Other Computer Vision Problems
在前一章中,您学习了一些在实践中训练模型的重要实用技术。选择学习速率和学习时间等因素对于取得好成绩非常重要。
在本章中,我们将看看另外两种类型的计算机视觉问题:多标签分类和回归。第一个是当您希望预测每个图像有多个标签时(或者有时根本没有),第二个是当您的标签是一个或几个数字,而不是一个类别时。
在此过程中,将更深入地研究深度学习模型中的输出激活、目标和损失函数。
Multi-Label Classification
多标签分类是指在图像中识别可能不包含一种类型的对象的类别的问题。可能有不止一种类型的对象,或者在您正在寻找的类中可能根本没有对象。
例如,对于我们的熊分类器来说,这将是一个很好的方法。我们之前的章节中提出的熊分类器的一个问题是,如果用户上传了一些不是熊的种类的东西,模型仍然会说它是灰熊、黑色或泰迪熊,它没有能力预测“根本不是熊”。在我们完成本章之后,回到图像分类器应用,尝试使用多标签技术重新训练它,然后通过传入一个不是您所识别的任何类的图像来测试它。
The Data
例如,我们将使用PASCAL数据集,每张图像可以有多种分类对象。
我们首先像往常一样下载和提取数据集:
1
2
3
from fastai.vision.all import *
path = untar_data(URLs.PASCAL_2007)from fastai.vision.all import *
path = untar_data(URLs.PASCAL_2007)
这个数据集与我们之前看到的数据集不同,因为它不是按文件名或文件夹构建的,而是附带一个CSV(逗号分隔的值)文件,告诉我们每个图像应该使用什么标签。我们可以通过将CSV文件读取到 Pandas DataFrame 中来检查它:
1
2
df = pd.read_csv(path/'train.csv')
df.head()
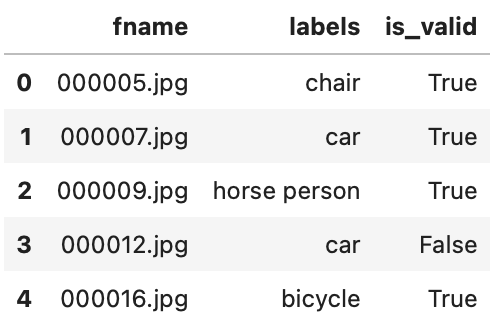
如您所见,每张图像中的类别列表显示为空格分隔的字符串。
Sidebar: Pandas and DataFrames
Pandas是一个Python库,用于操作和分析表格和时间序列数据。主类是DataFrame,它表示行和列表。您可以从CSV文件、数据库表、Python字典和许多其他来源获取DataFrame。在Jupyter中,DataFrame以格式化表的形式输出,如图所示。
您可以使用 iloc 属性访问DataFrame的行和列,就像它是一个矩阵一样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
df.iloc[:,0]
0 000005.jpg
1 000007.jpg
2 000009.jpg
3 000012.jpg
4 000016.jpg
...
5006 009954.jpg
5007 009955.jpg
5008 009958.jpg
5009 009959.jpg
5010 009961.jpg
Name: fname, Length: 5011, dtype: object
1
2
3
4
5
6
7
8
9
df.iloc[0,:]
# Trailing :s are always optional (in numpy, pytorch, pandas, etc.),
# so this is equivalent:
df.iloc[0]
fname 000005.jpg
labels chair
is_valid True
Name: 0, dtype: object
您还可以按名称通过直接索引到 DataFrame 中抓取列:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
df['fname']
0 000005.jpg
1 000007.jpg
2 000009.jpg
3 000012.jpg
4 000016.jpg
...
