Abstract
这篇文章提出的YOLO9000是一款最先进的实时物体检测系统,可以检测9000多种物体类别。
首先,作者对YOLO检测方法提出了各种改进,既有新提出的也有借鉴了之前的工作。
改进后的模型YOLOv2在PASCAL VOC和COCO等标准检测任务上是最先进的。
作者采用了一种新的多尺度训练方法,同样的YOLOv2模型可以在不同的尺寸下运行,在速度和精度之间提供了一种简单的权衡。
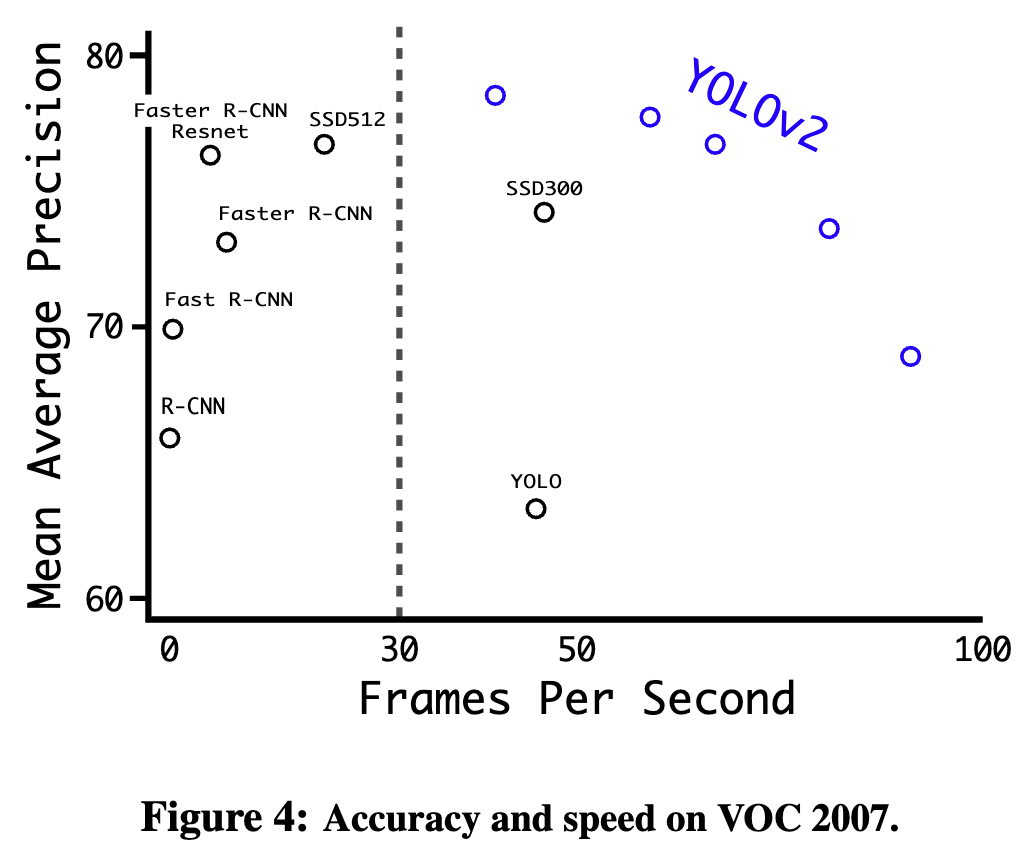
在67帧/秒的情况下,YOLOv2在VOC 2007上获得了76.8的mAP。
在40帧/秒的情况下,YOLOv2获得了78.6的mAP,比使用ResNet的Faster R-CNN和SSD等最先进的方法表现得更好,同时仍然运行得更快。
最后提出了一种目标检测与分类的联合训练方法。
利用该方法,作者在COCO检测数据集和ImageNet分类数据集上同时训练YOLO9000。
作者的联合训练允许YOLO9000预测没有标记物体类别的检测数据的检测。
作者在ImageNet检测任务上验证了该方法。
YOLO9000在ImageNet检测验证集上获得19.7 的mAP,尽管只有检测数据200个类中的44个类。
不在COCO的156个类别中,YOLO9000获得了16.0 mAP。
YOLO可以检测到的类别不止200个; 它预测了9000多种不同物体类别的检测结果。
Better
相对于最先进的检测系统,YOLO存在各种缺点。YOLO与Fast R-CNN的误差分析表明,YOLO产生了大量的定位错误。此外,与基于区域建议的方法相比,YOLO的召回率相对较低。因此,作者主要关注提高召回率和定位,同时保持分类准确性。
计算机视觉一般倾向于更大、更深的网络。更好的表现往往取决于训练更大的网络或集成多个模型。但是,YOLOv2需要一个更精确、速度更快的检测器。作者没有扩大网络,而是简化网络,然后使表示更容易学习。作者从过去的工作中汇集了各种想法,并结合作者的新概念来改善YOLO的表现。结果总结见表2。
