Abstract
为了让 Yolo 变得更好,作者做了一些小的设计更改。
作者还训练了这个相当 swell 的新网络。
它比上次大一点,但更准确。
不过,它仍然很快,别担心。
在 $320 \times 320$ 时,YOLO v3 以 22 毫秒的速度得到 28.2 mAP, 与SSD一样准确,但速度是 SSD 的三倍。
当我们查看旧的 .5 IOU mAP 检测指标 YOLO v3 相当不错。
它在 Titan X 上51毫秒内得到 57.9 $AP_{50}$ ,RetinaNet 在 198毫秒内达到 57.5 $AP_{50}$,相似的表现,但速度快3.8倍。
The Deal
所以这是 YOLOv3 的 deal:作者主要从其他人那里采纳了好想法。作者还训练了一个比其他分类器更好的新分类器网络。
Bounding Box Prediction
在YOLO9000之后,Yolo 系统使用 dimension clusters 作为 anchor boxes 预测边界框。 网络预测每个边界框的4个坐标, $t_x, t_y, t_w, t_h$。 如果 cell 从图像左上角偏移 $(c_x,c_y)$,并且先验边界框有宽度和高度 $p_w,p_h$,那么预测对应于:
\[b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y \\ b_w = p_w e^{t_w} \\ b_h = p_h e^{t_h}\]在训练期间,作者使用平方误差损失和。如果对于一些坐标预测的真值为 $\hat t_$ , 梯度是真值减去预测 $\hat t_ - t_*$。这个真值可以通过对上述方程的反求来轻松计算。
YOLOv3使用逻辑回归预测每个边界框的置信度分数。 如果先验边界框比之前的任何其他边界框重叠都大,它应该是1。如果先验边界框不是最好的,但与一个真值目标重叠超过某个阈值,则忽略预测。 作者使用0.5的阈值。该系统只为每个真值目标分配一个边界框。如果先验边界框没有分配给真值目标,则不会对坐标或类别预测产生损失,只有置信度。
Class Prediction
每个框使用多标签分类预测边界框可能包含的类。作者不使用softmax,因为发现它对于良好的性能是不必要的,相反,作者只是使用独立的逻辑分类器。在训练过程中,使用二分类交叉熵损失来进行类预测。
当我们转移到更复杂的域(如开放图像数据集)时,这个公式会有所帮助。 在这个数据集中有许多重叠的标签(即女人和人)。使用 softmax 假设每个边界框正好有一个类,而通常并非如此。多标签方法可以更好地对数据进行建模。
Predictions Across Scales
YOLOv3预测 3 个不同尺度的边界框。 该系统使用类似的概念从这些尺度中提取特征,以显示金字塔网络。 从基础特征提取器中,作者添加了几个卷积层。最后一个预测了三维张量, 其编码了边界框、置信度和类别预测。在COCO的实验中,预测每个尺度有3个边界框,包含 4 个边界框偏移量、1个置信度预测和 80个类别预测, 因此其大小为 $N \times N \times [3∗(4+1+80)]$。
接下来,作者从前面 2层 中提取特征图,并将其向上采样2倍。作者还从网络早期阶段获取特征图,并使用串联将其与的上采样特征合并。这种方法允许从上采样的特征中获得更有意义的语义信息,并从早期特征图中获得更细粒度的信息。然后,再添加几个卷积层来支持这个组合特征图,并最终预测类似的张量,但是现在是之前大小的两倍。
我们再执行一次相同的设计,以预测最终尺度的便捷光。因此,我们对第三尺度的预测受益于之前的所有计算以及网络早期阶段的细粒度特征。
作者仍然使用 k均值聚类来确定先验边界框。作者只是任意选择了9个聚类和3个尺度,然后在各个尺度之间均匀划分聚类。在COCO数据集中,9个聚类是: $(10 \times 13), (16 \times 30), (33 \times 23), (30 \times 61), (62 \times 45), (59 \times 119), (116 \times 90), (156 \times 198), (373 \times 326)$。
Feature Extractor
作者使用一个新的网络来执行特征提取。新网络是YOLOv2、Darknet-19中使用的网络和新的残差网络的混合方法。该网络使用连续的 $3 \times 3$ 和 $1 \times 1$ 卷积层,但现在也有一些跳跃方式连接,并且大得多。它有53个卷积层,所以我们叫它 Darknet-53!
