动态学习率
将 $\eta$ 替换为一个依赖时间的学习率 $\eta(t)$ 会增加优化算法的复杂度。 特别是我们需要找出怎样的 $\eta$ 会快速的下降。 如果它太快,我们将过早地停止优化。如果我们降低得太慢,我们就会在优化上浪费太多时间。下面是一些基本的用于随着时间调整 $\eta$ 的策略:
\[\eta(t) = \eta_i \quad \text{ if } t_i \leq t \leq t_{i+1} \qquad \text{piecewise constant}\] \[\eta(t) = \eta_0 · e^{-\lambda t} \qquad \qquad \text{exponential decay}\] \[\eta(t) = \eta_0 · (\beta t + 1)^{-\alpha} \qquad \qquad \text{polynomial decay}\]在第一个 piecewise constant 场景中,当优化取得进展时我们降低学习率。 这是训练深度网络的常用策略。或者我们可以通过 exponential decay 来更剧烈地减小它。不幸的是,这通常会导致在算法收敛之前过早停止。一个受欢迎的选择是 $\alpha = 0.5$ 的 polynomial decay。 在凸优化的情况下,有许多证明表明这个速率是良好的。
让我们看看实际中的指数衰减是怎样的。
1
2
3
4
5
6
7
8
9
def exponential_lr():
# Global variable that is defined outside this function and updated inside
global t
t += 1
return math.exp(-0.1 * t)
t = 1
lr = exponential_lr
d2l.show_trace_2d(f, d2l.train_2d(sgd, steps=1000, f_grad=f_grad))
1
epoch 1000, x1: -0.903849, x2: 0.026687
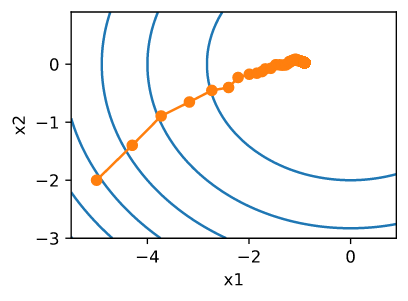
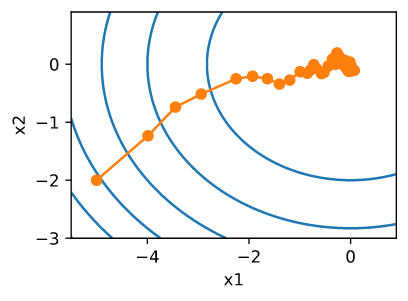
如预期的那样,参数中的方差显著减少。然而,这是以不能收敛到最优解 $x = (0, 0$ 为代价的。 即使经过1000个迭代步骤,我们仍然离最优解决方案很遥远。实际上,该算法根本无法收敛。另一方面,如果我们使用一个步数的负平方根的学习速率衰减的polynomial decay,收敛性在仅仅50步后变得更好。
1
2
3
4
5
6
7
8
9
def polynomial_lr():
# Global variable that is defined outside this function and updated inside
global t
t += 1
return (1 + 0.1 * t)**(-0.5)
t = 1
lr = polynomial_lr
d2l.show_trace_2d(f, d2l.train_2d(sgd, steps=50, f_grad=f_grad))
1
epoch 50, x1: -0.067160, x2: -0.054952
对于如何设置学习率,有更多的选择。例如,我们可以从一个小的速率开始,然后迅速上升,然后再次下降。我们甚至可以在更小和更大的学习速率之间交替。存在着各种各样的这样的学习率策略。对于一般的非凸问题,由于极小化非线性非凸问题一般是NP hard的,因此很难得到有意义的收敛保证。
凸目标的收敛分析
假设目标函数 $f(\xi, x)$ 对于所有的 $\xi$ 是凸的。更具体地, 我们考虑随机梯度的更新:
\[x_{t+1} = x_t - \eta_t \partial_x f(\xi_t, x)\]其中 $f(\xi_t, x)$ 是对于每个训练样本 $\xi_t$ 的目标函数, $\xi_t$ 是在时间步 $t$ 采样自一些分布的样本, $x$ 是模型参数。
\[R(x) = E_{\xi}[f(\xi, x)]\]$R$ 表示期望风险, $R^*$ 表示对于 $x$ 最小化的期望风险。我们计算在时间 $t$ 当前的参数 $x_t$ 与 风险最小化的 $x^*$ 之间的距离, 来看效果是否随着时间有提升:
\[\begin{aligned} \| x_{t+1} - x^* \|^2 &= \| x_t - \eta_t \partial_x f(\xi_t, x) - x^* \|^2 \\ &= \| x_t - x^* \|^2 + \eta_t^2 \| \partial_x f(\xi_t, x)\|^2 - 2\eta_t <x_t - x^*, \partial_x f(\xi_t, x)> \end{aligned} \tag{11.4.8}\]我们假设随机梯度 $\partial_x f(\xi_t, x)$ 的 $L_2$ 范数由某个常数约束, 因此我们有:
\[\eta_t^2 \| \partial_x f(\xi_t, x) \|^2 \leq \eta_t^2 L^2 \tag{11.4.9}\]我们更感兴趣的是在期望中 $x_t$ 和 $x^*$ 之间的距离如何变化。 事实上, 对特定序列的某一步, 距离可能增加, 这取决于遇到的 $\xi_t$。 因此我们需要限制点积。 因为对于任意凸函数 $f$, 对于所有 $x$ 和 $y$, 有 $f(y) \geq f(x) + <f’(x), y-x>$。 因此我们有:
\[f(\xi_t, x^*) \geq f(\xi_t, x_t) + <x^* - x_t, \partial_x f(\xi_t, x_t)> \tag{11.4.10}\]将 11.4.9 和 11.4.10 代入 11.4.8。 我们得到在时间 $t+1$ 参数之间距离的边界:
\[\| x_t - x^* \|^2 - \| x_{t+1} - x^* \|^2 \geq 2 \eta_t (f(\xi_t, x_t) - f(\xi_t, x^*)) - \eta_t^2 L^2 \tag{11.4.11}\]这意味着只要现在的损失和最优损失的差异超过 $\eta_t L^2 / 2$, 我们就会取得进展。因为差异会逐渐收敛到0, 因此学习率 $\eta_t$ 也需要逐渐变小。
接下来我们对 11.4.11 求期望。 这会产生:
\[E[ \|x_t - x^*\|^2] - E[ \|x_{t+1} - x^*\|^2] \geq 2 \eta_t [E[R(x_t)] - R^*] - \eta_t^2L^2 \tag{11.4.12}\]我们可以将上面的不等式按照时间 $t \in {1, …, T}$ 展开, 丢掉最小项, 因为最后只有一项 $x_1$, 因此可以去掉期望, 我们得到:
\[\|x_1 - x^*\|^2 - \|x_{2} - x^*\|^2\geq 2 \eta_1 [E[R(x)] - R^*] - \eta_1^2L^2 \\ \|x_2 - x^*\|^2 - \|x_{3} - x^*\|^2 \geq 2 \eta_2 [E[R(x)] - R^*] - \eta_2^2L^2 \\ ...\] \[\|x_1 - x^*\|^2 \geq 2(\sum_{t=1}^T \eta_t) [E[R(x_t)] - R^*] - L^2 \sum_{t=1}^T \eta_t^2 \tag{11.4.13}\]最后定义:
\[\bar x \mathop{=}^{def} \frac{\sum_{t=1}^T n_t x_t}{\sum_{t=1}^T \eta_t} \tag{11.4.14}\]因为:
\[E(\frac{\sum_{t=1}^T \eta_t R(x_t)}{\sum_{t=1}^T \eta_t}) = \frac{\sum_{t=1}^T \eta_T E[R(x_t)]}{\sum_{t=1}^T \eta_t} = E[R(x_t)] \tag{11.4.15}\]通过Jensen不等式(将11.2.3公式设置 $i=t, \alpha_i = \eta_t / \sum_{t=1}^T \eta_t$) 以及 $R$ 的凸性, 有$E[R[x_t]] \geq E[R(\bar x)]$, 因此:
\[\sum_{t=1}^T \eta_t E[R(x_t)] \geq \sum_{t=1}^T \eta_t E[R(\bar x)] \tag{11.4.16}\]将它代入不等式 11.4.13, 得到:
\[[E[\bar x]] - R^* \leq \frac{r^2 + L^2 \sum_{t=1}^T \eta_t^2}{2 \sum_{t=1}^T \eta_t}\]其中 $r^2 \mathop{=}^{def} |x_1 - x^*|^2$ 是初始选择参数和最终结果之间距离的界。简而言之, 收敛的速度依赖于随机梯度被限制的范数大小以及最优参数值与初始参数值距离的远近 $(r)$。 注意, 是 $\bar x$ 的界而不是 $x_T$的界。 因为 $\bar x$ 是优化路径的光滑版本。 当我们知道 $r$、$L$ 和 $T$ 时, 我们可以选择学习率 $\eta = r / (L\sqrt{T})$。 这会产生上界 $rL/\sqrt{T}$。 也就是说, 我们以速率 $O(1 / \sqrt{T})$ 收敛到最优解。
Stochastic Gradients and Finite Samples
我们从某个分布 $p(x, y)$ 采样一些样本 $x_i$, 标签 $y_i$, 并且我们使用它以某种方式更新模型参数。特别地, 对于有限大小的样本我们仅讨论了对于一些函数 $\delta_{x_i}$ 和 $\delta_{y_i}$, 离散分布 $p(x, y) = \frac{1}{n} \sum_{i=1}^n \delta_{x_i}(x) \delta_{y_i}(y)$ 使得我们可以在上面实现随机梯度下降。
在本节简单的例子中, 我们只是在一个非随机梯度上添加了噪声, 比如我们假设有 $(x_i, y_i)$对。 结果证明这是合理的。在之前的讨论中,我们没有这样做。 而且, 我们对所有样本仅迭代了依次。 要直到为什么这是可取的,请考虑相反的情况, 也就是说我们从离散分布中以放回的方式采样 $n$ 个观测。 选择一个元素 $i$ 的概率是随机的 $1/n$。 因此选择它至少一次的概率是:
\[P(\text{choose }i) = 1 - P(\text{omit } i) = 1 - (1 - 1/n)^n \approx 1 - e^{-1} \approx 0.63\]一个类似的推理表明,选取某个样本(即训练样本)恰好一次的概率为:
\[{n \choose 1} \frac{1}{n} \left(1-\frac{1}{n}\right)^{n-1} = \frac{n}{n-1} \left(1-\frac{1}{n}\right)^{n} \approx e^{-1} \approx 0.37.\]与不放回的采样相比,这导致了方差的增加和数据效率的降低。最后注意,重复通过训练数据集以不同的随机顺序遍历它。