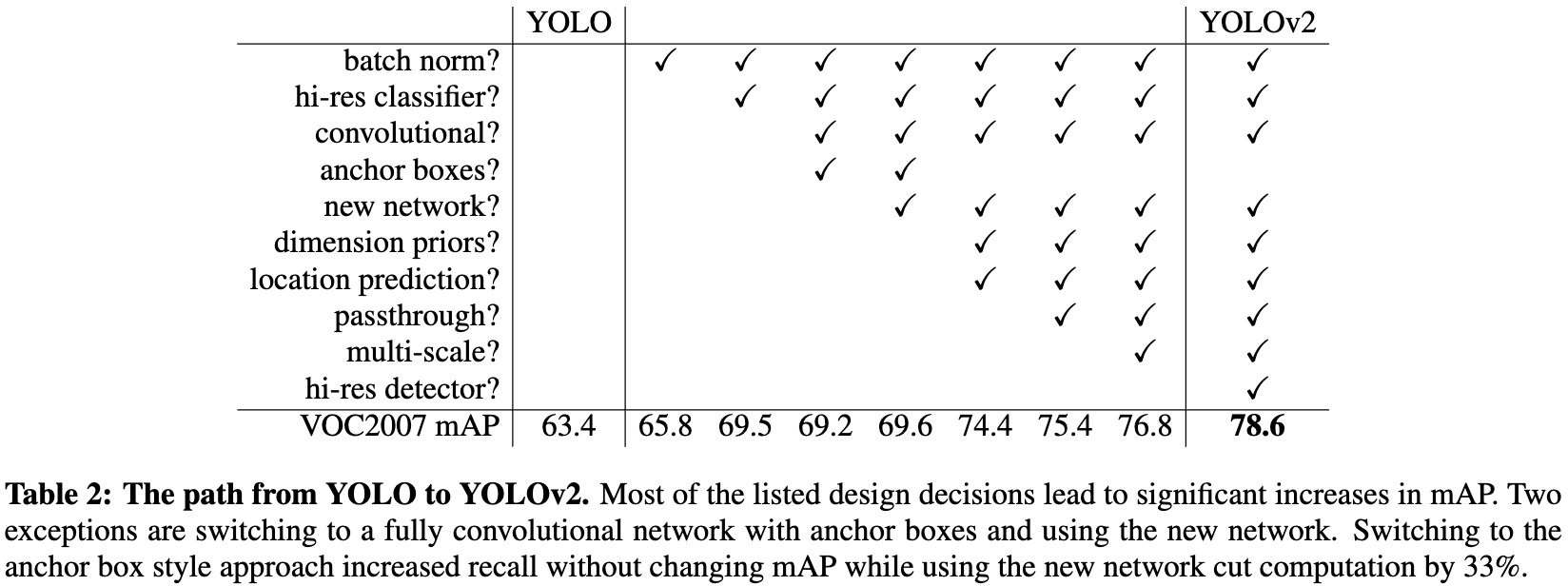
Batch Normalization. BN使收敛方面显著改进,同时消除了对其他形式的正则化[7]的需要。 通过在YOLO中对所有卷积层添加 BN,作者在mAP中获得了超过2%的改进。BN还有助于对模型进行正则化。通过 BN,我们可以在不过拟合的情况下移除模型的 Dropout。
High Resolution Classifier. 所有最先进的检测方法都使用在ImageNet上预先训练的分类器。从AlexNet开始,大多数分类器对小于 $256 \times 256$ [8]的输入图像进行操作。原始YOLO在 $224 \times 224$ 训练分类器网络,将分辨率提高到 $448$ 进行检测。这意味着网络同时切换到学习目标检测和调整到新的输入分辨率。
对于YOLOv2,作者首先在ImageNet上以完整的 $448 \times 448$ 分辨率对分类网络进行了10个epoch的微调。这给了网络时间来调整它的 filter,以更好地工作在更高分辨率的输入。然后,作者在产生的网络上微调检测。这个高分辨率的分类网络使mAP增加了近4%。
Convolutional With Anchor Boxes. YOLO在卷积特征提取器上直接使用全连接层来预测 bbox 的坐标。相比于直接预测坐标, Faster R-CNN使用精心挑选的先验[15]来预测 bbox。Faster R-CNN中的区域建议网络(RPN)仅通过卷积层来预测 Anchor 的偏移量和置信度。由于预测层是卷积的,RPN在特征图的每个位置预测这些偏移。预测偏移量而不是坐标简化了问题,使网络更容易学习。
作者从YOLO中移除全连接的层,并使用 Anchor 来预测 bbox。首先,作者移除了一个池化层,使网络卷积层的输出具有更高的分辨率。作者还缩小了网络来操作 $416$ 的输入图像,而不是 $448 \times 448$ 。这样做是因为作者想要在特征图中有奇数个位置,所以只有一个中心 center cell。特别是大型物体会占据图像的中心,因此,预测这些物体的位置最好是在图像中心,而不是在附近的4个位置。YOLO的卷积层对图像进行了32倍的下采样,因此通过使用416的输入图像,得到了 $13 \times 13$ 的输出特征图。
