构建具有良好性能的系统需要对算法和模型有很好的理解,以捕获统计方面的问题。同时,对底层硬件有一点了解也是必不可少的。一个好的设计可以轻易地产生数量级的影响。 我们将从计算机开始。然后我们将放大更仔细地看CPU和GPU。最后,我们将查看服务器中心或云中的多台计算机是如何连接的。

Computers
大多数深度学习研究人员和实践者都可以使用具有相当大内存、计算量、以及一些诸如GPU之类的加速器。 计算机由下列关键部件组成:
- 一个处理器(也称为CPU),能够执行我们给它的程序(除了运行操作系统和许多其他东西),通常由8个或更多的核心组成。
- 内存(RAM),用于存储和检索计算结果,如权重向量和激活,以及训练数据。
- 一个速度从 1 GB/s 到 100 GB/s 的以太网。
- PCIe (high speed expansion bus),用于将系统连接到一个或多个GPU。服务器有多达8个加速器,通常以高级拓扑连接,而桌面系统有1或2个,这取决于用户的预算和电源的大小。
- 长期的存储器,如硬盘驱动器,固态驱动器,在很多情况下通过PCIe总线连接。它能有效地向系统传送训练数据,并根据需要储存中间检查点。
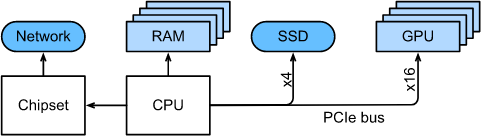
如上图所示, 大部分部件(网络、GPU、存储)通过PCIe总线连接到CPU。 它由多个直接连接到CPU的通道组成。以AMD 线程撕裂者3为例, 他有 64 个 PCIe 4.0 通道,每个通道可以双向传输 16 Gbits/s 的数据。 直接连接到CPU的内存带宽可达到 100 GB/s。当我们在计算机上运行代码时,我们需要将数据转移到处理器(CPU或GPU),执行计算,然后将结果从处理器移回RAM和长时间存储。因此,为了获得良好的性能,我们需要确保它能够无缝地工作,而不会让任何一个系统成为主要的瓶颈。例如,如果我们不能足够快地加载图像,处理器就没有工作可以做。同样地,如果我们不能足够快地将矩阵移动到CPU(或GPU),它的处理单元将会除饥饿状态。最后,如果我们想在网络上同步多台计算机,后者不应该降低计算速度。一种选择是交叉通信和计算。让我们更详细地看看各个组件。
Memory
在最基本的情况下,内存是用来存储需要容易访问的数据的。当前 CPU RAM 通常使用 DDR4, 每个模块提供20-25GB/s 的带宽。 每个模块提供 64位 的总线。 通常使用成对的内存模块来支持多个通道。CPU 有两个到四个内存通道, 比如他们有 40GB/s 到 100GB/s 的峰值带宽 。通常每个通道有两个bank。 比如AMD Zen3 线程撕裂者有8个槽。
