在机器学习中,性能度量是一项必不可少的任务。所以当涉及到分类问题时,我们可以依靠AUC - ROC曲线。当我们需要检查或可视化多类分类问题的性能时,我们使用AUC (Area Under the Curve) ROC (Receiver Operating Characteristics)曲线。它是检验任何分类模型性能最重要的评价指标之一。也可以写成AUROC (Area Under the Receiver Operating Characteristics)。
本博客旨在回答以下问题:
- AUC - ROC曲线是什么?
- 定义AUC和ROC曲线使用的术语。
- 如何推测模型的性能?
- 敏感性(Sensitivity)、特异性(Specificity)、FPR和阈值的关系。
- multiclass 模型如何使用 AUC - ROC 曲线
What is the AUC - ROC Curve?
AUC - ROC曲线是对不同阈值设置下的分类问题的性能度量。ROC是概率曲线,AUC表示可分性的程度或测度。它告诉模型能够在多大程度上区分类。AUC越高,模型越能预测0类为0,1类为1。由此类推,AUC越高,该模型越能区分患者是否有疾病。
ROC曲线用 TPR 和 FPR 绘制,其中 TPR 在 y 轴上,FPR 在 x 轴上。
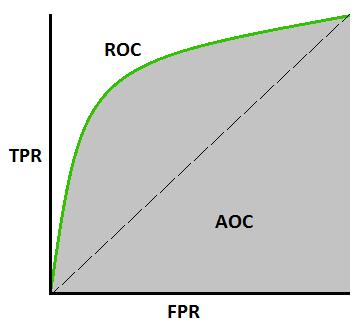
定义在 AUC and ROC Curve 中使用的术语
TPR (True Positive Rate) / Recall /Sensitivity
\[TPR/Recall/Sensitivity = \frac{TP}{TP + FN}\]Specificity
\[Specificity = \frac{TN}{TN + FP}\]FPR
\[FPR = 1 - Specificity = \frac{FP}{TN + FP}\]如何推测模型的性能?
一个优秀的模型的AUC接近于1,这意味着它具有很好的可分性。差的模型的AUC接近于0,这意味着它的可分性最差。事实上,这意味着它是对结果的回报。它把 0 看成 1,把 1 看成 0。当AUC为 0.5 时,表示该模型完全没有分类能力。
让我们来解释一下上面的陈述。
我们知道,ROC是一条概率曲线。让我们画出这些概率的分布。
注:红色分布曲线为 positive class (有疾病),绿色分布曲线为 negative class (无疾病)。
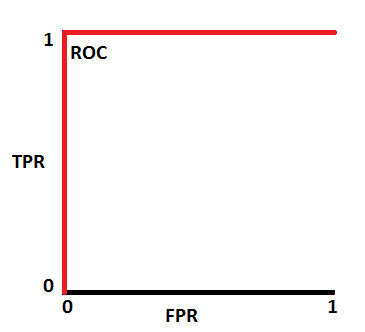
这是一个理想的情况。当两条曲线完全不重叠时,均值模型具有理想的可分性测度。它完全能够区分 positive class 和 negative class。
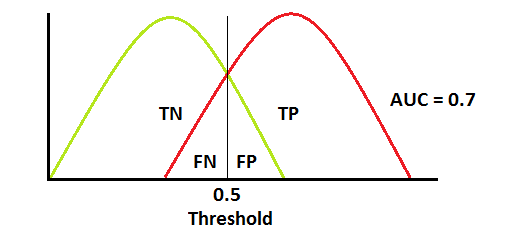
当两个分布重叠时,我们引入 type 1 和 type 2 错误。根据阈值,我们可以使它们最小化或最大化。当AUC 为 0.7时,意味着模型能够区分正类和负类的几率为70%。
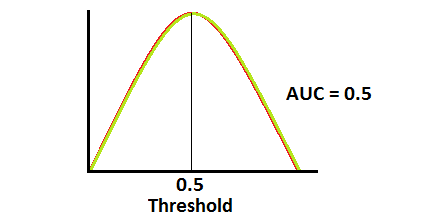
当AUC约为0.5时,模型没有区分正类和负类的能力。这是最糟糕的情况。
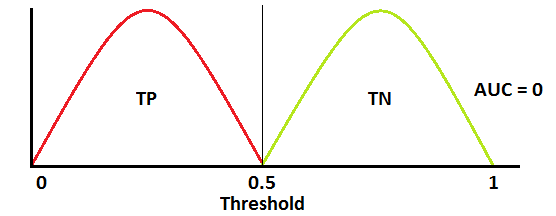
当AUC近似为0时,模型实际上是在对类进行互换操作。这意味着这个模型预测了一个 negative class 会变成 positive class,反之亦然。
敏感性(Sensitivity)、特异性(Specificity)、FPR和阈值(Threshold)的关系。
敏感性(Sensitivity)和特异性(Specificity)成反比。所以当我们提高灵敏度时,特异性就会降低,反之亦然。

当我们降低阈值时,我们得到更多的正值,从而提高了敏感性,降低了特异性。
同样,当我们提高阈值时,我们得到更多的负值,因此我们得到更高的特异性和更低的敏感性。
我们知道 FPR 是 1 - specificity。所以当我们增加 TPR 时,FPR 也会增加,反之亦然。

multi-class 模型如何使用AUC ROC曲线?
在 multi-class 模型中,我们可以使用 One vs ALL 方法绘制 N 个类的 N 条 AUC ROC 曲线。例如,如果你有三个类别,分别叫做 X, Y,和 Z,你将有一个 X classified against Y and Z 的 ROC,另一个 Y classified against X and Z 的 ROC,和第三个 Z classified against Y and X 的 ROC。