The Hateful Memes Challenge
Winner Presentation #1(Enhance Multimodal Transformer With External Label And In-Domain Pretrain)
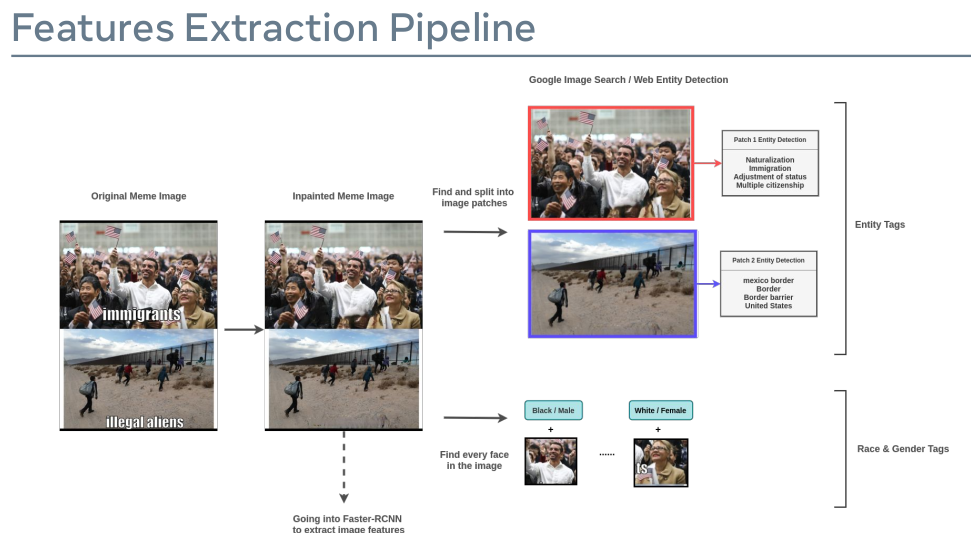
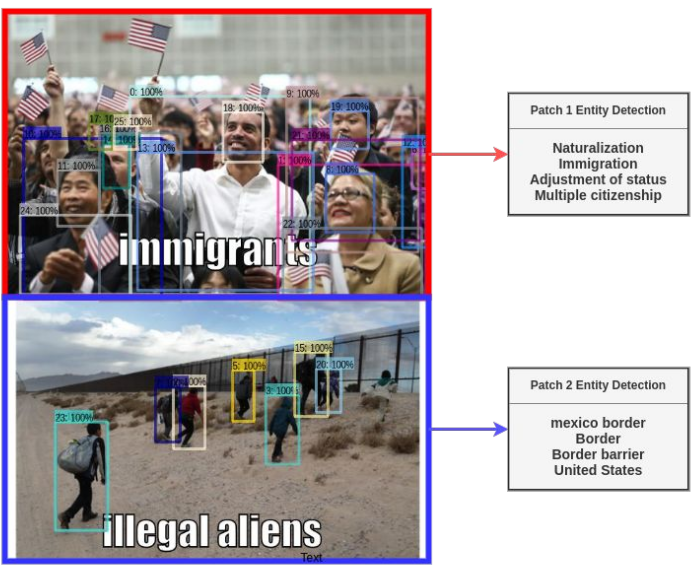
首先我们使用 EasyOCR 定位每个 meme 的文本 并且 使用 DeepFillV2 inpainting model 移除它们。图像将会送入自定义的 Faster-RCNN detector 来决定决定 meme 是否由多个图像 patch 组成。如果是的话, 在进入 web entity detection 步骤之前 将 图像分成多个样本。 真实情况 entity detection 的结果并不像图中展示的这样干净。 它们是有噪声的 并且 在使用为训练数据之前需要一些后处理。
这些 inpainted meme image 也会应用于 FairFace gender/race classification 和 典型的 自下而上的图像特征提取。

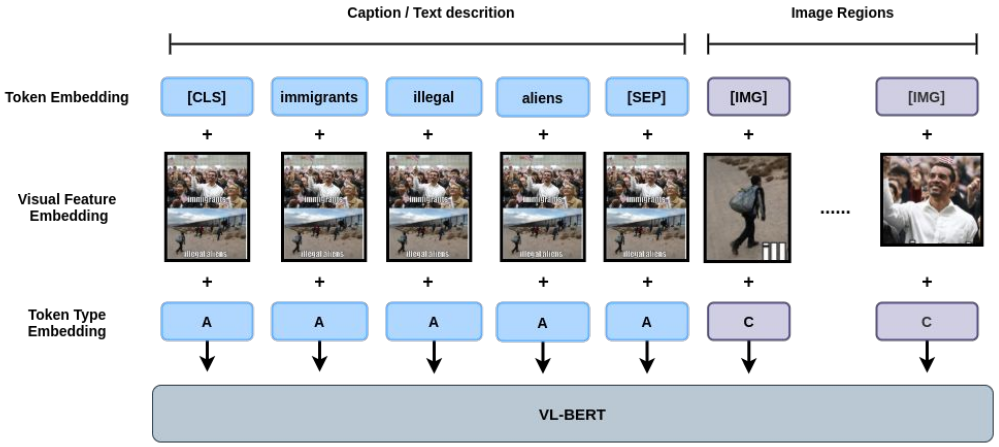
基于 VL-BERT 的 hateful memes detector 的原始实现:
- No visual grounding for text modality
- Ignore many data characteristic specific to the meme