5006 009954.jpg
5007 009955.jpg
5008 009958.jpg
5009 009959.jpg
5010 009961.jpg
Name: fname, Length: 5011, dtype: object
您可以创建新列并使用列进行计算:
1
2
tmp_df = pd.DataFrame({'a':[1,2], 'b':[3,4]})
tmp_df
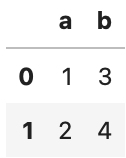
1
2
tmp_df['c'] = tmp_df['a']+tmp_df['b']
tmp_df

pandas 是一个快速灵活的库,是每个数据科学家Python工具箱的重要组成部分。不幸的是,它的API可能相当混乱和令人惊讶,所以需要一段时间才能熟悉它。如果您以前从未使用过熊猫,我们建议您学习教程;我们特别喜欢 Pandas 的创作者Wes McKinney的《Python for Data Analysis》(O’Reilly)一书。它还涵盖了其他重要的库,如matplotlib和numpy。我们将尝试简要描述我们在遇到 pandas 时使用的功能,但不会深入到 McKinney 书中的详细程度。
End sidebar
Constructing a DataBlock
我们如何从 DataFrame 对象转换为 DataLoaders 对象?我们通常建议尽可能使用数据块API创建 DataLoaders 对象,因为它提供了灵活性和简单性的良好组合。在这里,我们将向您展示我们在此数据集为例,在实践中使用数据块API构建 DataLoaders 对象的步骤。
正如我们所看到的,PyTorch和fastai有两个主要类来表示和访问训练集或验证集:
Dataset: 返回单个样本的独立变量和依赖变量元组的集合DataLoader: 一个提供 mini-batches 的迭代器, 每个 mini-batch 是一组独立变量或者相关变量的元组
由于 DataLoader 构建在 Dataset 之上并为其添加其他功能(将多个样本整合到一个 mini-batch 中),因此通常从创建和测试 Dataset 开始最容易,然后在 Datasets 工作完成后查看 DataLoaders 。
让我们从最简单的案例开始,这是一个没有参数的数据块:
1
dblock = DataBlock()
我们可以从中创建一个 Datasets 对象。在这种情况下,唯一需要的是 DataFrame:
1
dsets = dblock.datasets(df)
这包含一个 train 和一个 valid 的数据集:
1
2
3
len(dsets.train),len(dsets.valid)
(4009, 1002)
1
2
3
4
5
6
7
8
9
10
11
x,y = dsets.train[0]
x,y
(fname 008663.jpg
labels car person
is_valid False
Name: 4346, dtype: object,
fname 008663.jpg
labels car person
is_valid False
Name: 4346, dtype: object)
如您所见,这会返回一行 DataFrame 两次。这是因为默认情况下,数据块假设我们有两件事:input 和 target。我们需要从DataFrame中获取适当的字段,我们可以通过传递 get_x 和 get_y 函数来实现:
1
2
3
x['fname']
'008663.jpg'
1
2
3
4
5
dblock = DataBlock(get_x = lambda r: r['fname'], get_y = lambda r: r['labels'])
dsets = dblock.datasets(df)
dsets.train[0]
('005620.jpg', 'aeroplane')
如您所见,我们正在使用 Python 的 lambda 关键字,而不是以通常的方式定义函数。这只是定义然后引用函数的快捷方式。与以下更详细的方法是相同的:
1
2
3
4
5
6
7
def get_x(r): return r['fname']
def get_y(r): return r['labels']
dblock = DataBlock(get_x = get_x, get_y = get_y)
dsets = dblock.datasets(df)
dsets.train[0]
('002549.jpg', 'tvmonitor')
Lambda函数非常适合快速迭代,但它们与序列化不兼容,因此,如果您想在训练后导出 Learner,我们建议您使用更详细的方法(如果您只是在实验,lambdas可以)。
我们可以看到,独立变量需要转换为完整的路径,以便我们可以将其打开为图像,并且依赖变量需要在空格字符上拆分(这是Python拆分函数的默认值),以便它成为一个列表:
1
2
3
4
5
6
7
def get_x(r): return path/'train'/r['fname']
def get_y(r): return r['labels'].split(' ')
dblock = DataBlock(get_x = get_x, get_y = get_y)
dsets = dblock.datasets(df)
dsets.train[0]
(Path('/home/jhoward/.fastai/data/pascal_2007/train/002844.jpg'), ['train'])
要实际打开图像并转换为张量,我们需要使用一组转换;块类型将为我们提供这些变换。我们可以使用之前使用的相同块类型,只有一个例外:ImageBlock 将再次正常工作,因为我们有一个指向有效图像的路径,但 CategoryBlock 将不起作用。问题在于块返回一个整数,但我们需要为每个项目提供多个标签。为了解决这个问题,我们使用多类别块。这种类型的块期望将收到字符串列表,让我们测试一下:
1
2
3
4
5
6
7
dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
get_x = get_x, get_y = get_y)
dsets = dblock.datasets(df)
dsets.train[0]
(PILImage mode=RGB size=500x375,
TensorMultiCategory([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.]))