虽然这些数字令人印象深刻,但它们只是故事的一部分。当我们想要从内存中读取一部分信息时,首先需要告诉内存模块在哪里可以找到信息。也就是说,我们首先需要将地址发送到RAM。一旦找到了, 我们可以从记录中读取单个64位记录和一个长序列记录。 后者叫做 burst read。 简而言之,发送一个地址到内存和设置传输大约需要100纳秒(细节取决于使用的内存芯片的特定定时系数),每次后续传输只需要0.2纳秒。也就是说,第一次读取的代价是后续读取的500倍!注意,我们每秒最多可以执行10,000,000次随机读取。这建议我们尽量避免随机内存访问,而使用 burst read。
考虑到我们有多个 bank,情况就有点复杂了。每个 bank 基本上可以独立地读取内存。这意味着两件事。一方面,随机读的有效数量高达4倍,前提是它们在内存中均匀分布。这也意味着执行随机读取仍然是一个糟糕的主意,因为 burst read 也要快4倍。另一方面, 由于内存对齐到 64 位边界,因此将任何数据结构对齐到相同的边界是一个好主意。当适当的标志被设置时,编译器会自动完成这一操作。
GPU内存受到更高的带宽要求,因为它们可以比CPU处理更多的元素。总的来说,解决这些问题有两种选择。第一种方法是使内存总线明显变宽。例如,NVIDIA的RTX 2080 Ti拥有352位宽的总线。这允许更多的信息在同一时间被传送。其次,GPU使用特定的高性能内存。定制级别的设备, 比如 NVIDIA的 RTX 和 Titan 系列 使用超过500GB/s 聚合带宽的 GDDR6 芯片。另一种选择是使用HBM(high bandwidth memory)模块。它们使用非常不同的接口,直接连接专用硅片上的GPU。这使得它们非常昂贵,它们的使用通常仅限于高端服务器芯片,如NVIDIA Volta V100系列加速器。毫不奇怪,GPU内存通常比CPU内存小得多,因为前者的成本更高。就我们的目的而言,大体上它们的性能特征是相似的,只是快得多。
Storage
我们看到RAM的一些关键特性是带宽和延迟。存储设备也是如此,只是差异可能更极端。
Hard Disk Drives
Hard disk drives (HDDs)已经使用了半个多世纪。它们包含许多具有磁头的旋转盘片,可以在任何给定轨道上读取或写入。高端磁盘在9个盘片上可容纳16 TB。HDDs的一个主要优点是相对便宜。它们的许多缺点之一是典型的灾难性故障模式和相对较高的读延迟。
Solid State Drives
固态硬盘(ssd)使用闪存持久存储信息。这允许更快地访问存储的记录。现代 SSD 可以运行在100,000到500,000 IOPs,也就是说,比HDDs快3个数量级。此外, 它们的带宽能到达到 1 - 3 GB/s,比HDDs快一个数量级。 这些改进听起来好得令人难以置信。实际上,由于ssd的设计方式,它们都带有以下注意事项:
- SSDs以块(256kb或更大)的形式存储信息。它们只能作为一个整体来写,这需要大量的时间。因此,SSD上按位随机写的性能非常差。同样,写入数据通常需要很长时间,因为必须读取、擦除数据块,然后用新信息重写数据块。到目前为止,SSD控制器和固件已经开发了算法来缓解这一问题。尽管如此,写入可能会慢得多,特别是对于QLC(quad level cell)SSDs。提高性能的关键是维护一个操作队列,尽可能在大块中读和写。