这次比赛我们的第一次尝试是,以最小更改将 VL-BERT 的原始实现应用在 在 hateful meme classification上。在 VL-BERT 版本中, 所有的文本 tokens 从每张图像的区域的平均特征 中 采样 图像特征嵌入。
尽管它很简单,在前半段比赛中, 通过融合 8 个 VL-BERT Large 模型 在第一阶段排行榜中取得前10名。
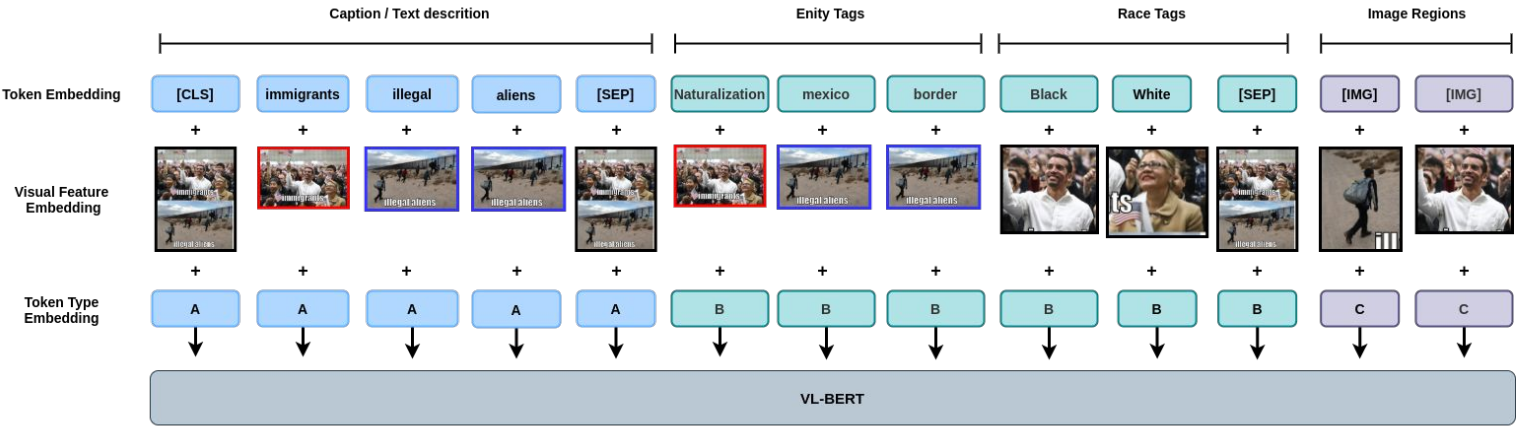
我们在这里:
- 使用 visual feature 创建 text 与 part of the image 之间的联系
- 使用 visual feature 创建 text description 和 entity/race tags 之间的隐式联系
- 使用 visual feature 创建 entity/race tags 与 对应的 image region 之间的联系
由于 meme 的各种独特的特定 和 真实世界所需的只是, 我们拓展 VL-BERT 的 VL embedding 框架 以创建 text, image regions, 以及 前面提到的特征提取步骤得到的额外知识 之间的联系。
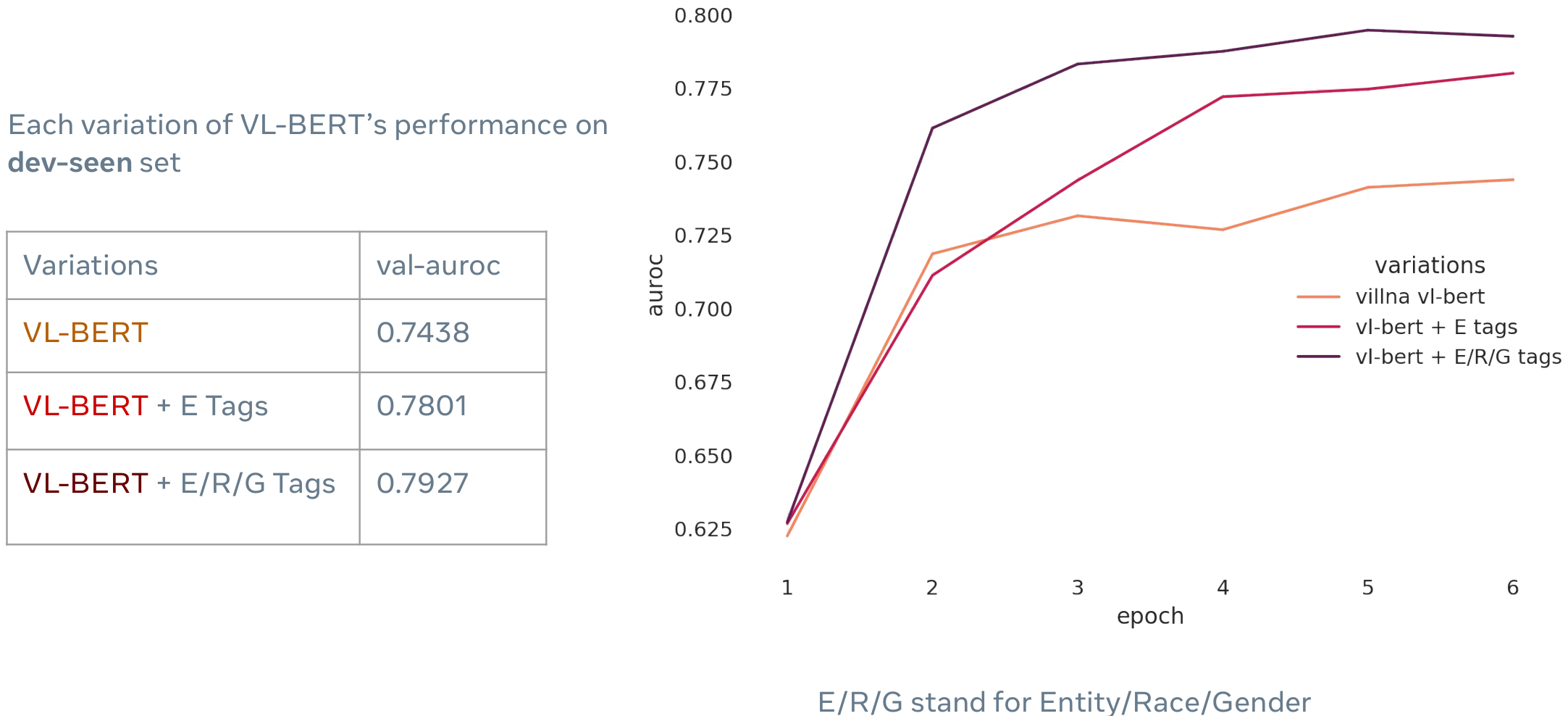
在向VL-BERT提供更多信息后, Val-set 分数得到一个很大的提升。下面的环丁片多不同的 VL embedding 框架有一个有趣的比较。
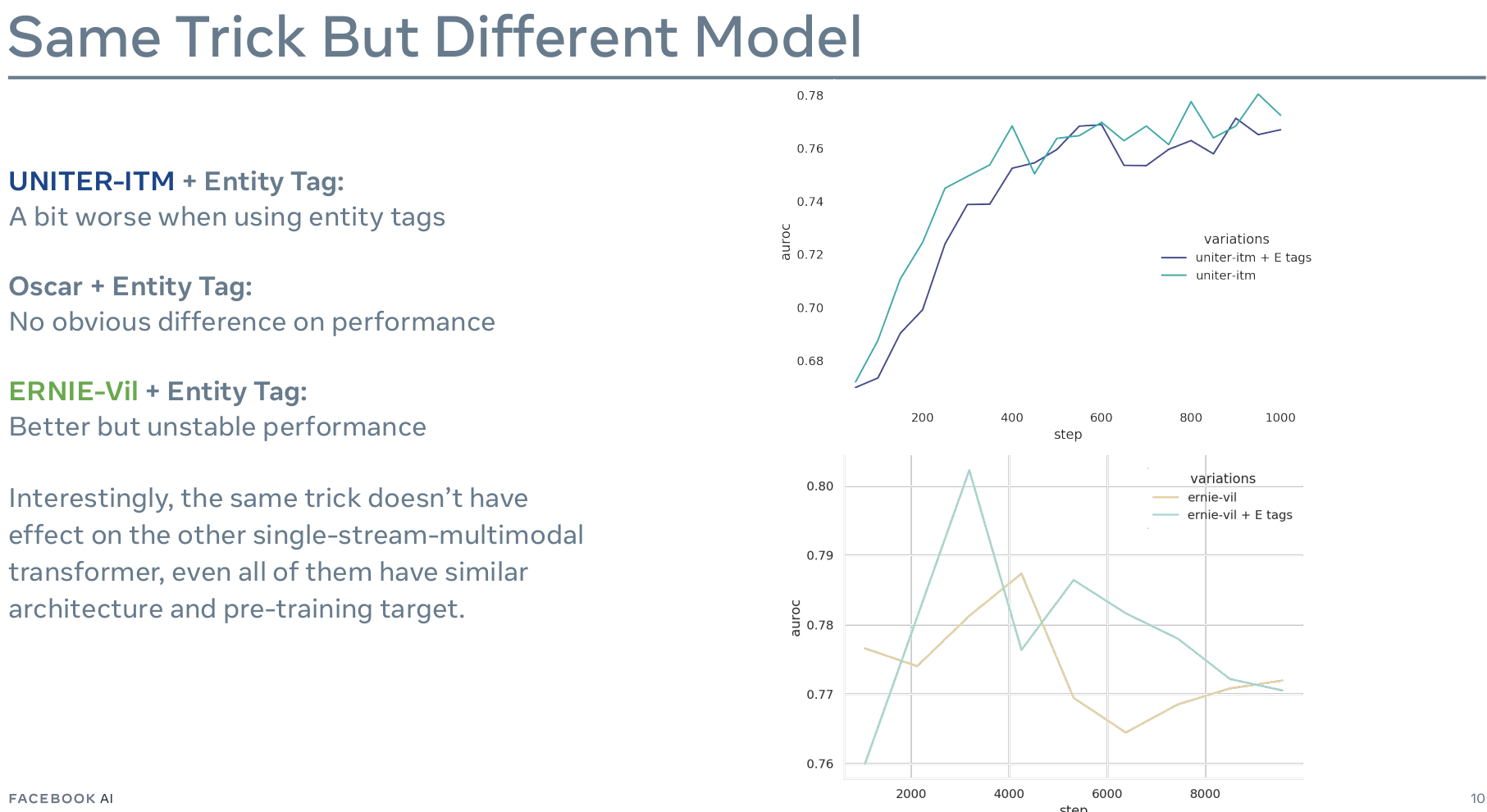
单流模型的IMO 可能由以下原因导致:
- 仅预训练缺乏语言上的训练
- visual feature embeding 框架的不同