如您所见,我们的类别列表的编码方式与常规 CategoryBlock 不同。在前者情况下,我们用一个整数确定其类别,根据它在我们的词表中的位置。然而,在后者情况下,使用独热向量表示种类。
让我们检查一下这个样本的类别表示 (我们使用 torch.where 函数, 其告诉我们我们的条件为 True 和 False 的索引)
1
2
3
4
idxs = torch.where(dsets.train[0][1]==1.)[0]
dsets.train.vocab[idxs]
(#1) ['dog']
使用NumPy数组、PyTorch张量和fastai的 L 类,我们可以直接使用列表或矢量进行索引,这使得许多代码(如本示例)更加清晰、更简洁。
到目前为止,我们忽略了 is_valid 列,这意味着 DataBlock 默认一直在使用随机拆分。要显式选择我们验证集的元素,我们需要编写一个函数并将其传递给 splitter (或使用fastai的预定义函数或类之一)。它将以 items 作为输入(这里是我们整个DataFrame),并且必须返回两个(或更多)整数列表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def splitter(df):
train = df.index[~df['is_valid']].tolist()
valid = df.index[df['is_valid']].tolist()
return train,valid
dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
splitter=splitter,
get_x=get_x,
get_y=get_y)
dsets = dblock.datasets(df)
dsets.train[0]
(PILImage mode=RGB size=500x333,
TensorMultiCategory([0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]))
正如我们所讨论的,DataLoader 将 Dataset 的 items 整合到 mini-batch 中。
我们已经确认单个样本看起来还不错,我们需要还有一个步骤来确保我们可以创建 DataLoaders,即确保每个项目大小相同。为此,我们可以使用 RandomResizeCrop:
1
2
3
4
5
6
dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
splitter=splitter,
get_x=get_x,
get_y=get_y,
item_tfms = RandomResizedCrop(128, min_scale=0.35))
dls = dblock.dataloaders(df)
现在我们可以显示我们数据的样本:
1
dls.show_batch(nrows=1, ncols=3)

请记住,如果您从 DataBlock 创建 DataLoaders 时出现任何问题,或者如果您想准确查看 DataBlock 会发生什么,您可以使用我们在上一章中介绍的 summary 方法。
我们的数据现在可以训练模型了。正如我们将看到的,当我们创建 Learner 时,一切都不会改变,但在幕后,fastai库将为我们选择一个新的损失函数: binary cross-entropy。
Binary Cross-Entropy
现在,我们将创建 Learner。我们在上一节中看到,Learner 对象包含四种主要内容:model、DataLoaders对象、优化器和要使用的损失函数。我们已经有了 DataLoaders,我们可以利用 fastai 的 resnet 模型 (稍后我们将学习如何从头创建),并且我们知道如何创建 SGD 优化器。因此,让我们专注于确保我们有一个合适的损失函数。为此,让我们使用 cnn_learner 创建一个 Learner:
1
learn = cnn_learner(dls, resnet18)
我们还看到,Learner 中的模型通常是从 nn.Module 继承的类的对象,我们可以使用括号调用它,它将返回模型的激活。 我们可以通过从 DataLoader 中抓取一个 mini-batch ,然后将其传递给模型来试用:
1
2
3
4
5
x,y = to_cpu(dls.train.one_batch())
activs = learn.model(x)
activs.shape
torch.Size([64, 20])
想想为什么 activs 有这种形状——我们的批处理大小为64,我们需要计算20个类别中每个类别的概率。
1
2
3
4
activs[0]
TensorImage([ 0.7476, -1.1988, 4.5421, -1.5915, -0.6749, 0.0343, -2.4930, -0.8330, -0.3817, -1.4876, -0.1683, 2.1547, -3.4151, -1.1743, 0.1530, -1.6801, -2.3067, 0.7063, -1.3358, -0.3715],