- SSDs中的内存单元损耗相对较快(通常已经写了几千次)。Wear-level 保护算法能够将退化分散到多个单元。也就是说,不建议将SSDs用于交换文件或日志文件的大型聚合。
- 最后,带宽的大幅增加迫使计算机设计人员将SSDs直接连接到PCIe总线上。能够处理这种情况的驱动器被称为NVMe(增强的非易失性内存),最多可以使用4个PCIe通道。这在 PCIe 4.0 上共计 8GB/s。
Cloud Storage
云存储提供了一个可配置的性能范围。也就是说,根据用户的选择,虚拟机的存储分配是动态的,在数量和速度方面都是动态的。我们建议用户在延迟过高的情况下增加IOPs的预备数,例如在有很多小记录的训练中。
CPUs
中央处理器(cpu)是任何计算机的核心部件。他们由许多关键部件:处理器核心能够执行的机器代码,总线连接(具体的拓扑结构在处理器模型、代和厂商之间存在显著差异)以及允许更高的带宽和更低的内存访问延迟的 Caches。最后,几乎所有现代CPU都包含向量处理单元,以辅助高性能线性代数和卷积,因为它们在媒体处理和机器学习中很常见。
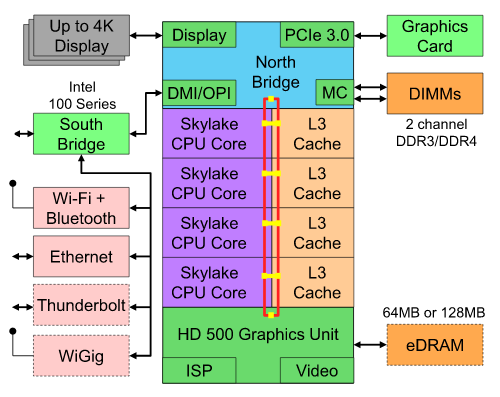
上图描述了英特尔Skylake消费级四核CPU。 它有集成的GPU、缓存和连接四个核的环形总线。以太网、WiFi、蓝牙、SSD控制器、USB等外设都是芯片组的一部分,或者通过PCIe直接连接到CPU上。
Microarchitecture
每个处理器核心都由一组相当复杂的组件组成。虽然不同的代和厂商在细节上有所不同,但基本功能是相当标准的。前端加载指令并尝试预测将采用哪条路径(例如,控制流)。指令然后从汇编代码解码为微指令。汇编代码通常不是处理器执行的最低级别代码。进而,复杂的指令可以被解码成一组更低级的操作。然后由实际的执行核心处理它们。后者通常能够同时执行许多操作。如下图所示的 ARM Cortex A77 核心 能够同时处理 8 个操作。
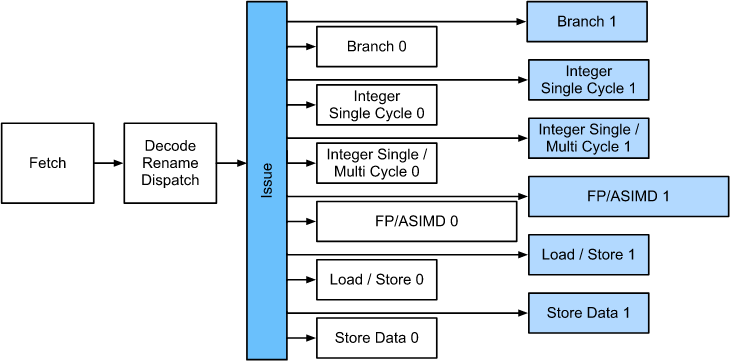
这意味着高效的程序可以在每个时钟周期内执行多条指令,前提是它们可以独立执行。不是所有的单元都是平等的。一些专门用于整数指令,而另一些则为浮点性能进行了优化。为了提高吞吐量,处理器还可能在分支指令中同时遵循多个代码路径,然后丢弃未执行的分支的结果。这就是为什么分支预测单元(在前端)很重要,以便追求最有希望的路径。
Vectorization
深度学习是极其需要计算的。因此,要使CPU适合机器学习,需要在一个时钟周期内执行许多操作。这是通过矢量单元实现的。它们有不同的名称:在ARM上它们被称为NEON,在x86上(最近一代)它们被称为AVX2单元。一个常见的方面是它们能够执行SIMD(单指令多数据)操作。