- 缺乏显式的visual-linguistic融合机制 使得在小数据集上难以学习如何利用新的输入类型(VL-BERT对于每个token的visual embedding, ERNIE-Vil的 跨模态层)
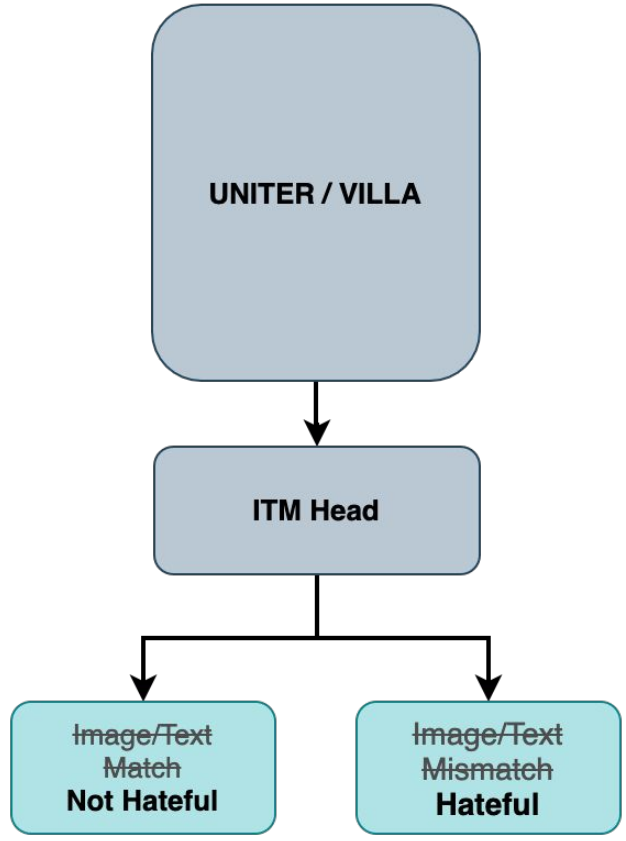
就像很多参赛选手注意的一样, 当图像和文本描述对齐之后, meme 可能是 non-hateful的。 但是在相反的情况下, meme不一定是 hateful 的。
尽管我们可能不能直接将 ITM head 应用于 hateful meme classification, 我们可以尝试在一个 hateful memes 的特定类型使用 ITM 作为一个代理任务提升模型的表现。
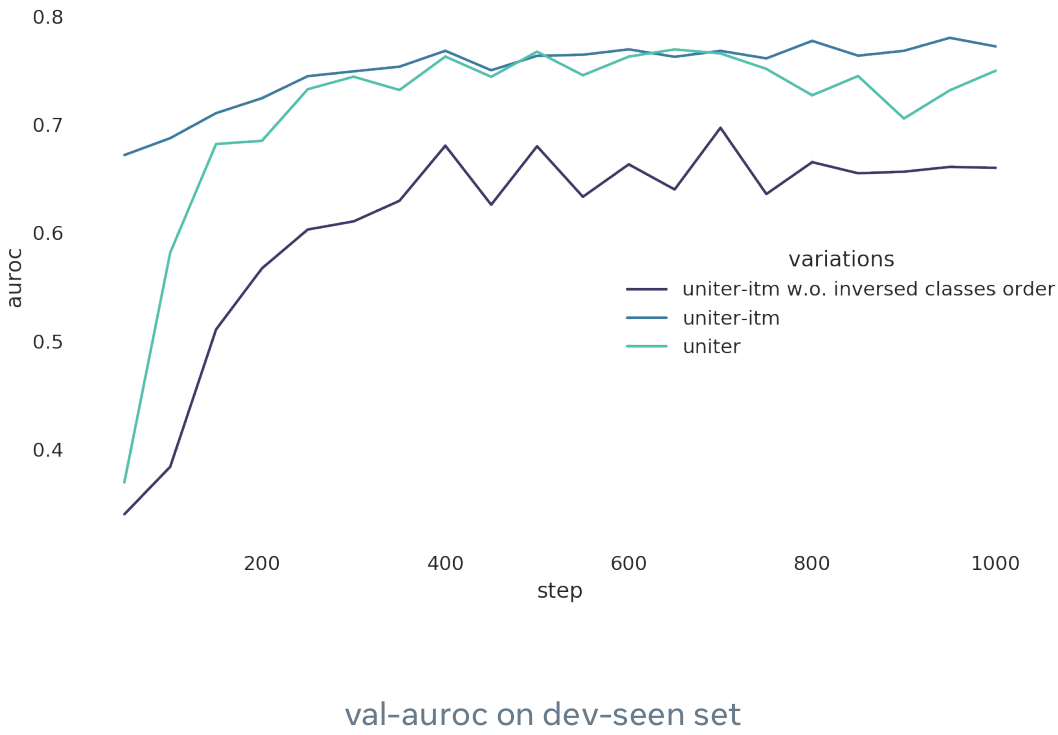
UNITER-ITM 相较于 随机初始化 classification head:
- 看起来在小数据集上不那么容易过拟合
- 得到了更好一点的表现(0.778 vs 0.765 AUROC)
- 得益于 ITM 和 WRA 预训练任务需要两种模态, 在文本模态上有更小的偏差
一些有趣的现象:
- UNITER-ITM 在训练的 50 个steps / 0.7 个epoch 取得了很高的准确率
- 如果我们在hateful memes 上 fine-tune之前不作 itm head classes 的反转, 性能会显著下降
我认为 UNITER-ITM 在开始训练时的高准确度也表明了 ITM pre-train task 和 hateful memes classification 的联系。

