Abstract
目标检测是计算机视觉的一个重要领域,在各种实际场景中发挥着关键作用。
在实际应用中,由于硬件的限制,常常需要牺牲精度来保证检测器的推理速度。
因此,必须考虑目标检测器的有效性和效率之间的平衡。
这篇文章的目标不是提出一种新的检测模型,而是实现一种有效性和效率相对均衡的、可以直接应用于实际应用场景的目标检测器。
考虑到YOLOv3在实际应用中的广泛应用,作者开发了一种新的基于YOLOv3的目标检测器。
作者主要尝试结合现有的各种几乎不增加模型参数和FLOPs数量的技巧,在保证速度基本不变的情况下,尽可能提高检测器的精度。
由于这篇文章所有的实验都是基于PaddlePaddle进行的,所以称之为PP-YOLO。
PP-YOLO通过多种技巧的结合,可以在准确率(45.2% mAP)和速度(72.9 FPS)之间取得更好的平衡,超过了现有的最先进的检测器effentdet和YOLOv4。
Method
one-stage anchor-based 检测器通常由 backbone、detection neck(典型的特征金字塔网络,FPN)和用于目标分类和定位的detection head 组成。它们也是大多数基于 anchor-point 的 one-stage anchor-free 检测器中常见的组件。这篇文章首先对YOLOv3的详细结构进行了修改,其将 backbone 替换为 ResNet50-vd-dcn, 将其作为这篇文章的 baseline。然后作者引入了一堆可以几乎不损失效率的技巧来提高YOLOv3的性能。
Architecture
Backbone YOLOv3的整体架构如图2所示。作者将 backbone DrakNet-53 替换为 ResNet50-vd。将DarkNet-53 替换为 ResNet50-vd 会损害 YOLOv3 检测器的性能。 作者将ResNet50-vd中的部分卷积层替换为可形变卷积层。 可形变卷积网络(Deformable convolutional Networks, DCN)的有效性已经在许多检测模型中得到了验证。DCN 本身不会显著增加模型的参数量和 FLOPs, 但是实际上太多的 DCN 层将会大大增加推理时间。 因此,为了平衡效率和有效性,我们只在最后的 stage 用DCNs替换 $3 \times 3$ 卷积层。作者将这种修改后的 backbone 叫做 ResNet50-vd-dc, stage 3,4,5 的输出表示为 $C_3, C_4, C_5$。
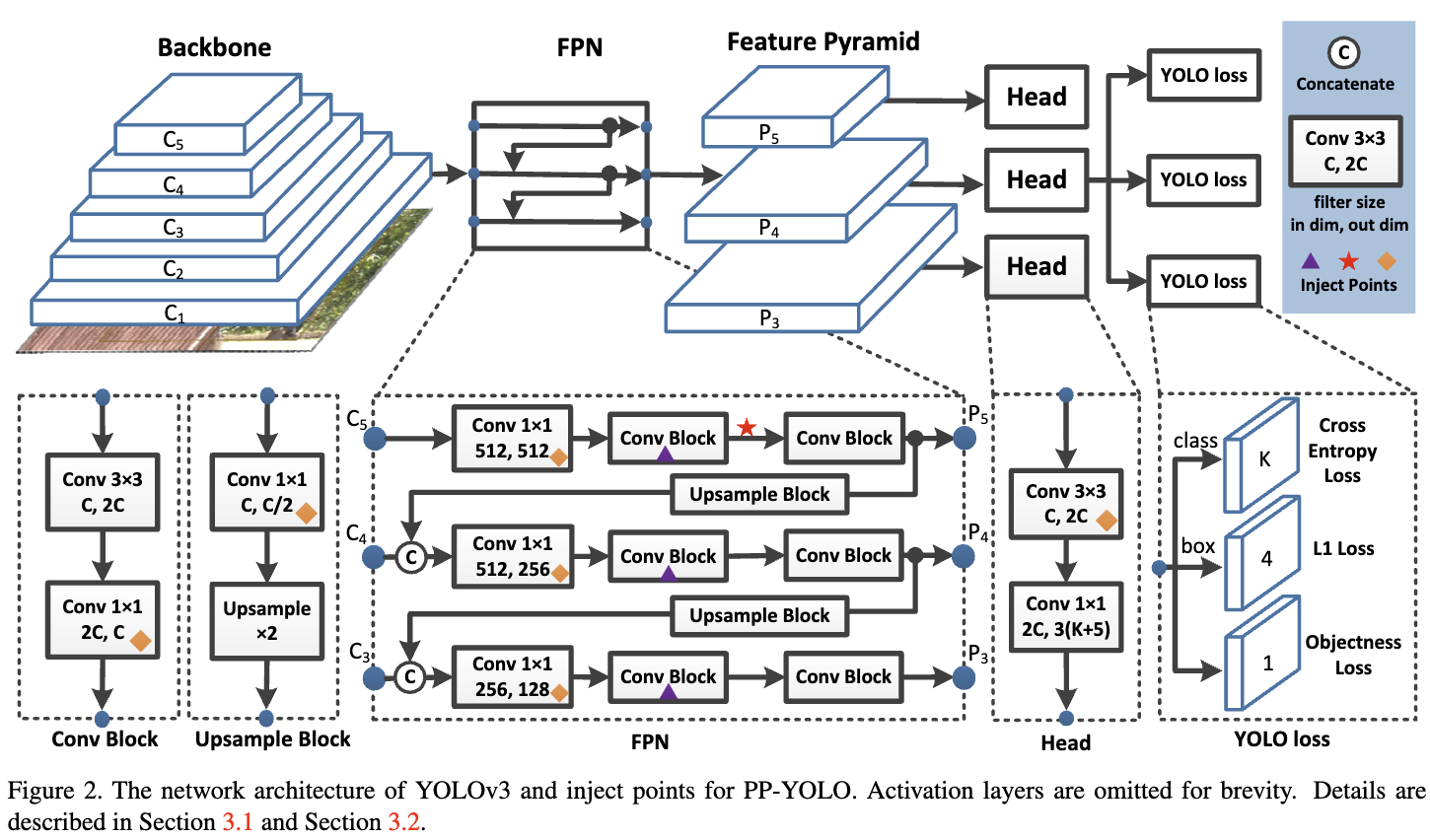
Detection Neck 然后使用FPN[21]构建特征映射之间横向连接的特征金字塔。特征图 $C_3, C_4, C_5$ 输入 FPN 模块。作者将金字塔层次 $l$ 的输出特征映射记为 $P_l$,在作者的实验中,$l = 3,4,5$。 对于尺寸为 $W \times H$ 的输入图像,$P_l$ 的分辨率为 $\frac{W}{2^l} \times \frac{H}{2^l}$。FPN的详细结构如图2所示。