当作者转向 Anchor boxes 时,也将 class prediction 机制与空间位置解耦,取而代之的是预测每个 Anchor 的 class 和 objectness。和 YOLO 一样,objectness prediction 仍然预测真值和预测框的IOU,class prediction 预测给定物体存在的类条件概率。使用 Anchor,导致一个小的下降的准确性。YOLO只能预测每张图片有98个框,但通过 Anchor,模型可以预测超过1000个。没有Anchor,模型得到69.5的mAP,召回率为81%。通过 Anchor boxes,模型获得69.2 的 mAP,召回率为88%。尽管mAP下降,但召回率的增加意味着模型有更多的改进空间。
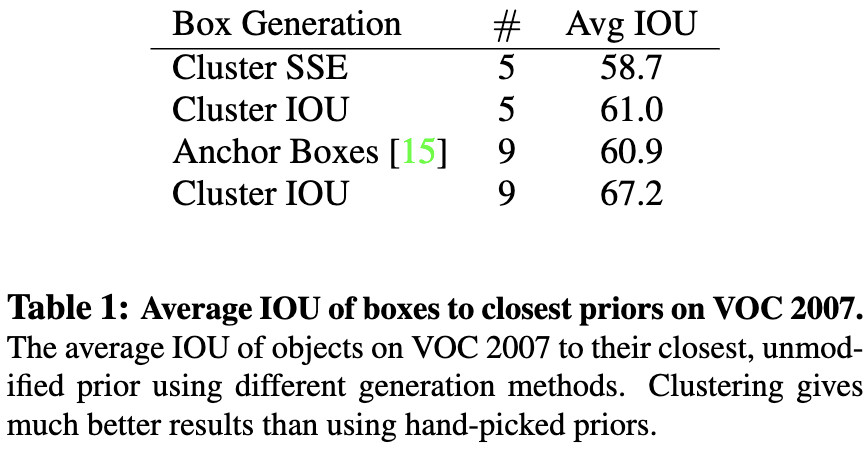
Dimension Clusters. 在YOLO中使用 Anchor boxes 时,会遇到两个问题。首先,box 尺寸是手工挑选的。网络可以学会适当地调整 boxes,但如果为网络选择更好的先验,可以让网络更容易地学习预测好的检测。
作者不再手工选择先验,而是对训练集的边界框进行k-均值聚类,以自动生成先验。 如果我们使用欧几里得距离的标准k-均值,大 box 比 小box 产生更多的误差。然而,真正想要的是导致良好的IOU分数的先验,这与 box 的大小无关。因此,作者使用以下距离度量:
\[d(\text{box, centroid}) = 1 - \text{IOU}(\text{box, centroid})\]作者对k的不同值运行k-means,并绘制最接近质心的IOU,见图2。作者选择 $k = 5$ 作为模型复杂度和高召回率之间的一个很好的权衡。聚类中心与手工挑选的 Anchor boxes 有显著不同。
