Abstract
特征金字塔是识别系统中检测不同尺度物体的基本组成部分。
但最近的深度学习目标检测器避免了金字塔的表征,部分原因是它们是计算和内存密集型的。
这篇文章利用深度卷积网络固有的多尺度金字塔层次结构,以少量的额外成本构建特征金字塔。
开发了一个具有横向连接的自上而下的架构,用于构建各种尺度的高级语义特征图。
这种架构被称为特征金字塔网络(FPN),在几个应用程序中作为通用特征提取器进行了重大改进。
在基本的 Faster R-CNN 系统中使用FPN,该方法在 COCO 检测基准上实现了最先进的单模型结果,超过了所有现有的单模型结果,包括COCO 2016 Challenge 获胜者。
Feature Pyramid Networks
作者的目标是利用ConvNet的金字塔特征层次结构,该层次结构具有从低级到高级的语义,并构建一个具有高级语义的特征金字塔。由此产生的特征金字塔网络是通用的,这篇文章重点介绍了滑动窗口 proposer(区域提议网络,简称RPN)[29]和基于区域的检测器(Faster R-CNN)。
该方法将任意大小的单尺度图像作为输入,并以全卷积的方式在多个层次上输出任意大小的特征图。这个过程独立于主干卷积结构(例如,[19,36,16]),在这篇文章中,作者使用ResNets[16]给出了结果。该金字塔的构建涉及自下而上的路径、自上而下的路径和横向连接,如下所示。
Bottom-up pathway. 自下而上的路径是主干ConvNet的前向计算,它提出了一个由几个尺度特征图组成的特征层次结构,缩放步长为2。通常有很多层产生相同大小的输出映射,我们说这些层处于相同的网络阶段。对于特征金字塔,作者为每个阶段定义一个金字塔级别。作者选择每个阶段最后一层的输出作为参考特征图集,作者将丰富它来创建金字塔。这种选择是自然的,因为每个阶段的最深层应该具有最强的特征。
特别地, 对于 ResNet, 作者使用每个阶段最后一个残差块的特征激活。作者将最后一个残差块的输出记作 ${C_2, C_3, C_4, C_5}$ 对于 conv2, conv3, conv4 和 conv5 输出, 它们相对于输入图像的步长为 ${4, 8, 16, 32}$。由于金字塔的内存占用很大,作者没有将 conv1 包含在金字塔中。
Top-down pathway and lateral connections. 自上而下的路径通过从更高的金字塔层级上采样得到空间更粗糙但语义上更强的特征来产生更高的分辨率特征。然后,通过横向连接从自下而上的路径增强这些特征。每个横向连接从自下而上的路径和自上而下的路径合并了相同空间大小的特征图。自下而上的特征图是较低层级的语义,但由于下采样的次数较少,其激活更加集中局部化。
