在第9.7节中,我们一个 token 一个 token 地预测输出序列,直到预测到特殊的序列结束符 <eos> token。在本节中,我们将开始形式化这种贪婪搜索策略,并探讨它的问题,然后将此策略与其他替代策略 (exhaustive search 和 beam search) 进行比较。
在正式介绍贪婪搜索之前,我们使用9.7节中的相同数学符号来形式化搜索问题。在任意时间步 $t’$, 解码器输出 $y_{t’}$ 的以时间步 $t’$ 之前的的输出子序列 $y_1, …, y_{t’-1}$ 和编码了输入序列信息的上下文变量 $c$ 。 为了量化计算成本, 表示$\mathcal{Y}$(它包含 “<eos>“)为 输出词典。 因此这个词典集合的基数 $\mid \mathcal{Y} \mid$ 为词典大小。 让我们制定输出序列的最大token数量为 $T’$。 我们的目标是从所有的 $O(\mid Y \mid)^{T’}$ 的可能输出序列中搜索理想的输出。 当然所有这些输出序列, 在实际输出"<eos>"之后的部分会被丢弃。
Greedy Search
首先让我们来看一下简单的策略: greedy seach。 这个策略被用来预测 9.7 节的序列。 在贪婪搜索中, 在输出序列的任意时间步 $t’$, 我们从 $\mid \mathcal{Y} \mid$ 中搜索条件概率最高的token。
\[y_{t'} = \mathop{argmax}_{y \in \mid \mathcal{Y} \mid} P(y \mid y_1, ..., y_{t' - 1}, c)\]一旦 "<eos>" 输出 或者 输出序列达到最大长度 $T’$, 输出序列完成。
那么贪婪搜索会犯什么样的错误? 事实上,最优序列应该是最大化 $\prod_{t’ = 1}^{T’} P(y_{t’} \mid y_1, …, y_{t’-1}, c)$的输出序列, 这是一个基于输入序列生成一个输出序列的条件概率。 不幸的是, 通过贪婪搜索并不能保证得到最优序列。
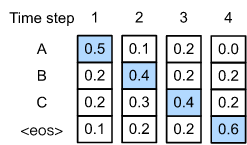
在每个时间步, 贪婪搜索选择最高条件概率的token。
假设在输出字典中有四个 tokens "A", "B", "C" 和 "<eos>"。上图中, 每个时间步的四个数字表示分别在每个时间步生成 "A", "B", "C" 和 "<eos>" 的条件概率。
在每个时间步, 贪婪搜索选择最高的条件概率。 因此, 输出序列 "A", "B", "C" 和 "<eos>" 如上图所预测。 输出序列的条件概率是 $0.5 \times 0.4 \times 0.4 \times 0.6 = 0.048$。

如果我们在时间步2选择 token "C", 它是第二高的条件概率。 载音输出子序列在时间步1和2, 时间步3基于前两个时间步, 将 “A” 和 “B” 改变为 “A” 和 “C”, 在时间步3的每个 token 的条件概率也会发生改变。假设我们在时间步3选择 “B”。 那么时间步4的token选择也会发生改变。结果输出序列 "A", "C", "B" 和 "<eos>" 的条件概率为 $0.5 \times 0.3 \times 0.6 \times 0.6 = 0.054$。 在这个例子中, 贪婪搜索 "A", "B", "C" 和 "<eos>" 的输出序列不是最优序列。
Exhaustive Search
尽管我们使用 Exhaustive Search 可以得到最优序列, 但是它的计算成本是 $O(\mid \mathcal{Y} \mid^{T’})$。 而贪婪搜索的计算复杂度为 $O(\mid \mathcal{Y} \mid T’)$ 。 比如当 $\mid \mathcal{Y} \mid = 10000$ 和 $T’ = 10$, 我们仅需要评估 $10000 \times 10 = 10^5$个序列, 而Exhaustive Search需要 $10000^10 = 10^{40}$ 个序列。
Beam Search
Beam Search 是贪婪搜索的一种改进。 它有一个叫做 beam size $k$ 的超参数。 在时间步1, 我们选择有最高条件概率的 $k$ 个tokens。 每个 token 都会分别作为$k$个候选输出的第一个 token。 在接下来的每个时间步。 基于 $k$ 个候选输出序列将会继续从 $k \mid \mathcal{Y} \mid$选择 $k$ 个条件概率最高的候选输出序列。
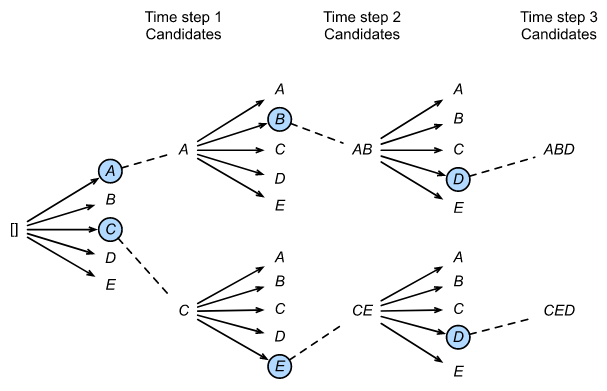
beam size 为 2, 最大输出序列长度为3。 候选输出薛烈为 A, C, AB, CE, ABD, 和 CED。
假设输出次换标仅包含五个元素: $\mathcal{Y} = {A, B, C, D, E}$, 其中一个是 <eos>。 使用beam size 为 2 和 输出序列的最大长度为3. 在时间步1, 假设最高条件概率 $P(y_1 \mid c)$ 的 token 是 $A$ 和 $C$。 在时间步2, 对于所有 $y_2 \in \mathcal{Y}$ , 我们计算:
在十个值中选择最大的两个 $P(A, B \mid c)$ 和 $P(C, E \mid c)$。 然后在时间步 3, 对于所有 $y_3 \in \mathcal{Y}$, 我们计算:
\[P(A, B, y_3 \mid c) = P(A, B \mid c)P(y_3 \mid A, B, c)\] \[P(C, E, y_3 \mid c) = P(C, E \mid c) P(y_3 \mid C, E, c)\]接着在这是个值中选择最大的两个 $P(A, B, C, D \mid c)$ 和 $P(C, E, D \mid c)$。 结果我们得到六个候选输出序列 i) $A$ ii) C iii) A, B iv) C, E v) A, B, D; vi) C, E, D。
在最后, 我们得到基于六个序列的最终候选输出序列. 然后我们选择接下来分数最高的序列作为输出序列:
\[\frac{1}{L^{\alpha}} \log P(y_1, ..., y_L \mid c) = \frac{1}{L^\alpha} \sum_{t' = 1}^L \log P(y_{t'} \mid y_1, ..., y_{t' - 1}, c)\]$L$ 是最终候选序列的长度 , $\alpha$ 通常设为 0.75. 因为更长的句子有更高的对数和, $L^{\alpha}$ 惩罚长序列。
beam search 的计算成本为 $O(k \mid \mathcal{Y} \mid T’)$。 这个结果在 穷尽搜索和 贪婪搜索 之间。 当 beam size 为1时, 贪婪搜索可以视为特殊的束搜索。 灵活地选择beam size权衡了准确率和计算复杂度。