Abstract
Hateful meme detection 是一个最近的新的研究领域, 它需要视觉和语言上对 meme 的理解,以及一些背景知识来完成任务。这份技术报告总结了 Hateful Meme Detection Challenge 2020 的第一名解决方案,它拓展了 state-of-the-art visual-linguistic trans-formers 来解决这个问题。在报告的最后,我们还指出了不足之处和改进目前方法的可能方向。
Introduction
Hateful Memes Challenge 引入了一个多模数据集。 尽管最近在多模态推理方面取得了进步,但在将最先进的多模态模型应用于这一挑战时,我们仅得到0.71 AUROC,远远落后于非专业的人类表现。本文讨论了常见的多模态推理任务与 meme classication 的区别。我们的方法在现有视觉语言模型的基础上提高了性能,在 hateful memes detection 数据集上获得了0.845 AUROC。
Problem Description
在典型的视觉-语言多模态数据集中,图像与文本输入之间存在直接关系。Hateful memes 有其独特的特征,与通常的多模态数据集有很大的不同。与VCR和VQA等任务的多模态数据集相比,只有部分数据集与普通多模态下游任务和预训练数据集存在直接关系。大多数时候,表情包的 meme 部分与微妙的措辞或外界对现实事件的知识有关。从这个意义上说,hateful memes challenge 更像是一个视觉-语言-知识的多模态分类问题。
此外,hateful memes 建立在不同的主题上,通常包含没有现成的分类器能识别的新物体,这与在典型的多模态数据集中呈现的日常物体有很大不同。例如injury, traditional costume wear by the subject, historical scenes等视觉暗示难以识别并且样本数量少。这些因素使视觉理解成为挑战的一部分,即使没有语言部分也很难解决。视觉模态上下文对 meme 的极性有巨大的影响。因为即使是最先进的图像分类器或对象检测器, 视觉提示也是很难识别的,合并来自不同来源和格式的信息变得至关重要。