grad_fn=<AliasBackward>)
它们尚未放缩到0到1之间,但我们学会了如何使用 sigmoid 函数做到这一点。我们还看到了如何在此基础上计算损失——这是我们的损失函数,并加上上一章中讨论的 log:
1
2
3
def binary_cross_entropy(inputs, targets):
inputs = inputs.sigmoid()
return -torch.where(targets==1, 1-inputs, inputs).log().mean()
请注意,由于我们有一个独热编码的依赖变量,我们无法直接使用 nll_loss 或 softmax (因此我们无法使用cross_entropy):
softmax:正如我们所看到的,要求所有预测的总和为1,并倾向于推动一个激活比其他激活大得多(由于使用exp);然而,我们很可能有多个我们确信出现在图像中的对象,因此将激活的最大和限制在1不是一个好主意。根据同样的推理,如果我们不认为图像中出现任何类别,我们可能希望总数小于1。nll_loss: 正如我们所看到的,只返回一个激活的值:与样本的单个标签对应的单个激活。当我们有多个标签时,这毫无意义。
另一方面,由于PyTorch按元素操作的魔力,binary_cross_entropy 函数只是 mnist_loss 和 log 一起提供了我们需要的东西。每个激活都将与每列的每个目标进行比较,因此我们无需做任何事情来使此函数适用于多列。
PyTorch已经为我们提供了此功能。事实上,它提供了许多版本,名称相当混乱!
F.binary_cross_entropy 等价于 nn.BCELoss 在独热编码目标上计算交叉熵,但不包括初始 sigmoid。 通常对于一个独热编码的目标,您需要 F.binary_cross_entropy_with_logits(或nn.BCEWithLogitsLoss),它们在单个函数中同时进行 sigmoid 和 binary cross-entropy,如上例所示。
目标编码为单个整数的单标签数据集(如MNIST或Pet数据集)等价于 F.nll_loss 或 nn.NLLLoss 用于没有初始 softmax 的版本,F.cross_entropy 或 nn.CrossEntropyLoss 用于初始softmax的版本。
由于我们有一个独热编码的目标,我们将使用 BCEWithLogitsLoss :
1
2
3
4
5
loss_func = nn.BCEWithLogitsLoss()
loss = loss_func(activs, y)
loss
TensorImage(1.0342, grad_fn=<AliasBackward>)
我们实际上不需要告诉 fastai 使用此损失函数,因为它将自动为我们选择。fastai知道DataLoaders有多个类别标签,因此默认情况下它将使用 nn.BCEWithLogitsLoss。
与上一章相比,一个变化是我们使用的指标:由于这是一个多标签问题,我们无法使用准确性函数。为什么会这样?嗯,准确性是将我们的输出与目标进行比较,就像这样:
1
2
3
4
def accuracy(inp, targ, axis=-1):
"Compute accuracy with `targ` when `pred` is bs * n_classes"
pred = inp.argmax(dim=axis)
return (pred == targ).float().mean()
预测的类别是激活最高的类别(这是argmax所做的)。在这里,它不起作用,因为我们可以在单个图像上进行多个预测。将 sigmoid 应用于我们的激活(使其介于0到1之间)后,我们需要通过选择阈值来决定哪些是0,哪些是1。高于阈值的每个值将被视为1,低于阈值的每个值将被视为0:
1
2
3
4
def accuracy_multi(inp, targ, thresh=0.5, sigmoid=True):
"Compute accuracy when `inp` and `targ` are the same size."
if sigmoid: inp = inp.sigmoid()
return ((inp>thresh)==targ.bool()).float().mean()
如果我们传入 accuracy_multi 直接作为指标 ,它将使用阈值的默认值0.5。我们可能想调整该默认值,并创建一个具有不同默认值的新版本的 accuracy_multi。为了解决这个问题,Python中有一个名为 partial 的函数。它允许我们将函数与一些参数或关键字参数绑定,使该函数的新版本在调用时始终包含这些参数。例如,这里有一个简单的函数,包括两个参数:
1
2
3
4
def say_hello(name, say_what="Hello"): return f"{say_what} {name}."
say_hello('Jeremy'),say_hello('Jeremy', 'Ahoy!')