依赖于架构选择, 寄存器可达到512位长, 使得可以组合多达64对数。 例如,我们可能将两个数相乘,然后将它们加到第三个数上,这也被称为融合乘数加。Intel的OpenVino使用这些来实现服务器级cpu上的深度学习的可观吞吐量。但请注意,这个数字与GPU能够实现的功能相比是微不足道的。例如,NVIDIA的RTX 2080 Ti有4352个CUDA核,每个核都可以在任何时间处理这样的操作。
GPUs and other Accelerators
可以毫不夸张地说,如果没有GPUs,深度学习就不会成功。出于同样的原因,GPU制造商的财富也因为深度学习而大幅增长。硬件和算法的共同进化导致了这样一种情况,即无论好坏,深度学习都是更好的统计建模范式。因此,理解GPUs和相关加速器(如TPU)的具体好处是值得的。
值得注意的是在实践中经常出现的区别: 加速器是为训练或推理而优化的。对于后者,我们只需要计算网络中的正向传播。不需要为反向传播存储中间数据。此外,我们可能不需要非常精确的计算(FP16或INT8通常就足够了)。另一方面,在训练过程中,所有的中间结果都需要存储来计算梯度。此外,累积梯度要求更高的精度,以避免数值溢出。这意味着FP16(或与FP32混合精度)是最低要求。所有这些都需要更快、更大的内存(HBM2 vs. GDDR6)和更强的处理能力。例如,NVIDIA的Turing T4图形处理器被优化用于推理,而V100图形处理器更适合用于训练。
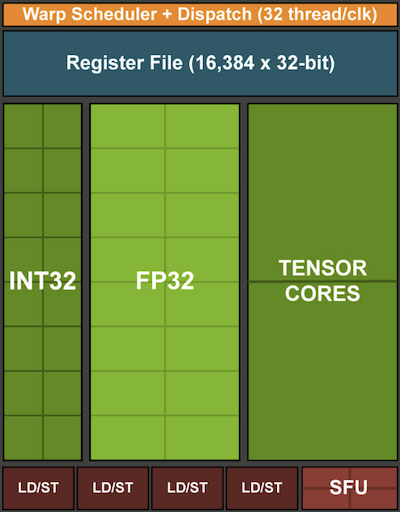
处理器核心添加向量单元可以显著提高吞吐量。首先,如果我们添加不仅优化向量, 还优化矩阵之间的运算会怎么样?这种策略导致了张量核心(稍后将介绍)。 其次,如果我们添加更多的核心会怎样?简而言之,这两种策略概括了GPUs的设计决策。下图给出基本处理块的概述。它包含16个整数和16个浮点单元。除此之外, 两个张量核心加速为深度学习提供了一个加法操作的子集。 每个流多处理器由四个这样的块组成。
接下来,将12个流媒体多处理器分组为图形处理集群,组成高端TU102处理器。充足的内存通道和L2缓存补充了设置。下图展示了相关细节。 设计这种设备的原因之一是,可以根据需要添加或删除单个块, 允许更紧凑的芯片和处理良率问题(故障模块可能不会被激活)。幸运的是,在CUDA和框架代码层之下,这些设备的编程是很隐蔽的。特别是,如果有可用的资源,多个程序很可能在GPU上同时执行。尽管如此,我们还是应该意识到设备的局限性,以避免选择不适合设备内存的型号。

最后一个值得一提的方面是 tensor cores。它们是最近增加的对深度学习特别有效的优化电路的趋势的一个例子。例如,TPU增加了一个缩放阵列用于快速矩阵乘法。该设计旨在支持极少量(第一代 TPU)的大型操作。Tensor cores 的另一方面。它们对包括 $4 \times 4$ 和 $16 \times 16$ 矩阵的操作根据它们的数值精度进行优化。 下图给出了优化的概览:
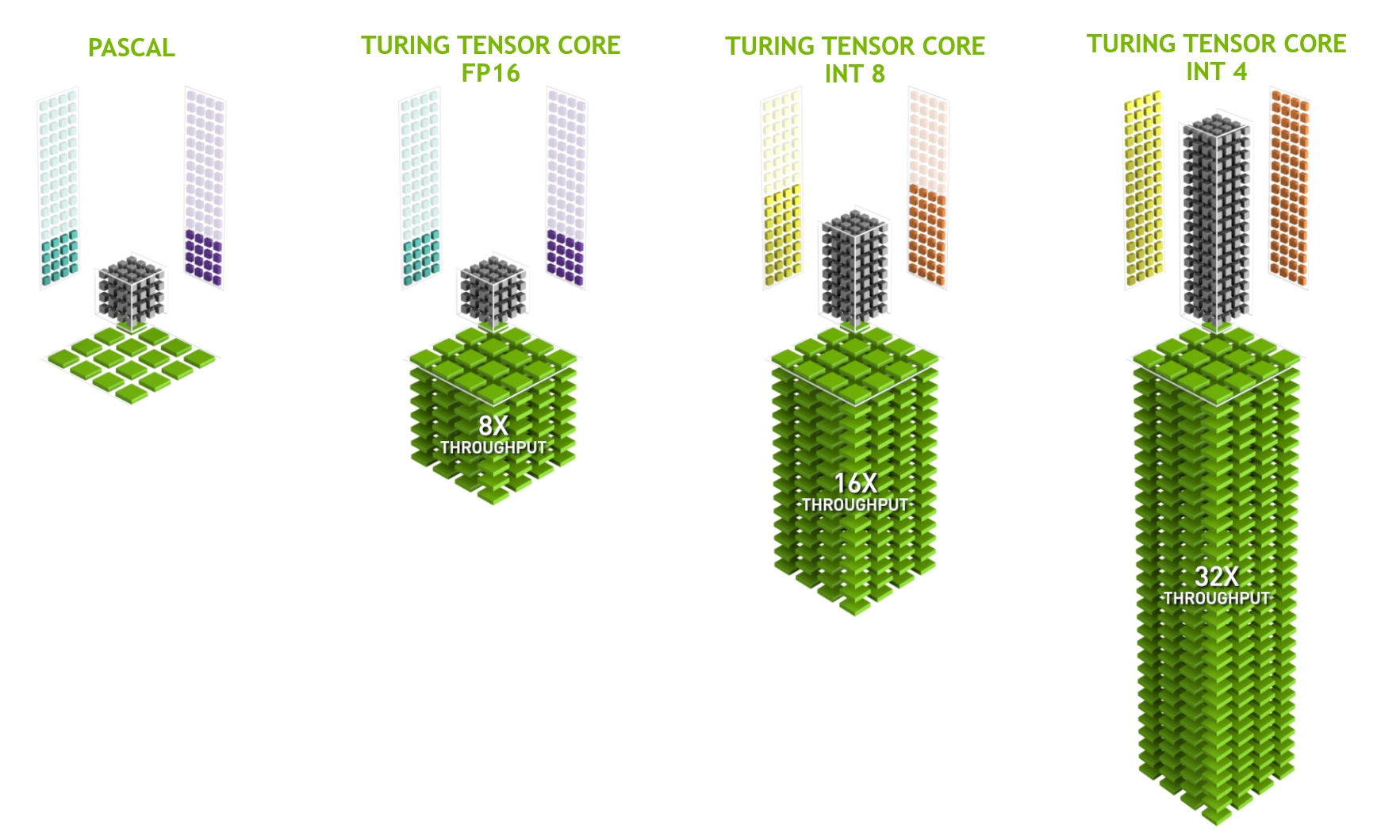
显然,在优化计算时,我们最终会做出某些妥协。其中之一是GPUs不太擅长处理中断和稀疏数据。
Networks and Buses
当单个设备不足以进行优化时,我们需要将数据与它进行传输,以进行同步处理。这就是网络和总线派上用场的地方。我们有许多设计参数:带宽、成本、距离和灵活性。一个是WiFi,范围很广,很容易使用(毕竟没有电线),价格便宜,但提供的带宽和延迟相对中等。任何正常的机器学习研究人员都不会用它来建立一个服务器集群。接下来,我们将专注于适合深度学习的连接:
-
PCIe: PCIe 是用于每通道超高带宽点对点连接(在 PCIe 4.0 上的 16 通道插槽中高达 32 GB/s)的专用总线。延迟约为每位 5us。 PCIe很珍贵。 处理器的PCIe数量有限:AMD 的 EPYC 3 有 128 个通道,Intel 的 Xeon 每个芯片最多有 48 个通道; 在台式机级 CPU 上,数字分别为 20(Ryzen 9)和 16(Core i9)。由于GPU通常有16个通道,这限制了可以以全带宽连接到CPU的GPU数量。毕竟,它们需要与其他高带宽外围设备(如存储器和以太网)共享链路。就像RAM访问一样,大容量传输更好,因为可以减少包开销。
-
Ethernet 是连接计算机最常用的方式。虽然它比PCIe慢得多,但它的安装成本非常低,而且弹性很强,而且覆盖的距离远得多。低级服务器的带宽通常为 1 GBit/s。高端设备(例如云中的 C5 实例)提供 10 到 100 GBit/s 的带宽。和前面所有的情况一样,数据传输有很大的开销。请注意,我们几乎从不直接使用原始以太网,而是使用在物理互连(例如 UDP 或 TCP/IP)之上执行的协议。 这进一步增加了开销。和PCIe一样,以太网被设计用来连接两台设备,例如一台计算机和一台交换机。
-
Switches(交换机) 允许我们以一种方式连接多个设备,其中任何一对设备都可以同时进行点对点连接(通常是全带宽)。例如,以太网交换机可能以高 cross-sectional 带宽连接40个服务器。注意,交换机并不是传统计算机网络所特有的。甚至PCIe通道也可以switched。将大量GPU连接到主机处理器时, 这种情况会发生。
-
NVLink 是替代PCIe在高带宽互连方面的方案。它为每个链路提供高达 300 Gbit/s 的数据传输速率。服务器 GPU (Volta V100) 有六个链接,而消费级 GPU (RTX 2080 Ti) 只有一个链接,以降低的 100 Gbit/s 速率运行。我们建议使用NCCL来实现GPUs之间的高速数据传输。
-
Previous
【d2l】Automatic Parallelism -
Next
【深度学习】SCST:Self-critical Sequence Training for Image Captioning