Detection Head YOLOv3的检测头非常简单。它由两个卷积层组成。采用一个 $3 \times 3$ 卷积层和 $1 \times 1$ 卷积层得到最终的预测结果。每个最终预测的输出通道为 $3(K + 5)$,其中 $K$ 为类的数量。每个最终 prediction map 上的每个位置都与三个不同的 anchors 相关联。对于每个 anchor,前 $K$ 个通道是 $K$ 类的概率预测。后面4个通道是 bbox 定位的预测。最后一个通道是 objectness score 的预测。分类和定位时,分别采用交叉熵损失和L1损失。jectness loss[32]用于监督objectness score,用于判断是否存在目标。
Selection of Tricks
本节将介绍这篇文章中使用的各种技巧。这些技巧都是已经存在的,来自于不同的工作[10,1,42,39,38,25,12]。 这篇文章并没有提出一种新的检测方法,只是着重于结合现有的技巧来实现一种高效有效的检测器。由于许多技巧不能直接应用于YOLOv3,因此需要根据YOLOv3的结构进行调整。
Larger Batch Size 使用更大的批大小可以提高训练的稳定性,获得更好的结果。作者将训练的 batch size 从 64 调整为 192, 并且调整 training schedule 和 learning rate。
EMA 当训练一个模型时,保持训练参数的 moving averages 通常是有益的。使用平均参数的计算有时会产生明显优于最终训练值[35]的结果。指数移动平均(EMA)利用指数衰减计算训练参数的 moving averages 。对于每个参数W,维护一个 shadow 参数:
\(W_{EMA} = \lambda W_{EMA} + (1 - \lambda) W \tag{1}\) DropBlock DropBlock 是结构化 dropout 的一种形式, 在一个特征图的连续区域中的单元被放到一起。与原文不同的是,作者只在FPN上使用DropBlock,因为发现在 Backbone 上添加 DropBlock 会导致性能下降。DropBlock的详细注入点由图2中的三角形标记。
IoU Loss 边界框回归是目标检测的关键步骤。在YOLOv3中,采用 L1 损失进行bound-box regression。它不是为mAP评估指标量身定制的,而mAP高度依赖于Intersection over Union (IoU)。IoU损失以及CIoU损失和GIoU损失[46,34]等其他变体已经被提出来解决这个问题。与 yolov4 不同的是,作者没有直接用 IoU loss 替换 L1 loss,作者增加了另一个分支来计算IoU loss。作者发现各种 IoU loss 的改进都是相似的,所以我们选择了最基本的IoU loss [42]。
IoU Aware 在YOLOv3中,分类概率和 objectness score 相乘作为最终检测置信度,不考虑定位精度。为了解决这一问题,增加了一个IoU预测分支来衡量定位的准确性。在训练中,采用IoU aware loss 的方法对 IoU 预测分支进行训练。在推理过程中,将预测的IoU乘以分类概率和 objectiveness score,计算出最终的检测置信度,这与定位精度的相关度更高。然后将最终的检测置信度作为后续NMS的输入。 IoU aware 分支只有0.01%的参数数量和0.0001%的 FLOPs 增加,这几乎可以忽略。
