Abstract
作者提出了一种新的目标检测方法YOLO。先前的目标检测工作将分类器重用于检测。这篇文章将目标检测定义为空间分离的bbox和相关的类概率的回归问题。在一次评估中,单个神经网络直接从完整图像预测 bbox 和类概率。由于整个检测 pipeline 是一个单一的网络,因此可以在检测性能上直接进行端到端优化。
base YOLO模型以每秒45帧的速度实时处理图像。网络的一个小版本,Fast YOLO,处理速度惊人的155帧每秒,同时仍然实现了两倍于其他实时探测器的mAP。与最先进的检测系统相比,YOLO产生更多的定位错误,但更不可能预测背景误报。 最后,YOLO学习目标的一般表示。
Unified Detection
作者将目标检测的独立组件统一为一个单一的神经网络。该网络使用来自整个图像的特征来预测每个边界框。它还可以同时预测一个图像的所有类的所有边界框。这意味着该网络对整个图像和图像中的所有目标进行全局分析。YOLO设计可以实现端到端训练和实时速度,同时保持较高的平均精度。
YOLO 将输入图像划分为一个 $S \times S$ 网格。如果一个目标的中心落在一个 grid cell 中,该 grid cell 负责检测该目标。
每个 grid cell 预测 $B$ 个 bbox 和这些框的置信度得分。这些置信度得分反映了模型对 box 包含一个目标的置信度,以及它认为它所预测的 box 有多准确。作者将置信度定义为 $\text{Pr(Object)} * \text{IOU}_{pred}^{truth}$。如果该 cell 中不存在目标,置信度得分应该为零。否则,作者希望置信度得分等于预测框与真实值之间的交集(IOU)。
每个边界框包含5个预测: $x、y、w、h$ 和 confidence 。$(x, y)$ 表示 box center 相对于 grid cell 边界的坐标。预测的宽度和高度相对于整个图像。最后置信度预测表示预测框与真值框之间的IOU。
每个 grid cell 还预测 $C$ 个类条件概率, $\text{Pr}(\text{Class}_i \mid \text{Object})$。这些概率取基于包含目标的 grid cell。YOLO 每个 grid cell 仅预测一组类概率,无论 bbox 的数量 $B$ 是多少。
在测试时,作者将类条件概率和单个框置信度相乘。
\[\text{Pr}(\text{Class}_i \mid \text{Object}) * \text{Pr}(\text{Object}) * \text{IOU}_{pred}^{truth} = \text{Pr}(\text{Class}_i) * \text{IOU}_{pred}^{truth} \tag{1}\]这些分数编码该类出现在 box 中的概率以及预测的 box 与目标的匹配程度。
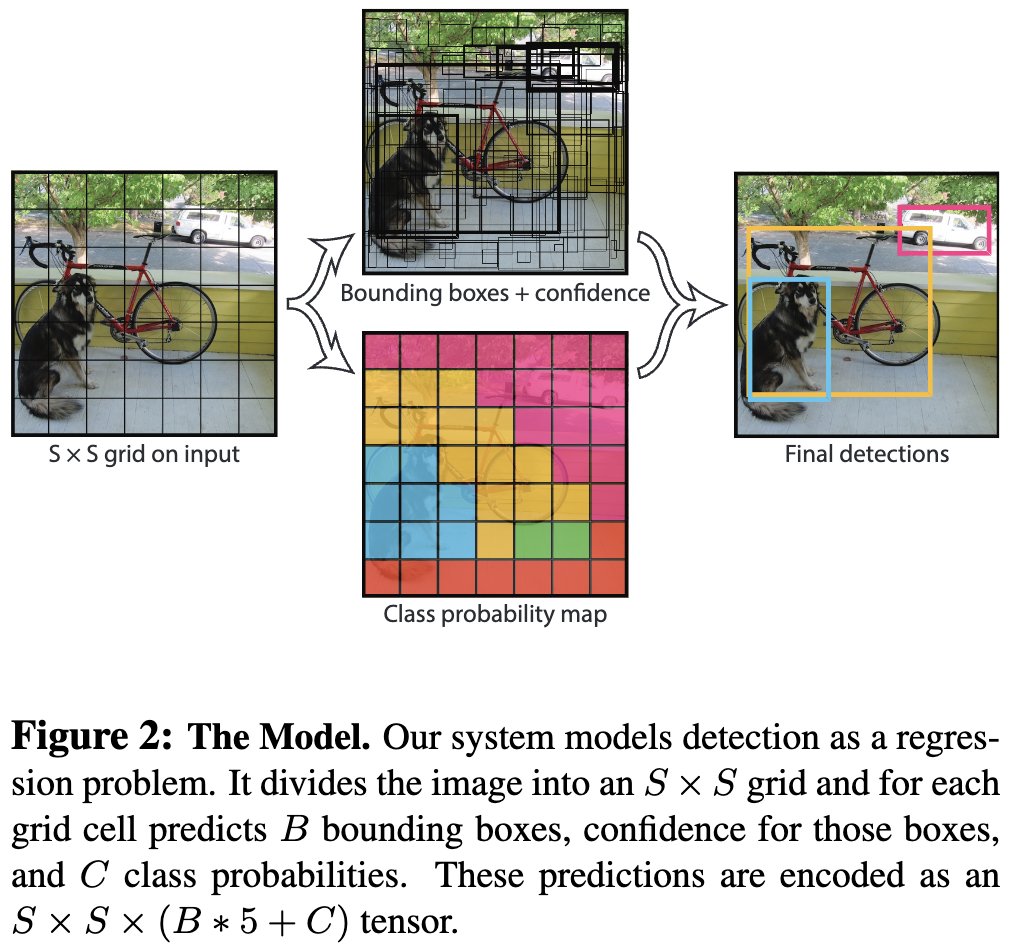
对于在 PASCAL VOC 上评估 YOLO, 作者使用 $S = 7, B = 2$。 PASCAL VOC 有 20 个标签类,因此 $C = 20$。 最终预测是一个 $7 \times 7 \times 30$ 的张量。
Network Design
作者将该模型实现为卷积神经网络,并在PASCAL VOC检测数据集上对其进行评估。 网络的初始卷积层从图像中提取特征,而全连接层预测输出概率和坐标。