Phase2 Submission [1]: 2 x extended VL-BERTPhase2 Submission [2]: 3 x extended VL-BERT + 2 x UNITER-ITM + 2 x VILLA-ITMPhase2 Submission [3]: 3 x extended VL-BERT + 2 x UNITER-ITM + 2 x VILLA-ITM + 2 x ENIRE-Vil
综述
数据集
Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning
这篇文章提出了一个新的数据集 Conceptual Caption
Preparing a collection of radiology examinations for distribution and retrieval
这篇文章提出了一个放射学图像和放射学家对该图像描述的数据集。
Paper
Deep Visual-Semantic Alignments for Generating Image Descriptions(Karpathy splits)
大部分人使用 ms coco 数据集的 Karpathy splits
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
这篇描述了一种提取视觉特征的方法
Self-critical Sequence Training for Image Captioning
这篇文章提出了一种叫做SCST的强化学习训练方法。
Discriminability objective for training descriptive captions
它使用了一个跨模态检索模型作为判别损失。还是用了 CIDEr 等 metric 作为优化条件。
Attention on Attention for Image Captioning
提出了一种AoA的块用于拓展传统注意力机制决定results 和 queries之间的相关性
Meshed-Memory Transformer for Image Captioning
VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning
Image Captioning with Very Scarce Supervised Data: Adversarial Semi-Supervised Learning Approach
用CycleGAN做ImageCaption, 与我idea相撞。
绪论材料
视觉-语义模式匹配
当代基于深度神经网络的视觉模型已经取得了极大的成功。但许多实验都表明,常规视觉模型通常以感知的形式实现各类视觉任务,如检测、分割、识别等等。一旦这些任务中涉及抽象的语义,视觉模型通常会受到困扰,并且容易发生过拟合。一种可能的方式是通过自然语言描述与视觉信息的模式匹配,使得视觉模型可以区分不同语义的信息,完成更高鲁棒性的特征提取过程,并且可以利用这一点直接支持下游各类任务。比如,在仓储、物流等场景中,模型可以直接根据“卸货车辆后方未着工作服的行人”这类概念提示潜在货物风险或行人危险;在商业文档识别等场景中,模型可以根据“价格栏下方的数字”作为潜在的物品价格等等可能。
图像字幕生成