('Hello Jeremy.', 'Ahoy! Jeremy.')
现在我们切换到使用 partial 的版本:
1
2
3
4
f = partial(say_hello, say_what="Bonjour")
f("Jeremy"),f("Sylvain")
('Bonjour Jeremy.', 'Bonjour Sylvain.')
我们现在可以训练我们的模型了。让我们尝试将指标的准确性阈值设置为0.2:
1
2
learn = cnn_learner(dls, resnet50, metrics=partial(accuracy_multi, thresh=0.2))
learn.fine_tune(3, base_lr=3e-3, freeze_epochs=4)v
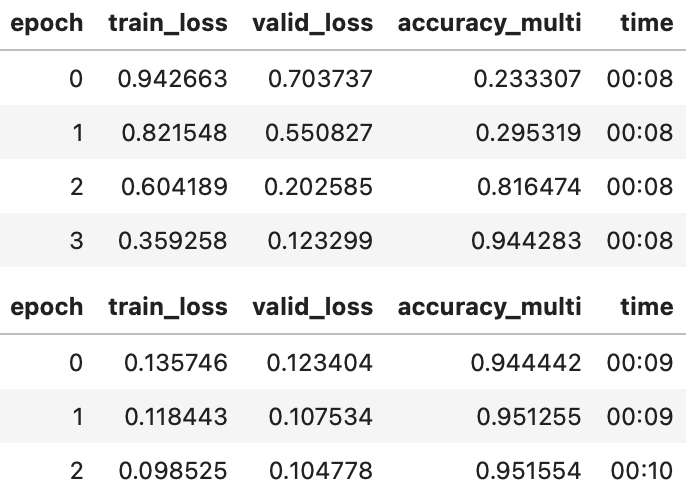
选择阈值很重要。如果您选择的阈值太低,您通常无法选择正确的标签。我们可以通过更改指标,然后调用验证来看到这一点,验证返回验证损失和指标:
1
2
3
4
learn.metrics = partial(accuracy_multi, thresh=0.1)
learn.validate()
(#2) [0.10477833449840546,0.9314740300178528]
如果您选择的阈值太高,您只会选择模型非常有信心的对象:
1
2
3
4
learn.metrics = partial(accuracy_multi, thresh=0.99)
learn.validate()
(#2) [0.10477833449840546,0.9429482221603394]
我们可以通过尝试几个级别并看看什么最有效来找到最佳阈值。
1
preds,targs = learn.get_preds()
然后我们可以直接调用该指标。请注意,默认情况下,get_preds为我们应用输出激活函数(在这种情况下是sigmoid),因此我们需要告诉 accuracy_multi 不要应用它:
1
2
3
accuracy_multi(preds, targs, thresh=0.9, sigmoid=False)
TensorImage(0.9567)
我们现在可以使用这种方法来找到最佳阈值水平:
1
2
3
xs = torch.linspace(0.05,0.95,29)
accs = [accuracy_multi(preds, targs, thresh=i, sigmoid=False) for i in xs]
plt.plot(xs,accs);
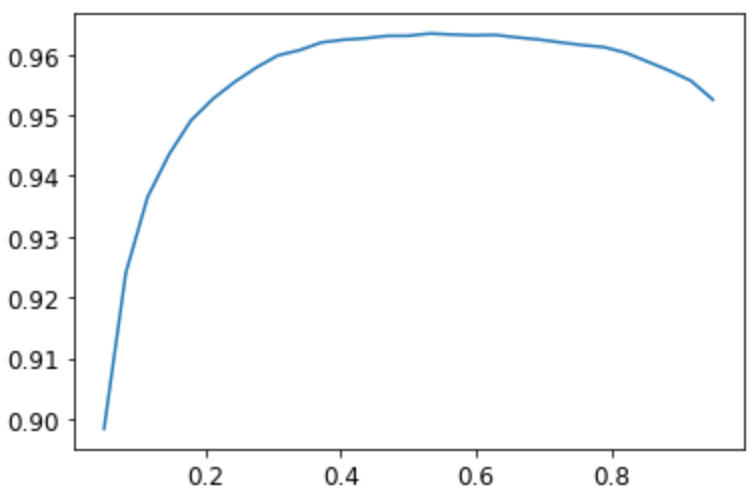
在这种情况下,我们使用验证集来选择超参数(阈值),这是验证集的目的。有时,学生会表示担心我们可能过拟合验证集,因为我们正在尝试许多值来查看哪个是最好的。然而,正如您在情节中看到的,在这种情况下,更改阈值会导致曲线平滑,因此我们显然不会选择一些不合适的异常值。这是一个很好的例子,说明你必须小心理论(不要尝试大量超参数值,否则你可能会过拟合验证集)和实践(如果关系是光滑的,那么这样做是可以的)。