Grid Sensitive Grid Sensitive 是 YOLOv4 引入的一个有效技巧。当我们解码 bbox 中心 x 和 y 的坐标时,在原始的YOLOv3中,我们可以通过
\(x = s · (g_x + \sigma(p_x)) \tag{2}\) \(y = s · (g_y + \sigma(p_y)) \tag{3}\)
其中 $\sigma$ 是 sigmoid 函数, $g_x$ 和 $g_y$是整数, $s$ 是 scale factor。显然, $x$ 和 $y$ 不能正好等于 $s · g_x$ 或 $s · (g_x + 1)$。 这使得预测 bbox 的中心很困难。 为了解决这个问题, 将等式改为:
\(x = s · (g_x + \alpha · \sigma(p_x) - (\alpha - 1)/2) \tag{4}\) \(y = s · (g_y + \alpha · \sigma(p_y) - (\alpha - 1)/2) \tag{5}\) 在文章中 $\alpha$ 被设为 1.05。这使得模型更容易预测边界框中心在网格边界上的准确位置。
Matrix NMS Matrix NMS 受启发于 Soft-NMS。但是,该过程与传统的Greedy NMS一样是顺序的,不能并行实现。Matrix NMS从另一个角度看待这个过程,并以并行的方式实现。 因此,Matrix NMS 比传统 NMS 速度更快,不会带来效率的损失。
CoordConv CoordConv,它的工作原理是通过使用额外的坐标通道来提供对自己的输入坐标的卷积访问。CoordConv 允许网络同时学习 complete translation invariance 和 varying degrees of translation dependence。 由于 CoordConv 会在卷积层增加两个输入通道,所以会增加一些参数和FLOPs。为了尽可能减少效率的损失,作者不改变 backbone 中的卷积层,只替换FPN中的1x1卷积层和 detection head 中的第一个卷积层。CoordConv的详细注入点在图2中被菱形标记。
SPP 空间金字塔池化(SPP)是由He等人首先提出的。 YOLOv4通过将最大池化输出与 kernel size $k \times k$ concatenating 起来应用SPP模块,其中 $k = {1, 5, 9, 13}$, stride等于1。在这种设计下,一个相对较大的 $k \times k$ max-pooling 可以有效地增加 backbone 特征的感受野。 SPP仅应用于图2中带星号的顶部feature map。SPP本身不引入参数,但会增加后面卷积层的输入通道数。因此,大约额外引入2%的参数和1%额外的FLOPs。
Better Pretrain Model 在ImageNet上使用分类精度更高的预训练模型可以获得更好的检测性能。这里作者使用蒸馏的ResNet50-vd模型作为预训练模型[29]。
Conclusion
这篇文章介绍了一种基于PaddlePaddle的目标检测器的新实现——PP-YOLO。
PP-YOLO比其他先进的检测器(如effentdet和YOLOv4)更快(FPS)和更准确(COCO mAP)。
这篇文章探索了许多技巧,并展示了如何在YOLOv3检测器上组合这些技巧,并演示了它们的有效性。