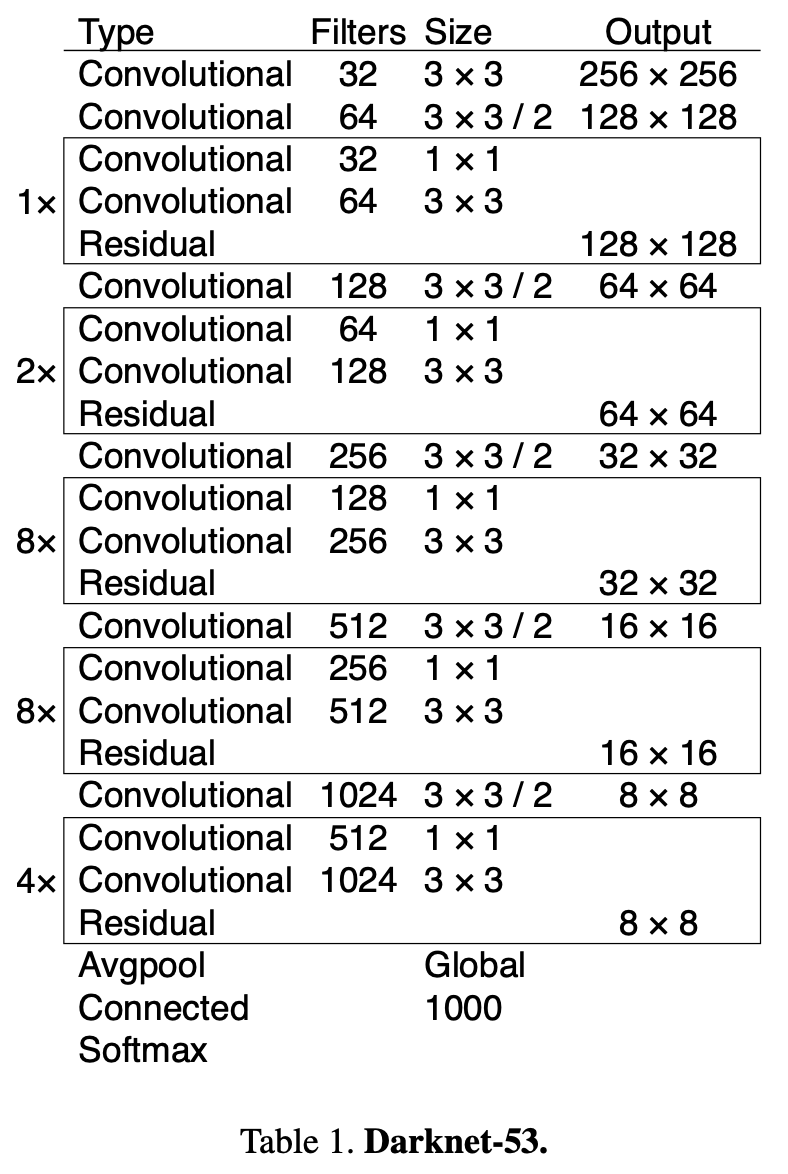 这个新网络比Darknet-19强大得多,但仍然比ResNet-101 或 ResNet-152更高效。以下是一些ImageNet结果:
这个新网络比Darknet-19强大得多,但仍然比ResNet-101 或 ResNet-152更高效。以下是一些ImageNet结果:
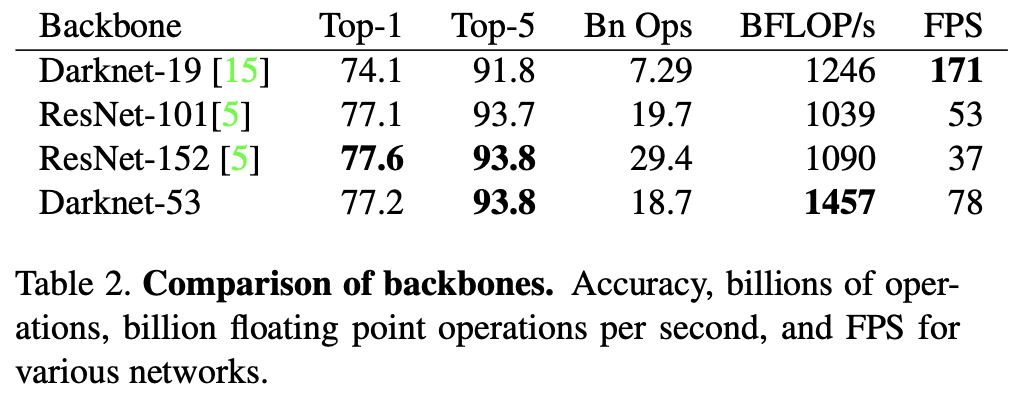
每个网络都以相同的设置进行训练,并以 $256 \times 256$ 的单一 crop 精度进行测试。运行时间在Titan X上测量为256×256。因此,Darknet-53的性能与最先进的分类器相当,但浮点操作更少,速度更快。Darknet-53比ResNet-101更好,速度为1.5倍。Darknet-53的性能与ResNet-152相似,速度快2倍。
Darknet-53还实现了每秒最高测量的浮点操作。这意味着网络结构更好地利用GPU,使其更高效地进行评估,从而更快。这主要是因为ResNets的层太多了,效率不是很高。