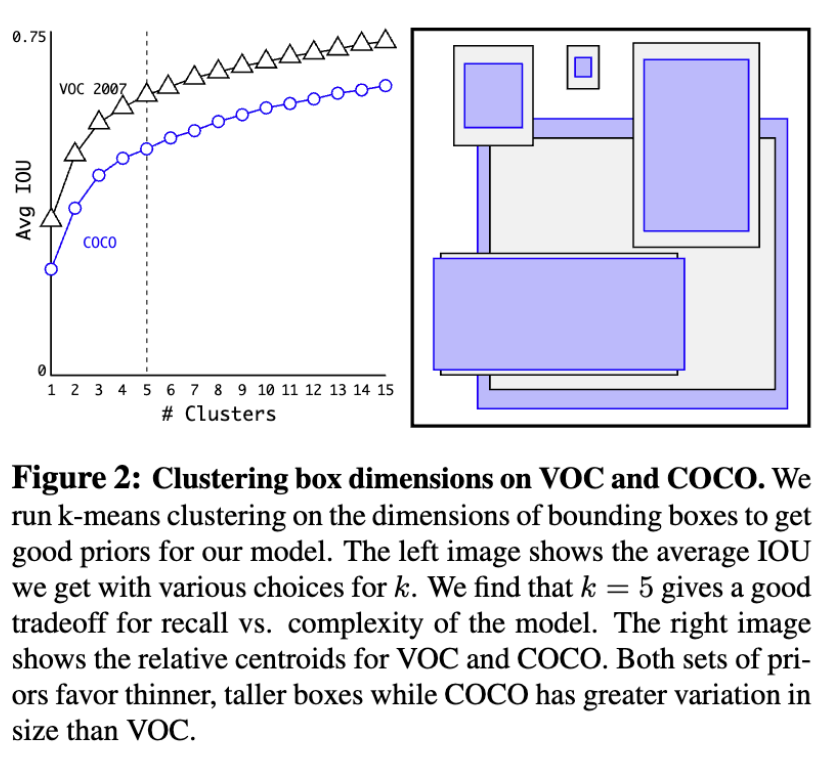
作者将平均IOU与聚类策略和精心挑选的 Anchor boxes 进行比较, 如表1。 在只有5个先验的中心表现类似于9个 Anchor。如果使用9个Anchor,会看到一个更高的平均 IOU。这表明使用k-means来生成 bbox 可以使模型有一个更好的表示,使任务更容易学习。
Direct location prediction. 当使用 Anchor 时,会遇到第二个问题:模型不稳定,特别是在早期迭代期间。大部分的不稳定性来自于预测 box 的 $(x, y)$ 位置。在区域提议网络中,网络预测值$t_x$ 和 $t_y$ 和 $(x, y)$ 中心坐标计算为:
\[x = (t_x * w_a) + x_a \\ y = (t_y * h_a) + y_a\]如果预测 $t_x = 1$,则会将方框向右移动固定方框的宽度。 $t_x = -1$ 将 box 向左移动相同的距离。
这个公式是不受约束的,所以任何 anchor box 都可以在图像中的任何一点,不管哪个位置预测了这个框。在随机初始化的情况下,模型需要很长时间才能稳定到预测合理的偏移量。
作者不预测偏移量,而是遵循YOLO的方法,预测相对于 grid cell 位置的位置坐标。这将真值限定在0和1之间。作者使用 logistic 激活来约束网络的预测落在这个范围内。
该网络在每个 cell 预测输出特征图中的5个 bbox。网络每个bbox预测5个值 $t_x、t_y、t_w、t_h$ 和 $t_o$ 。如果 cell 从图像的左上角偏移$(c_x, c_y)$,并且边界框先验的宽度和高度为 $p_w, p_h$,那么预测对应于:
\[b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y \\ b_w = p_w e^{t_w} \\ b_h = p_h e^{t_h} \\ Pr(\text{object}) * IOU(b, \text{object}) = \sigma(t_o)\]由于作者对位置预测进行了约束,使得参数化更加容易学习,使得网络更加稳定。使用直接预测 bbox 中心位置的维度聚类比使用 Anchor boxes 版本的 YOLO 提高了近5%。