本章中专门讨论多标签分类的部分到此结束。接下来,我们将看看回归问题。
Regression
人们很容易认为深度学习模型被归类为计算机视觉、NLP等领域。事实上,这就是fastai对其应用的分类方式。
但实际上,这隐藏着一个更有趣、更深刻的观点。模型由其独立变量和依赖变量及其损失函数定义。这意味着实际上,除了简单的基于域的拆分外,还有更广泛的模型阵列。也许我们有一个独立的变量,即图像,和一个依赖变量,即文本(例如,从图像生成文本);或者我们有一个独立的变量,即文本和依赖变量,即图像(例如,从文本生成图像——这实际上可以进行深度学习!);或者也许我们有图像、文本和表格数据作为独立变量,试图预测产品购买……可能性真的是无穷无尽的。
为了能够超越固定应用,为新问题制定自己的新解决方案,真正了解数据块API(也许还有中层API,我们将在本书后面看到)是有帮助的。例如,让我们考虑一下图像回归问题。这是指从独立变量为图像且依赖变量为一个或多个浮点数的数据集中学习。我们经常看到人们将图像回归视为一个完整的独立应用——但正如您将在这里看到的,我们可以将其视为数据块API之上的另一个CNN。
我们将直接跳转到一个有点棘手的图像回归变体。 我们将做一个关键点模型。关键点是指图像中代表的特定位置——在这种情况下,我们将使用人的图像,并在每张图像中寻找人的脸部中心。这意味着我们实际上将为每张图像预测两个值:脸部中心的行和列。
Assemble the Data
我们将在本节中使用Biwi Kinect Head Pose数据集。我们将像往常一样下载数据集:
1
path = untar_data(URLs.BIWI_HEAD_POSE)
1
2
#hide
Path.BASE_PATH = path
让我们看看我们得到了什么:
1
2
3
path.ls().sorted()
(#50) [Path('01'),Path('01.obj'),Path('02'),Path('02.obj'),Path('03'),Path('03.obj'),Path('04'),Path('04.obj'),Path('05'),Path('05.obj')...]
有24个目录编号从01到24(它们对应于拍摄的不同人),每个目录都有相应的.obj文件(我们在这里不需要它们)。让我们看看以下目录之一:
1
2
3
(path/'01').ls().sorted()
(#1000) [Path('01/depth.cal'),Path('01/frame_00003_pose.txt'),Path('01/frame_00003_rgb.jpg'),Path('01/frame_00004_pose.txt'),Path('01/frame_00004_rgb.jpg'),Path('01/frame_00005_pose.txt'),Path('01/frame_00005_rgb.jpg'),Path('01/frame_00006_pose.txt'),Path('01/frame_00006_rgb.jpg'),Path('01/frame_00007_pose.txt')...]