在某些情况下,meme 标题的位置也会影响 meme 的意义。例如,故意把 \wishing machine” 的标题放在女性主题上,会让表情包 meme hateful,但如果我们把标题放在其他任何不是人类的东西上就不会。这在一般的视觉语言模型中并不常见。
Approach
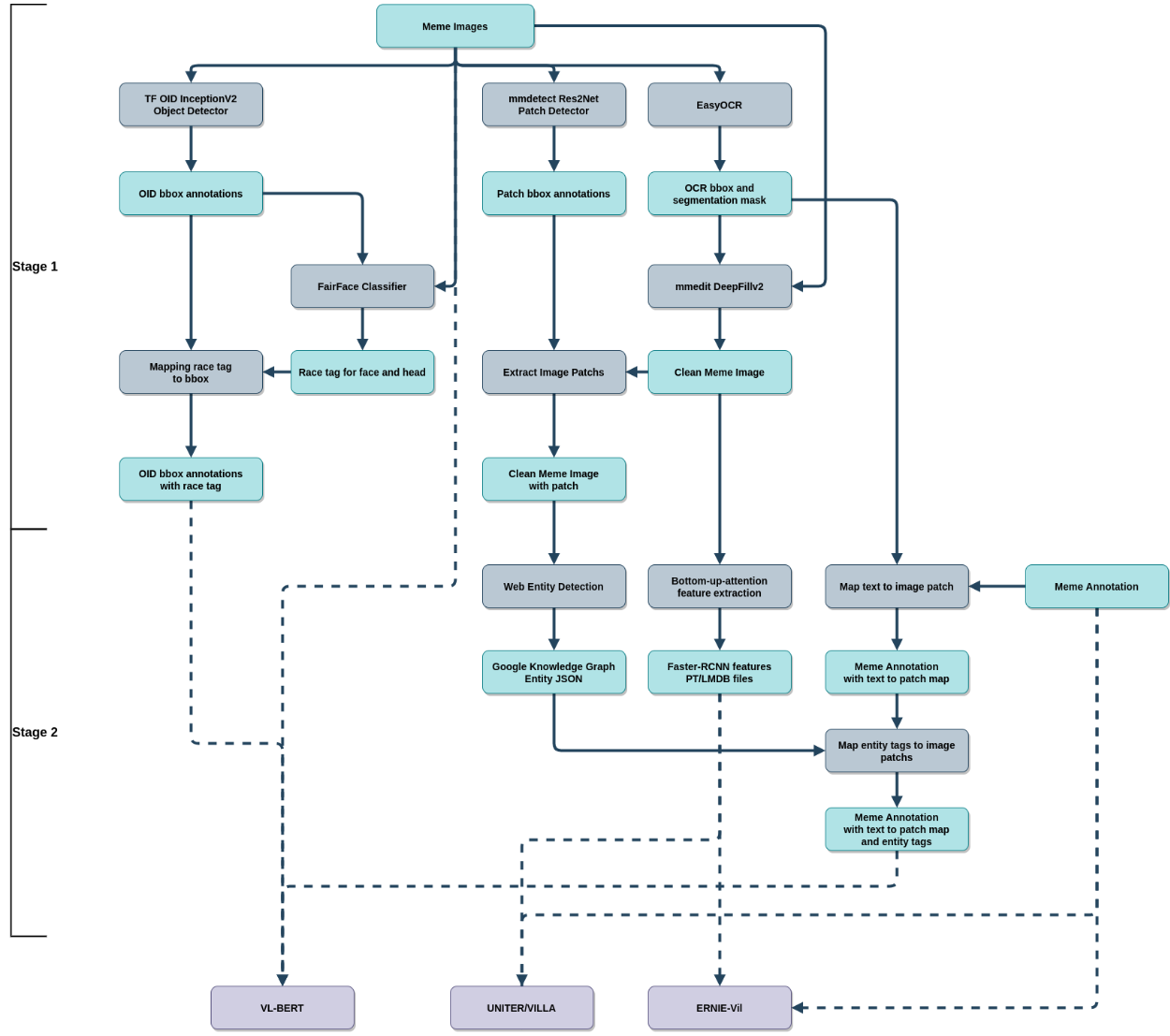
该解决方案包括四种不同的 VL transformer 结构集成, 即: VL-BERT, UNITER, VILLA 和 ERNIE-Vil。 除了ERNIE-Vil模型外,所有模型都进行了修改,以更好地检测 hateful meme。此外,我们还进行了额外的步骤,从 hateful memes 数据集中提取更多的信息,用于训练和推理。
Background
将预训练的 transformer 模型应用到 VL多模态任务中,极大地提高了多个基准的SOTA。最先进的VLTransformer,如Oscar, VILLA, ERNIE-Vil利用大规模的数据集与成对的图像和文本进行预训练。尽管他们在 common sense VL任务上取得了巨大的进步,但预训练过的 VL Transformer在发现hateful meme 方面的表现仍然很差。该任务要求模型对图像、文本、现实事件有深刻的理解,并能够识别三种模式之间的模式间交互作用。
Additional Data Source
正如前面提到的,我们需要更多的图片和文字描述的 memes,以做好 hateful meme 检测。因此,在数据预处理的第一步,我们将尝试使用Web Entity Detection 和 FairFace 分类器从数据源中提取一些关键信息。
Memes 通常包含对著名历史事件、新闻、名人的引用。而新闻话题和不同亚文化趋势的 Memes 也在迅速变化。每隔几天或几周就会出现新的表情包,这并不罕见。因此,仅使用静态知识来源(例如:维基百科)可能不足以解决这个问题。为了应对这一挑战,我们使用Google Vision Web Entity Detection来捕获图像的上下文。除此之外,如果不考虑实体的背景知识和实体之间的关系,我们只解决了问题的一半。