Fine-Grained Features. 改进后的YOLO预测 $13 \times 13$特征图上的检测结果。虽然这对于大型物体来说已经足够了,但定位较小物体可能受益于细粒度特征。Faster R-CNN和SSD都在网络中的各种特征图上运行它们的提议网络,以获得一系列的分辨率。作者采用了不同的方法,简单地添加一个 passthrough 层,将之前 $26 \times 26$ 分辨率层的特征带来。
passthrough 层通过将相邻的特征叠加到不同的通道而不是空间位置,将高分辨率特征与低分辨率特征 concate 起来,类似于ResNet中的 identity 映射。这使得 $26 \times 26 \times 512$ 的特征图变为 $13 \times 13 \times 2048$ 的特征图。检测器运行在这个扩展的特征映射之上,因此它可以访问细粒度的特征。这将使性能略微提高1%。
Multi-Scale Training. 原始YOLO使用的输入分辨率为$448 \times 448$。随着 Anchor boxes 的引入,作者将分辨率改为 $416 \times 416$。然而,由于模型只使用卷积层和池化层,所以可以动态地调整大小。作者希望YOLOv2能够在不同大小的图像上运行,所以我们把它训练到模型中。
作者每隔几次迭代就改变网络的输入图像大小,而不是固定输入图像的大小。因为模型的下采样倍数为32, 作者从32的倍数采样 ${320, 352, …, 608}$。因此最小的选项是 $320 \times 320$,最大的选项是 $608 \times 608$。根据这个维度调整网络的大小,并继续训练。
