信息的大量流失。
ResNet-D则是在ResNet-B的基础上将identity部分的下采样交给avgpool去做,避免出现1x1卷积和stride同时出现造成信息流失。
ResNet-C则是另一种思路,将ResNet输入部分的7x7大卷积核换成3个3x3卷积核,可以有效减小计算量,这种做法最早出现在Inception-v2中。
ResNet V2
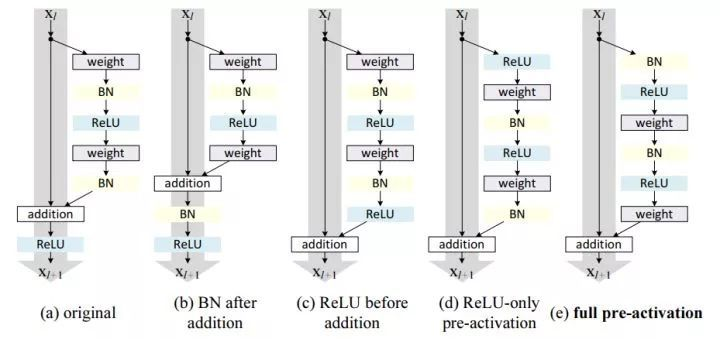
原始的resnet是上图中的a的模式,我们可以看到相加后需要进入ReLU做一个非线性激活,这里一个改进就是砍掉了这个非线性激活,不难理解,如果将ReLU放在原先的位置,那么残差块输出永远是非负的,这制约了模型的表达能力,因此我们需要做一些调整,我们将这个ReLU移入了残差块内部,也就是图e的模式。
论文:https://arxiv.org/abs/1603.05027
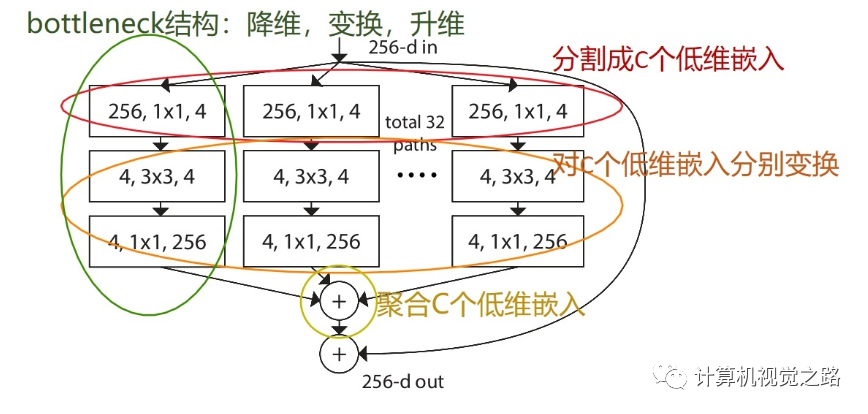
ResNeXt
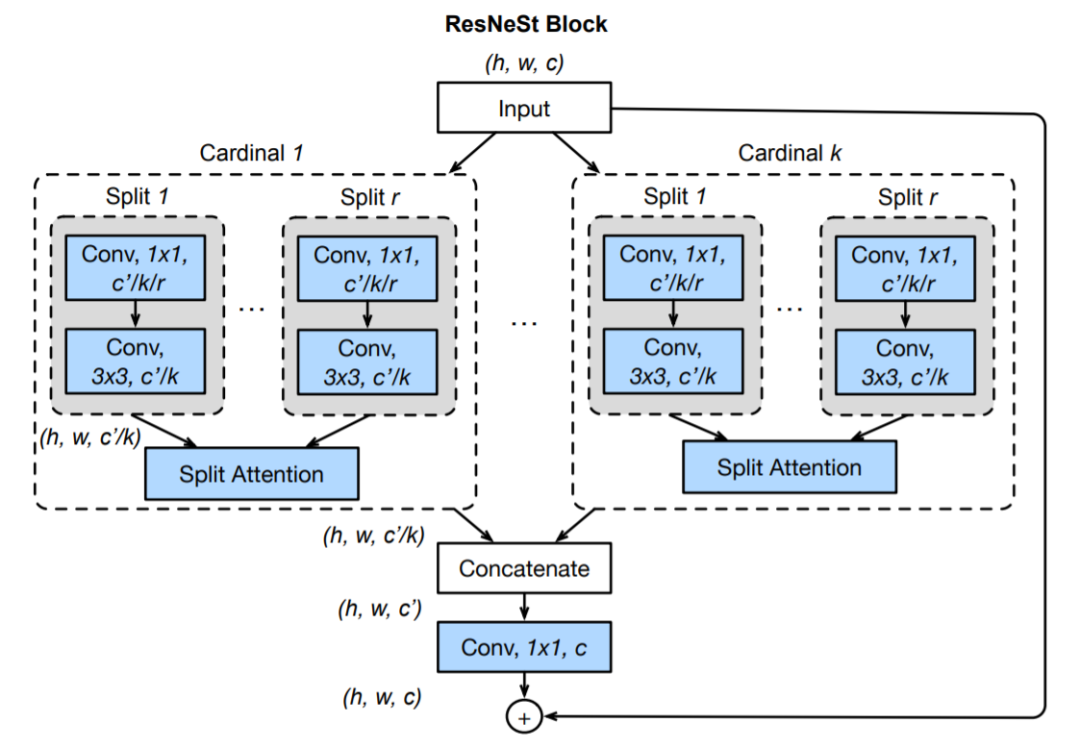
ResNeXt是FAIR的大神们(恺明、Ross、Piotr等)对ResNet的改进。其关键核心模块如下所示。尽管ResNeSt与ResNeXt比较类似,不过两者在特征融合方面存在明显的差异:ResNeXt采用一贯的Add方式,而ResNeSt则采用的Cat方式。这是从Cardinal角度来看,两者的区别所在。这点区别也导致了两种方式在计算量的差异所在。其中,inception block人工设计痕迹比较严重,因此引入参数K,直接将子模型均分,有K个bottleneck组成。如下图所示。