根据 Hateful Meme Challenge 论文,在所有类型的 hateful memes 中,与种族或民族有关的仇恨表情包最为突出。几乎一半的 hateful memes 都可以归为此类。此外,期望预训练的 VL Transformer 仅用来自 hateful memes 数据集的几千个样本来学习识别种族是不现实的。因此包含了由 FairFace 分类器创建的种族和性别标签。 我们首先对图像中的每个人脸或头部进行检测和分类,然后将标签映射回与人脸重叠面积最大的人的边界框。最后,我们应该让大部分人的种族和性别出现在图像中,除非这个人的头部被遮住。
Extend VL-BERT Visual-Linguistic Framework
为了用原始 meme image 和文字联合训练多种类型的标签。我们需要一种方法来无缝地组合来自不同来源和格式的信息。此外,将图片和文本明确链接到外部标签的能力将有助于处理 meme 的独特特性,并且无需从头学习如何使用外部标签。
受到Oscar的启发, 我们将所有外部标签表示为一种特殊类型的文本 token,并使用视觉特征嵌入将其链接到图像的一般区域或特殊图像区域。通过这样做,我们还创建了具有相关图像特征的文本token之间的隐式链接。例如, 文本 token “bowler hat” 与图像的帽子区域 以及 “man dressed in a three-piece suit” 与 覆盖整个戴帽子的人的图像区域。有了这样一个 versertail 框架,我们可以很容易地添加更多类型的标签来处理未来不同类型的 memes。
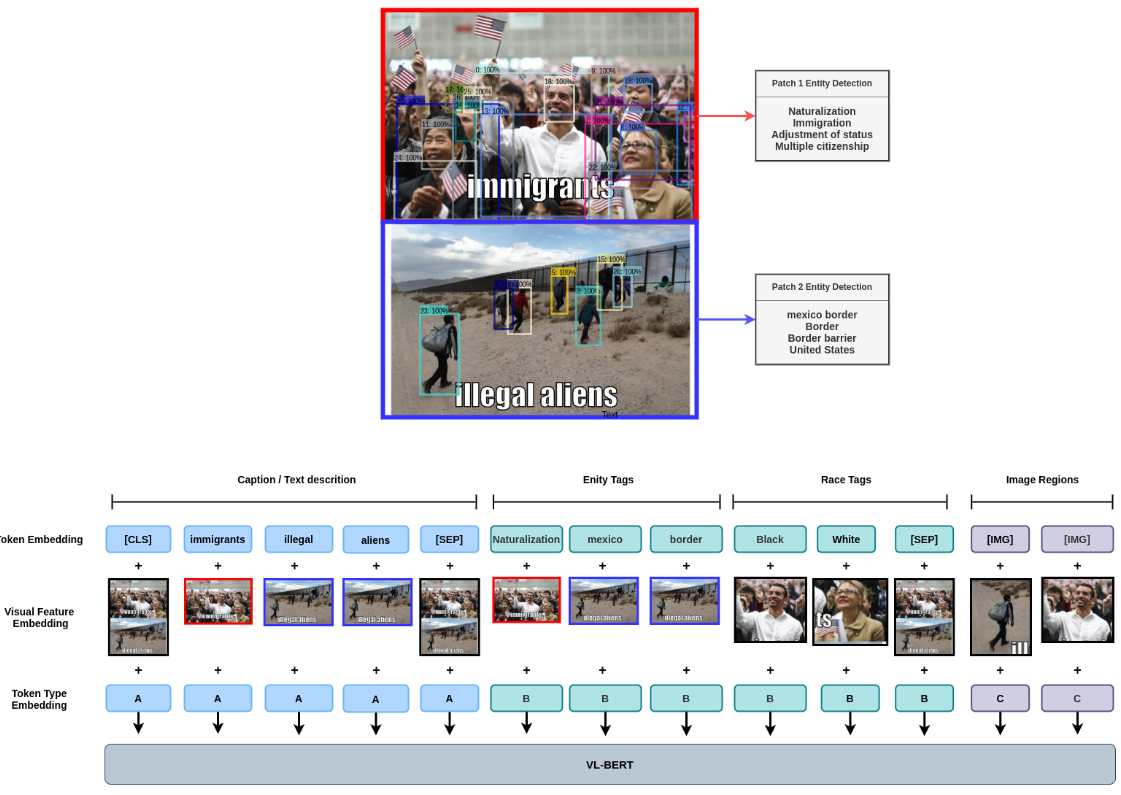
UNITER-ITM
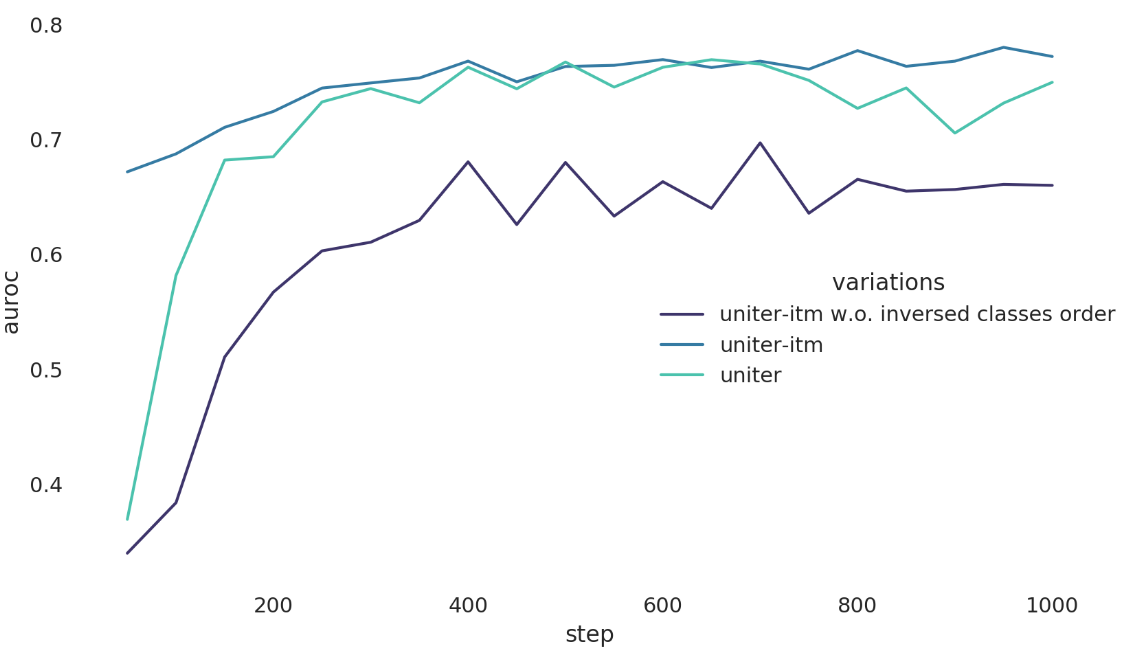
