深度学习框架(如MXNet和PyTorch)在后端自动构建计算图。通过使用计算图,系统知道所有的依赖关系,并可以有选择地并行执行多个不依赖的任务,以提高速度。例如,第12.2节中的图12.2.2分别初始化了两个变量。因此,系统可以选择并行执行它们。
通常,单个操作符将使用所有cpu或单个GPU上的所有计算资源。例如,点积操作符将使用所有CPU上的所有内核(和线程)。这同样适用于单个GPU。因此,并行化对于单设备计算机不是很有用。在多设备中,它更重要。虽然并行化通常与多个GPU相关,但加上本地CPU将略微提高性能。例如,参见[Hadjis et al., 2016],专注于结合GPU和CPU训练计算机视觉模型。有了自动并行化框架的便利,我们只需几行Python代码就可以实现同样的目标。更广泛地说,我们对自动并行计算的讨论主要集中在使用CPU和GPU的并行计算,以及计算和通信的并行化。
注意,我们至少需要两个GPU来运行本节中的实验。
Parallel Computation on GPUs
让我们从定义要测试的参考工作负载开始:下面的run函数使用分配给两个变量 $x_{gpu1}$ 和 $x_{gpu2}$ 的数据,在我们选择的设备上执行10次矩阵-矩阵乘法。
1
2
3
4
5
6
7
devices = d2l.try_all_gpus()
def run(x):
return [x.mm(x) for _ in range(50)]
x_gpu1 = torch.rand(size=(4000, 4000), device=devices[0])
x_gpu2 = torch.rand(size=(4000, 4000), device=devices[1])
现在我们将函数应用于数据。torch.cuda.synchronize() 等待CUDA设备上所有流中的所有内核完成。 它接受一个 device 参数, 它是我们要同步的设备。 如果参数为 None 的话, 它使用 current_device() 返回的设备。
1
2
3
4
5
6
7
8
9
10
11
12
run(x_gpu1)
run(x_gpu2) # Warm-up all devices
torch.cuda.synchronize(devices[0])
torch.cuda.synchronize(devices[1])
with d2l.Benchmark('GPU1 time'):
run(x_gpu1)
torch.cuda.synchronize(devices[0])
with d2l.Benchmark('GPU2 time'):
run(x_gpu2)
torch.cuda.synchronize(devices[1])
1
2
GPU1 time: 0.4902 sec
GPU2 time: 0.4866 sec
如果我们移除两个任务之间的 synchronize 语句,系统就可以自由地在两个设备上自动并行化计算。
1
2
3
4
with d2l.Benchmark('GPU1 & GPU2'):
run(x_gpu1)
run(x_gpu2)
torch.cuda.synchronize()
1
GPU1 & GPU2: 0.4905 sec
在上述情况下,总执行时间小于其各部分之和,因为深度学习框架自动调度在两个GPU设备上的计算,而不需要用户编写复杂的代码。
Parallel Computation and Communication
在很多情况下,我们需要在不同的设备之间移动数据,比如在CPU和GPU之间,或者在不同的GPU之间。例如,当我们想要执行分布式优化,需要在多个加速卡上聚合梯度时,就会发生这种情况。让我们通过在GPU上计算来模拟这个过程,然后将结果复制回CPU。
1
2
3
4
5
6
7
8
9
10
def copy_to_cpu(x, non_blocking=False):
return [y.to('cpu', non_blocking=non_blocking) for y in x]
with d2l.Benchmark('Run on GPU1'):
y = run(x_gpu1)
torch.cuda.synchronize()
with d2l.Benchmark('Copy to CPU'):
y_cpu = copy_to_cpu(y)
torch.cuda.synchronize()
1
2
Run on GPU1: 0.4904 sec
Copy to CPU: 2.3032 sec
这是有点效率低下。注意我们可以在计算剩余列表的同时将部分的 y 复制到 CPU。这种情况在我们计算一个 minibatch 反向传播梯度的情况下会出现。 一些参数的梯度将比其他参数的梯度更早可用。因此,在GPU还在运行的时候就开始使用PCI-Express总线带宽对我们是有好处的。在Pytorch中, 几个如 to() 和 copy_() 的函数接受 non_blocking 参数, 这会使得调用者在不必要的时候不进行同步。
1
2
3
4
with d2l.Benchmark('Run on GPU1 and copy to CPU'):
y = run(x_gpu1)
y_cpu = copy_to_cpu(y, True)
torch.cuda.synchronize()
1
Run on GPU1 and copy to CPU: 1.6358 sec
两项操作所需的总时间(正如预期的那样)小于它们各部分之和。注意,这个任务与并行计算不同,因为它使用不同的资源: CPU和GPU之间的总线。事实上,我们可以同时在两个设备上进行计算和通信。如上所示, 计算和通信之间存在依赖关系: y[i] 必须在它拷贝到 CPU 之前计算。 幸运的是, 系统可以在计算 y[i] 的时候拷贝 y[i-1] 以减少全部运行时间。
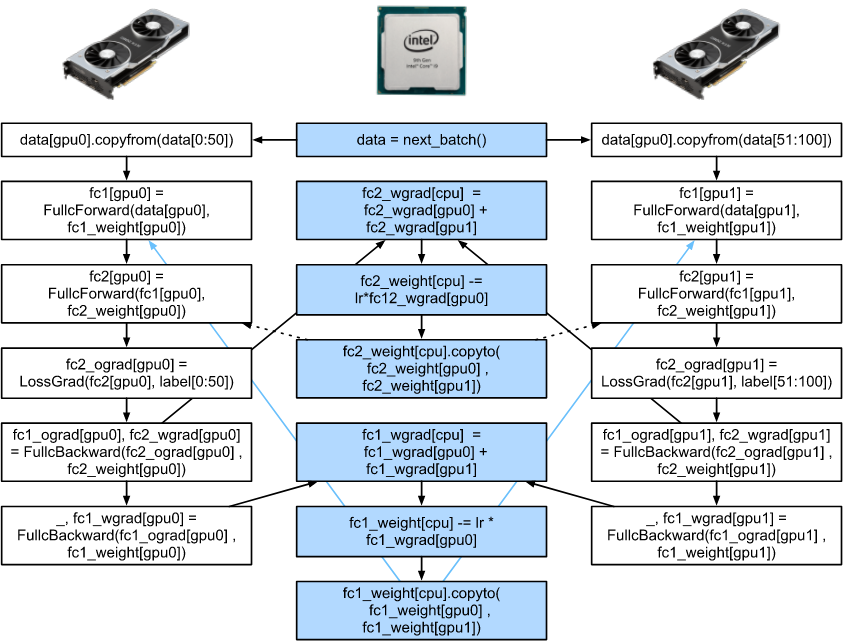
12.3.1 展示了当在 CPU 和 两个 GPU 上训练一个简单的两层的 MLP 时的依赖关系, 以及解释了计算图。 手动调度由此产生的并行程序是相当痛苦的。这就是使用基于图的计算后端进行优化的优势所在。