在子目录中,我们有不同的帧,每个帧都配有图像(_rgb.jpg)和一个姿势文件(_pose.txt)。我们可以使用get_image_files 轻松递归获取所有图像文件,然后编写一个函数,将图像文件名转换为其关联的姿势文件:
1
2
3
4
5
img_files = get_image_files(path)
def img2pose(x): return Path(f'{str(x)[:-7]}pose.txt')
img2pose(img_files[0])
Path('13/frame_00349_pose.txt')
让我们看一下第一章图像:
1
2
3
4
im = PILImage.create(img_files[0])
im.shape
(480, 640)
1
im.to_thumb(160)

Biwi数据集网站用于解释与每张图像关联的姿势文本文件的格式,该文件显示了头部中心的位置。这方面的细节对我们的目的来说并不重要,所以我们只展示我们用来提取头部中心点的功能:
1
2
3
4
5
6
cal = np.genfromtxt(path/'01'/'rgb.cal', skip_footer=6)
def get_ctr(f):
ctr = np.genfromtxt(img2pose(f), skip_header=3)
c1 = ctr[0] * cal[0][0]/ctr[2] + cal[0][2]
c2 = ctr[1] * cal[1][1]/ctr[2] + cal[1][2]
return tensor([c1,c2])
这个函数返回两个元素的张量作为坐标:
1
2
3
get_ctr(img_files[0])
tensor([384.6370, 259.4787])
我们将这个函数作为 DataBlock 作为 get_y 函数。 我们将调整图像的大小,使其输入大小减半,为了加快训练速度。
需要注意的一点是,我们不应该只使用随机 splitter。原因是同一人出现在此数据集中的多个图像中,但我们希望确保我们的模型可以推广到它尚未看到的人。数据集中的每个文件夹都包含一个人的图像。因此,我们可以创建一个 spliter 函数,仅为一个人返回true,从而生成一个仅包含该人图像的验证集。
与之前的数据块示例的唯一其他区别是,第二个块是 PointBlock 。这是必要的,这样fastai就知道标签代表坐标;这样,它知道在进行数据增强时,它应该对这些坐标进行与对图像相同的增强:
1
2
3
4
5
6
7
8
biwi = DataBlock(
blocks=(ImageBlock, PointBlock),
get_items=get_image_files,
get_y=get_ctr,
splitter=FuncSplitter(lambda o: o.parent.name=='13'),
batch_tfms=[*aug_transforms(size=(240,320)),
Normalize.from_stats(*imagenet_stats)]
)
在进行任何建模之前,我们应该查看我们的数据,以确认它是否正常:
1
2
dls = biwi.dataloaders(path)
dls.show_batch(max_n=9, figsize=(8,6))

除了直观地查看 batch 外,最好也查看底层张量(特别是作为学生;这将有助于您理解模型真正看到的内容):
1
2
3
4
xb,yb = dls.one_batch()
xb.shape,yb.shape
(torch.Size([64, 3, 240, 320]), torch.Size([64, 1, 2]))
以下是从依赖变量中一行的示例:
1
2
3
yb[0]
TensorPoint([[-0.3375, 0.2193]], device='cuda:6')
如您所见,我们不用使用单独的图像回归应用;我们只需要标记数据,并告诉 fastai 独立变量和依赖变量代表哪些类型的数据。