许多预训练 VL Transformer 受到 BERT的 NSP(next sentence prediction)任务启发, 使用 VL adaptation的 ITM(image text matching)任务预训练。尽管一些研究表明,包含ITM任务不会给下游任务带来任何好处,甚至会降低其性能,但我们仍然发现它对当前的任务是有帮助的。在hateful memes 检测任务下,它与ITM之间有明显的联系。也就是说,与图片内容相一致的描述(文本)最有可能是 benign 的,但当它们不一致时,meme 不一定是 hateful 的。
使用 UNITER 预训练 transformer, 我们保留ITM和WRA任务中的预训练 head, 而不是随机初始化分类 head。 然后将分类器 head 的 分类0 变成 分类1, 因词 现在类别 “image-text-match” 将会变成 “benign”, “image-text-not-match” 变成 “hateful”。
最近的研究表明,无论是单流还是双流VL Transformer都倾向于语言模态。通过复用 ITM head 作为开始点, 我们应该得到 减少 linguistic bias 的额外的好处, 因为 ITM 和 WRA 需要视觉和语言特征才能工作,这对于另一个预训练任务并不总是正确的 像 MRC(masked region classi cation)或 MLM(masked language modeling)。
ERNIE-Vil
ERNIE-Vil 是基于从场景图中提取的信息进行预训练的 VL 模型,用于教模型关于细粒度对象属性和关系模型。ERNIE-Vil作为VCR排行榜上的STOA模型,通过一些超参数调整,可以实现与经过拓展的VL-BERT和UNITER-ITM的相竞争的性能。将ERNIE-Vil引入到最终集合中,增加了预测的多样性,提高了泛化程度。
-
Previous
【深度学习】EfficientNetV2:Smaller Models and Faster Training -
Next
【深度学习】Spatial As Deep: Spatial CNN for Traffic Scene Understanding