给图像提供除了标签(tag)以外更加丰富的描述是十分有意义的,那么机器是否可以帮助有视觉障碍的人来理解图像,是否可以将一幅图生动地讲给听众呢?这一任务不仅要能检测出图像中的物体,而且要理解物体之间的相互关系,最后还要用合理的、自然的语言表达出来。
SPICE 计算方法
\[P(c, S) = \frac{\mid T(G(c)) \otimes T(G(S))}{\mid T(G(c))\mid}\] \[R(c, S) = \frac{\mid T(G(c)) \otimes T(G(s))}{\mid T(G(s)) \mid}\] \[SPICE(c, S) = F_1(c, S)=\frac{2 · P(c, S) · R(c, S)}{p(c, S) + R(c, S)}\]c表示候选标题,S表示参考标题集合, G(·) 表示利用某种方法将一段文本 成一个场景图(Scene Graph), T(·)表示将一个场景图转换成一系列元组(tuple)的集合, ⊗运算为非严格匹配。
实验结果
CLIP 的图像编码器在图像描述生成阶段不进行训练:
| Dataset | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METOR | ROUGE | CIDEr | SPICE |
|---|---|---|---|---|---|---|---|---|
| COCO-EN | 66.4 | 24.5 | 22.8 | 49.4 | 78.3 | 15.3 |
CLIP 的图像编码器在图像描述生成阶段也进行训练:
| Dataset | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METOR | ROUGE | CIDEr | SPICE |