图3显示了构建作者自上而下的特征图的构建块。使用更粗分辨率的特征图,作者将空间分辨率上采样2倍(为了简单起见,使用最近邻上采样)。然后,通过元素相加,将上采样的特征图与对应的自底向上特征图(经过 $1 \times 1$ 卷积层以减少通道维度) 合并。此过程被迭代,直到生成最佳分辨率特征图。为了开始迭代,作者在 $C_5$ 上使用 $1 \times 1$ 的卷积层产生最粗粒度的分辨率图。最终, 作者在每个合并的特征图上添加 $3 \times 3$ 卷积生成最终的特征图, 其减少由于上采样产生的混叠效应。最终的特征图的集合称为 $P_2, P_3, P_4, P_5$, 对应与 $C_2, C_3, C_4, C_5$, 其有着对应的相同的空间大小。
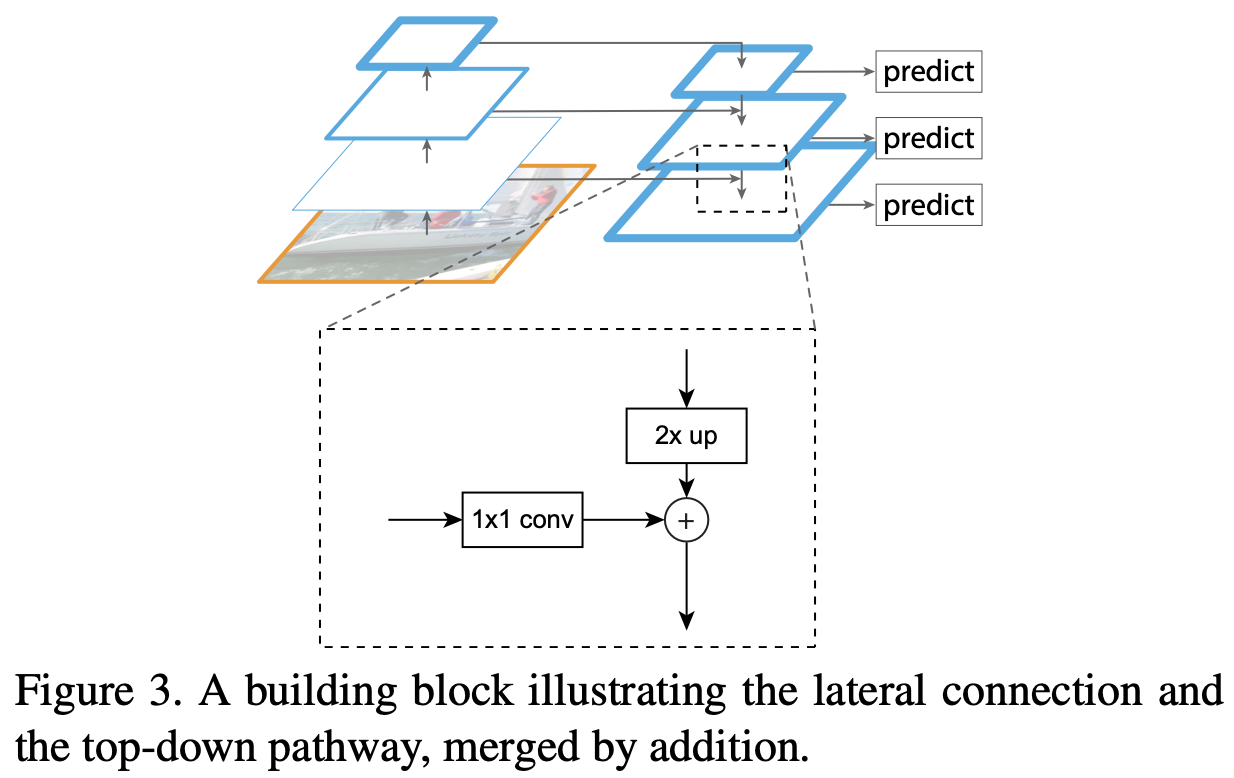
由于金字塔的所有层级都使用共享分类器/回归器,因此作者固定所有特征图中的特征维度(通道数量,表示为 $d$)。 作者在文章中设置 $d = 256$ , 因此额外的卷积层有 256 通道输出。这些额外的层中没有非线性激活,作者实验发现它们会产生轻微的影响。
简单性是设计的核心,作者发现模型对许多设计选择都很鲁棒。作者试验了更复杂的块(例如,使用多层残差块作为连接),观察到稍好的结果。设计更好的连接模块不是这篇文章的重点,因此作者选择了上述的简单设计。
Applications
作者的方法是在深层ConvNets中构建特征金字塔的通用解决方案。在下面,作者采用RPN作为边界框提议生成的方法,使用 Fast R-CNN [11] 做目标检测。为了证明所提方法的简单性和有效性,当它们适应特征金字塔时,作者对[29,11]的原始系统进行了最小的修改。
Feature Pyramid Networks for RPN
RPN [29]是一个滑动窗口 class-agnostic 的目标检测器。在最初的 RPN 设计中,使用一个小的子网络在单尺度特征图上执行一个密集的 $3 \times 3$ 滑动窗口,执行目标/非目标二分类和边界框回归。这通过一个 $3 \times 3$ 卷积层,然后是两个 $1 \times 1$ 卷积来进行分类和回归,称之为网络 head。 用于目标/非目标准则和边界框回归目标的一组参考框称为先验框。先验框具有多个预定义的尺度和宽高比,以覆盖不同形状的物体。
作者通过用FPN取代单尺度特征图来适应RPN。作者在特征金字塔的每个层级上都附加一个相同设计的 head($3 \times 3$ conv和两个 $1 \times 1$ convs)。因为 head 在所有金字塔层级的所有位置上密集滑动,在特定的层级上没有必要有多尺度的先验框。相反,作者为每个层级分配一个单一尺度的先验框。最终,作者定义先验框的在 ${P_2, P_3, P_4, P_5, P_6}$ 上的尺度为 ${32^2, 64^2, 128^2, 256^2, 512^2}$。作者在每个层级上使用不同长宽比的先验框 ${1:2, 1:1, 2:1}$。 因此 ,在金字塔上总共有15个先验框。
我们根据先验框的交并比(IoU)为先验框分配训练标签。 形式上,如果先验框与真实框接的IoU最高,或者与任何真实框的 IoU 超过 0.7,则先验框将被分配一个正标签,如果所有真实框的 IoU 小于 0.3,则先验框将被分配负标签。请注意,真实框没有被明确用于将它们分配给金字塔的层级;真实框与先验框相关联,其已经被分配给了金字塔层级。