这种机制迫使网络学习跨各种输入维度进行良好的预测。这意味着同一个网络可以在不同的分辨率下预测检测结果。网络在较小的尺寸下运行速度更快,因此YOLOv2可以轻松地在速度和精度之间进行权衡。
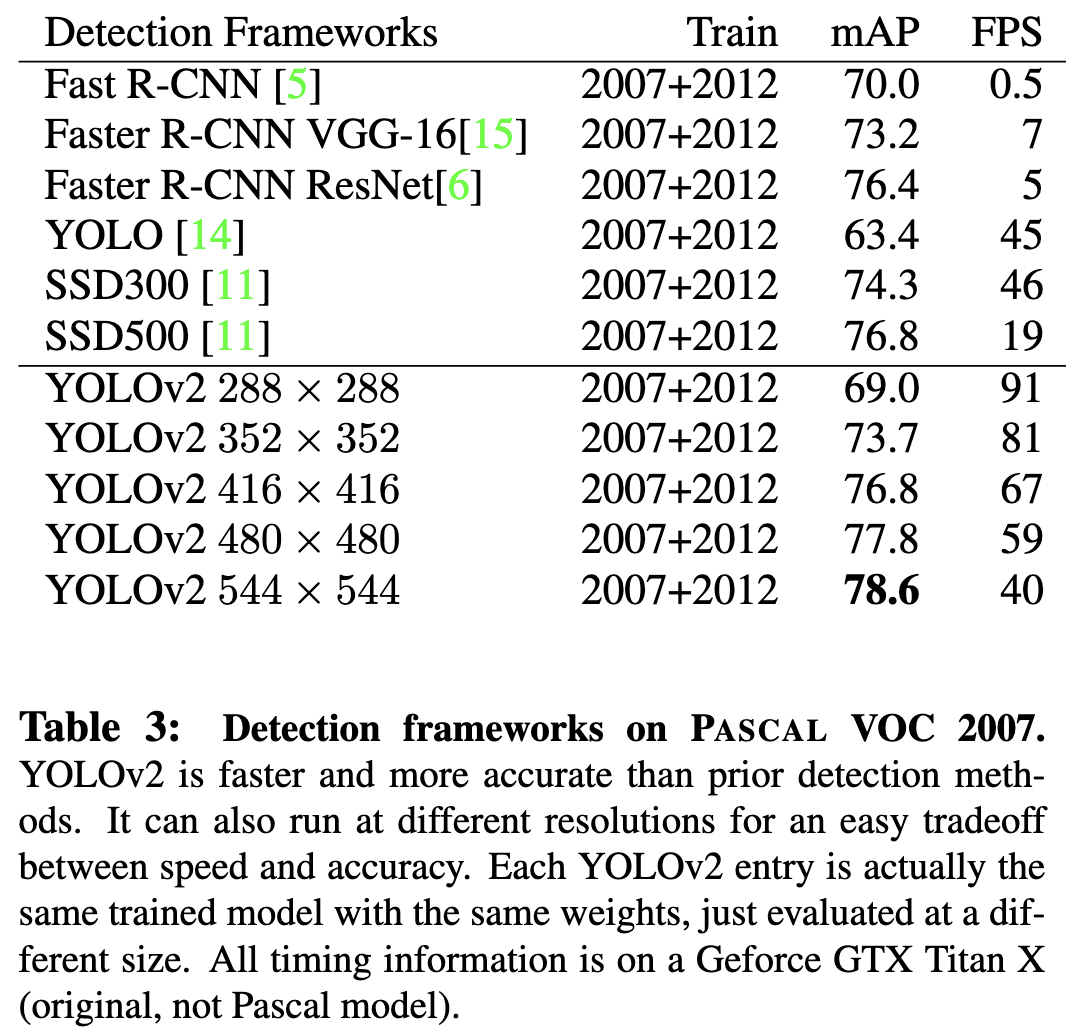
在低分辨率下,YOLOv2是一种廉价而相当精确的检测器。在 $288 \times 288$时,它的帧数超过90帧,mAP 几乎和Fast R-CNN一样好。这使得它非常适合更小的gpu、高帧率视频或多个视频流。
在高分辨率下,YOLOv2是一种最先进的检测器,在VOC上具有78.6 mAP,同时仍然高于实时速度。表3展示了在 VOC 2007 上不同框架的表现。
Faster
Stronger
Conclusion
这篇文章介绍了实时检测系统YOLOv2和YOLO9000。YOLOv2是最先进的,并且比跨各种检测数据集的其他检测系统更快。此外,它可以运行在各种大小的图像,以提供一个的速度和准确性的权衡。
YOLO9000是一个通过联合优化检测和分类,实现9000多个物体类别检测的实时框架。作者使用WordTree来组合来自不同来源的数据,并使用联合优化技术在ImageNet和COCO上同时训练。YOLO9000是缩小检测和分类之间数据集大小差距的有力一步。
作者的许多技术都可以推广到物体检测之外。ImageNet的WordTree表示为图像分类提供了更丰富、更详细的输出空间。采用分层分类方法对数据集进行组合,在分类和分割领域具有一定的应用价值。像多尺度训练这样的训练技术可以为各种视觉任务提供好处。
在未来的工作中,作者希望使用类似的技术进行弱监督图像分割。作者还计划在训练过程中使用更强大的匹配策略来为分类数据分配弱标签,以改进检测结果。计算机视觉有幸拥有大量的标记数据。作者将继续寻找方法,将不同的数据源和数据结构结合在一起,以创建更强大的视觉世界的模型。
-
Previous
【深度学习】YOLO Series Survey -
Next
【深度学习】You Only Look Once(YOLO V1): Unified, Real-Time Object Detection