Training a Model
像往常一样,我们可以使用 cnn_learner 来创建我们的 Learner。还记得我们如何使用 y_range 来告诉fastai 我们目标的范围吗?我们在这里也会这样做(fastai 和 PyTorch 的坐标总是在-1到+1之间重新缩放):
1
learn = cnn_learner(dls, resnet18, y_range=(-1,1))
y_range 在 fastai 中使用 sigmoid_range, 其定义如下:
1
def sigmoid_range(x, lo, hi): return torch.sigmoid(x) * (hi-lo) + lo
如果定义了 y_range,则其设置为模型的最终层。花点时间思考一下这个函数的作用,以及它为什么强制模型在 ( o,hi) 范围内输出激活。
它看起来是这样的:
1
plot_function(partial(sigmoid_range,lo=-1,hi=1), min=-4, max=4)
我们没有指定损失函数,这意味着我们使用了 fastai 选择的默认函数。让我们看看它为我们挑选了什么:
1
2
3
dls.loss_func
FlattenedLoss of MSELoss()
这是有道理的,因为当坐标用作依赖变量时,大多数时候我们可能会试图预测尽可能接近的东西;这基本上是MSELoss(均方误差损失)的作用。如果您想使用其他丢失函数,您可以使用 loss_func 参数将其传递给 cnn_learner。
另请注意,我们没有指定任何指标。这是因为MSE已经是这项任务的一个有用指标(尽管在我们采取平方根后,它可能更容易解释)。
我们可以通过学习率查找器选择一个好的学习率:
1
2
3
learn.lr_find()
SuggestedLRs(lr_min=0.005754399299621582, lr_steep=0.033113110810518265)
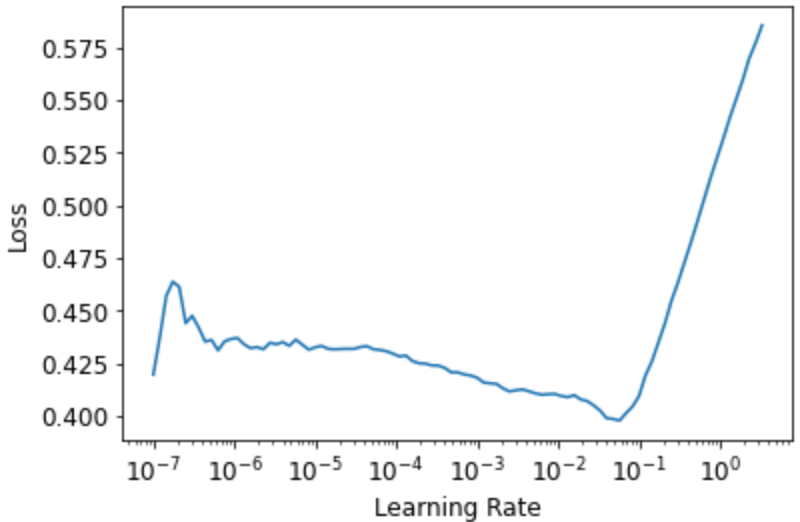
我们尝试 LR 为 1e-2:
1
2
lr = 1e-2
learn.fine_tune(3, lr)
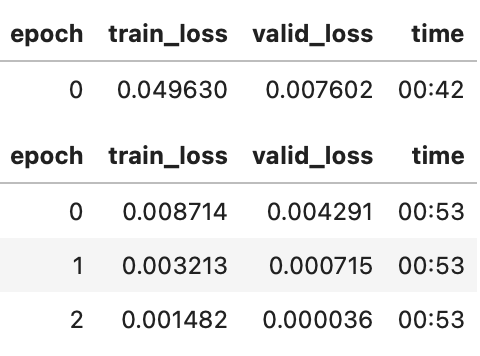
通常,当我们运行这个时,我们会得到大约0.0001的损失,这与以下的平均坐标预测错误相对应:
1
2
3
math.sqrt(0.0001)
0.01
这听起来非常准确!但使用 Learner.show_results 查看我们的结果很重要。左侧是实际(地面真相)坐标,右侧是我们模型的预测:
1
learn.show_results(ds_idx=1, nrows=3, figsize=(6,8))

令人惊讶的是,只需几分钟的计算,我们就创建了这样一个准确的关键点模型,并且没有任何特定的特定领域应用。这是构建灵活的API和使用迁移学习的力量!特别引人注目的是,即使在完全不同的任务之间,我们也能如此有效地使用迁移学习;我们的预训练模型被训练来进行图像分类,并为图像回归进行了微调。
Conclusion
在乍一看完全不同的问题(单标签分类、多标签分类和回归)中,我们最终使用输出数量不同的相同模型。损失函数是改变的一件事,这就是为什么再次检查您是否对问题使用了正确的损失函数很重要。
fastai 将自动尝试从您构建的数据中选择正确的数据,但如果您使用纯PyTorch构建 DataLoader,请确保在必须决定损失函数的选择时仔细思考,并记住您可能想要:
nn.CrossEntropyLoss用于单标签分类nn.BCEWithLogitsLoss用于多标签分类nn.MSELoss用于回归
-
Previous
【深度学习】SR3:Image Super-Resolution via Iterative Refinement -
Next
【深度学习】Towards VQA Models That Can Read