|---|---|---|---|---|---|---|---|---|
| COCO-EN | 68.1 | 25.5 | 23.5 | 50.0 | 82.7 | 16.4 | ||
| AIC test_a(character-level) | 80.0 | 71.3 | 63.9 | 57.0 | 36.9 | 66.7 | 176.1 | |
| AIC test_a(word-level) | 75.4 | 63.2 | 52.9 | 44.3 | 36.9 | 62.6 | 132.0 | |
| AIC test_b(character-level) | ||||||||
| AIC test_b(word-level) | 75.3 | 63.0 | 52.6 | 44.0 | 36.9 | 62.5 | 130.9 | |
| Flickr8kCN | 45.6 | 26.2 | 15.4 | 9.3 | 22.9 | 33.2 | 17.1 | 2.1 |
| Flickr30kCN | 44.4 | 23.1 | 12.0 | 6.4 | 21.1 | 31.6 | 15.4 | 1.7 |
实验现象
使用 timm 预训练的 ViT 为图像编码器, CLIP收敛, 有效
使用 timm 无预训练的 ViT 为图像编码器, CLIP不收敛, 无效
使用自己的 ViT 为图像编码器, CLIP 收敛, 无效
使用 OpenAI 的 ViT 为图像编码器, CLIP 收敛, 无效
算法性能
训练及推理的线上环境为 双卡3090, 1卡占用显存 18559MiB, 2卡占用 17661 MiB
平均每张图片推理时间为 187.4ms