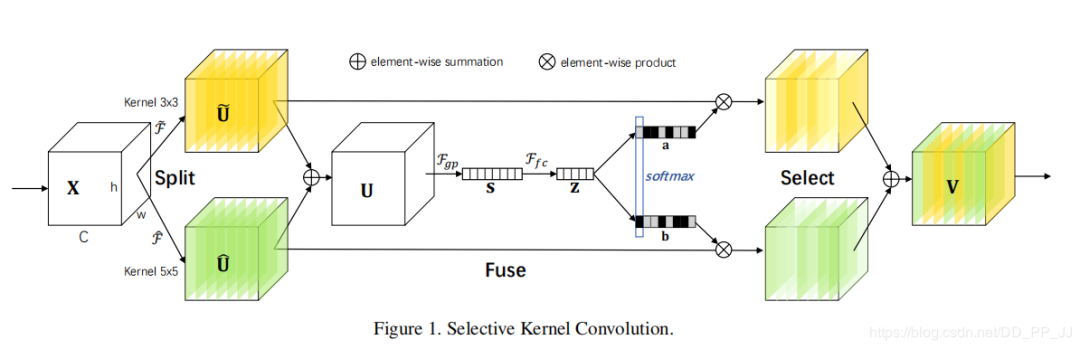
Selective Kernel Networks(SKNet)
SKNet提出了一种机制,即卷积核的重要性,即不同的图像能够得到具有不同重要性的卷积核。SKNet对不同图像使用的卷积核权重不同,即一种针对不同尺度的图像动态生成卷积核。
论文地址:https://arxiv.org/abs/1903.06586
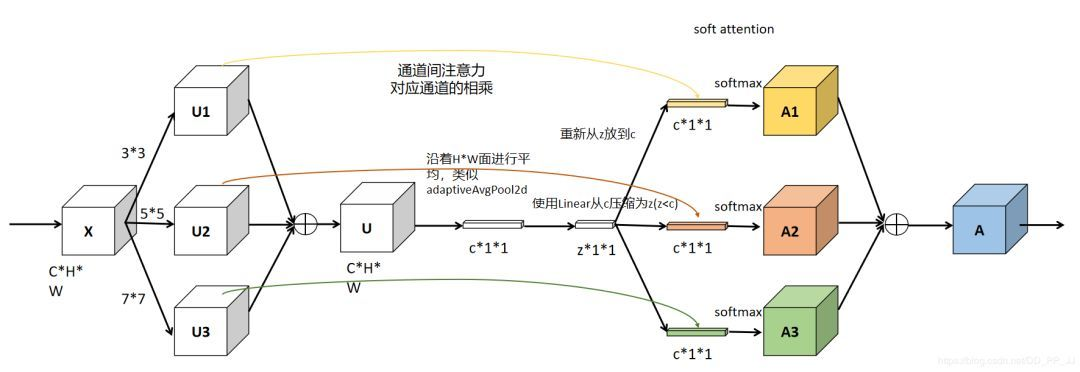
ResNeSt
ResNeSt 提出了一种模块化 Split-Attention 块,可以将注意力分散到若干特征图组中。按照 ResNet 的风格堆叠这些 Split-Attention 块,研究者得到了一个 ResNet 的新变体,称为 ResNeSt。它保留了整体的 ResNet 结构,可直接用于下游任务,但没有增加额外的计算量。主要是基于 SENet,SKNet 和 ResNeXt,把 attention 做到 group level。
论文地址: https://hangzhang.org/files/resnest.pdf
Split-Attention 块
Split-Attention 块是一个由特征图组和 split attention 运算组成的计算单元,下图展示了 Split-Attention 块的整体思路:
特征图组(Feature-map Group)
与 ResNeXt 块一样,输入的特征图可以根据通道维数被分为几组,特征图组的数量由一个基数超参数 K 给出,得到的特征图组被称为基数组(cardinal group)。研究者引入了一个新的底数超参数 R,该参数规定了基数组的 split 数量。