作者注意到,head 的参数在所有特征金字塔层级上都是共享的;作者还在不共享参数的情况下评估了替代方案,并观察到了类似的准确性。共享参数的良好性能表明,金字塔的所有层级都有相似的语义级别。这个优势类似于使用特征化的图像金字塔,其中通用 head 分类器可以应用于任何图像尺度计算的特征。
Feature Pyramid Networks for Fast R-CNN
Fast R-CNN [11]是一个基于区域的对象检测器,其中使用兴趣区域(RoI)池化来提取特征。Fast R-CNN最常在单尺度特征图上执行。要将其与FPN一起使用,需要将不同尺度的 RoI 分配给金字塔层级。
作者把特征金字塔看作是由图像金字塔产生的。因此,可以调整基于区域的检测器在图像金字塔上运行时的分配策略。形式上,作者通过以下方式将宽度 $w$ 和高度 $h$ 的 RoI(在网络的输入图像上)分配给特征金字塔的 $P_k$ 级:
\(k = \lfloor k_0 + \log_2 (\sqrt{wh} / 224) \tag{1}\) 这里 224 是 ImageNet 的预训练大小, $k_0$ 是目标在 $w \times h = 224^2$ 的 RoI 上映射的层级。在基于 ResNet 的 Fastrer R-CNN 系统中使用 $C_4$ 作为单尺度特征图, 作者设置 $k_0$ 为 $4$。直觉上等式(1) 意味着, 如果 RoI 的尺度小于 (224 的 1/2),他应该被映射为一个细粒度分辨率的层级(例如 $k=3$)。
作者将预测器头(在Fast R-CNN中,head 是 class-specific 的分类器和边界框回归器)附加到所有层级的所有 RoI 上。同样,head 都共享参数,无论其层级如何。在[16]中,ResNet 的 conv5 层(一个9层深子网络)被用作为conv4特征之上的 head,但作者的方法利用 conv5 来构建特征金字塔。因此,与[16]不同,作者只是采用 RoI 池化来提取 $7 \times 7$ 特征,并在最终分类和边界框回归层之前附加两个 1024 维的全连接(fc)层(每个后跟ReLU)。这些层是随机初始化的,因为 ResNets 中没有预训练的 fc 层。请注意,与标准的 conv5 头相比,2-fc MLP head更轻,速度更快。
Conclusion
这篇文章提出了一个干净简单的框架,用于在ConvNets中构建功能金字塔。
该方法在几个强大的基线和比赛获胜者方面取得了重大改进。
因此,它为特征金字塔的研究和应用提供了一个实用的解决方案,而无需计算图像金字塔。
最后,该研究表明,尽管深层ConvNet具有强大的表示能力及其对缩放变化的隐含鲁棒性,但使用金字塔表征明确解决多尺度问题仍然至关重要。
-
Previous
【深度学习】PANet:Path Aggregation Network for Instance Segmentation -
Next
【深度学习】YOLOv3: An Incremental Improvement