该网络有24个卷积层,其次是2个全连接层。与GoogLeNet使用的初始模块不同,作者简单地使用了 $1 \times 1$ 卷积层用于 reduction, 后面是 $3 \times 3$ 卷积层,类似于Lin等人。 如图3所示。

作者还训练了YOLO的快速版本,旨在推动快速目标检测的边界。Fast YOLO使用的神经网络卷积层更少(9层而不是24层),这些层中的 filter 也更少。除了网络的大小,YOLO和Fast YOLO的所有训练和测试参数都是相同的。
网络的最终输出是 $7 \times 7 \times 30$ 的张量。
Training
作者在ImageNet 1000-class 竞赛数据集上预训练卷积层。对于预训练,作者使用图3中的前20个卷积层,然后是平均池化层和全连接层。作者在训练和推理都使用 Darknet 框架。
现在将模型转换为 detection 模型。Ren等人的研究表明,在预训练的网络中同时添加卷积层和连接层可以提高性能。按照他们的例子,作者添加了四个卷积层和两个全连接层,并随机初始化权值。检测通常需要细粒度的视觉信息,因此我们将网络的输入分辨率从 $224 \times 224$ 提高到$448 \times 448$ 。
最后一层同时预测类概率和 bbox 坐标。作者用图像的宽度和高度对 bbox 的宽度和高度进行规范化,使它们落在0和1之间。作者将 box $x$ 和 $y$ 坐标参数化为特定 grid cell 位置的偏移量,因此它们也被限定在0和1之间。
作者最后一层使用线性激活函数和所有其他层使用以下 leaky rectified 线性激活。
\[\phi(x) = \begin{cases} x & \text{if } x > 0 \\ 0.1x & \text{otherwise} \end{cases} \tag{2}\]作者对网络的输出优化平方和误差。作者使用平方和误差,因为它很容易优化,但它并不完全符合最大化平均精度的目标。它对定位误差和分类误差的按同等权重加权,可能不太理想。此外,在每幅图像中,许多 grid cell 不包含任何目标。这将使这些 cell 的置信度接近于零,通常压倒了包含目标的 cell 的梯度。这可能会导致模型不稳定,导致训练早期发散。
为了弥补这一点,作者对不包含目标的框增大了边界框坐标预测的损失,并减少了置度预测的损失。作者使用两个参数 $\lambda_{coord}$ 和 $\lambda_{noobj}$ 来完成这一任务。作者设置 $\lambda_{coord} = 5$ 和 $\lambda_{noobj} = 0.5$。
平方和误差在大 box 和小 box 中的权重也相等。误差度量应该反映出大 box 里的小偏差 比 小box 里的小偏差影响小。为了部分解决这个问题,作者预测边界框宽度和高度的平方根,而不是直接预测宽度和高度。
YOLO每个 grid cell 预测多个边界框。在训练时,作者只希望一个 box 预测器对应一个目标。作者分类一个 predictor 负责预测一个目标,根据该预测和真实值之间的 IOU 最大。每个 predictor 都能更好地预测特定的尺寸、纵横比或对象的类别,从而提高整体 recall 能力。
训练期间优化下列损失函数:
\[\lambda_{coord} \sum_{i=0}^{S^2}\sum_{j=0}^B \mathbb{1}_{ij}^{obj}[(x_i - \hat x_i)^2 + (y_i- \hat y_i)^2] \\ + \lambda_{coord} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{obj} [(\sqrt{w_i} - \sqrt{\hat w_i})^2 + (\sqrt{h_i} - \sqrt{\hat h_i}^2)] \\ + \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{obj}(C_j - \hat C_i)^2 \\ + \lambda_{noobj} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{noobj}(C_i - \hat C_i)^2 \\ + \sum_{i=0}^{S^2} \mathbb{1}_i^{obj} \sum_{c \in classes} (p_i(c) - \hat p_i(c))^2 \tag{3}\]其中 $\mathbb{1}i^{obj}$ 表示 cell $i$ 中出现目标, $\mathbb{1}{ij}^{obj}$ 表示 cell $i$ 中第 $j$ 个 bbox predictor 负责的预测。
请注意,如果 grid cell 中存在目标,则损失函数只惩罚分类错误(因此前面讨论了类条件概率)。如果预测器负责真值框,它也只会产生边界框坐标误差(即,在该 grid cell 中,IOU最高的预测器)。
作者利用PASCAL VOC 2007和2012年的训练和验证数据集对网络进行了大约135个epoch的训练。在2012年的测试中,还包含了VOC 2007的测试数据用于训练。
Inference
就像在训练中一样,预测测试图像的检测只需要一次网络评估。在PASCAL VOC算法中,网络预测每幅图像98个 bbox 和每个 box 的类概率。YOLO在测试时速度非常快,因为它只需要一个网络评估,不像基于分类器的方法。
grid 设计加强了边界框预测的空间多样性。通常,目标所属的 grid cell 很清楚,网络只能为每个目标预测一个框。但是,一些较大的对象或多个 grid cell 附近的目标可以被多个单元格很好地定位。非最大抑制可以用来修复这些多重检测。
Conclusion
这篇文章引入了目标检测的统一模型YOLO。该模型简单易于构建并且可以直接在整张图像上训练。与基于分类器的方法不同,YOLO是在一个直接对应检测性能的损失函数上训练的,整个模型是联合训练的。
Fast YOLO是文献中最快的通用目标检测器,YOLO推动了实时目标检测的最先进技术。YOLO还可以很好地泛化到新的领域,使其成为依赖于快速、健壮的目标检测的应用的理想选择。
Summary
论文中(x, y, w, h)的相对关系怎么理解
损失函数中的计算怎么理解
-
Previous
【深度学习】YOLO9000(YOLO V2): Better, Faster, Stronger -
Next
【深度学习】A New TwIST: Two-Step Iterative Shrinkage Thresholding Algorithms for Image Restoration