Training
作者仍然在完整的图像上进行训练,没有 hard negative mining 或任何东西。作者使用多尺度训练,大量数据增强,批规范化,所有标准的操作。我们使用 Darknet 神经网络框架进行训练和测试。
How We Do
YOLOv3相当不错!见表3。就COCOs奇怪的 mAP 指标而言,它与SSD变体相当,但速度快了3倍。但在这方面,它仍然落后于其他模型,如RetinaNet。
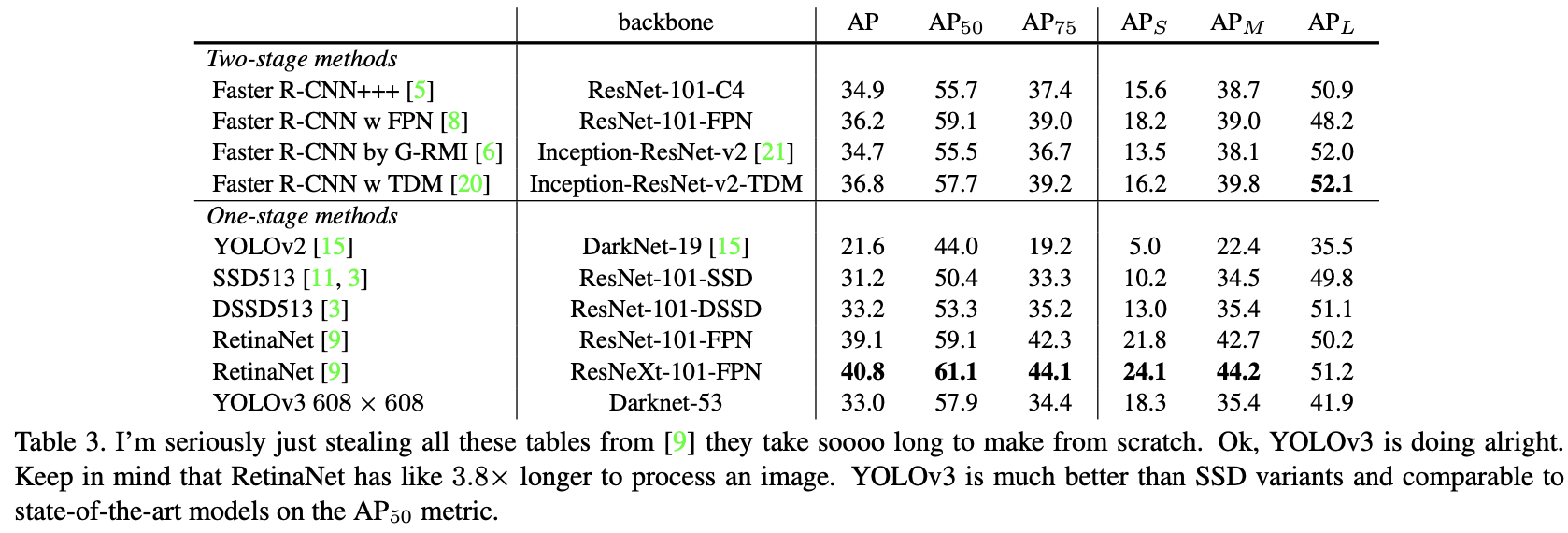
然而,当作者查看“旧”检测指标(IoU 为 0.5 时的mAP,表中的 $AP_{50}$)时, YOLO v3 非常强。它几乎与RetinaNet相当,远远高于SSD变体。这表明YOLOv3是一个非常强大的检测器,擅长为目标生成边界框。然而,随着 IoU 阈值的增加,性能显著下降,这表明 YOLOv3 难以使边界框与目标完美对齐。
过去,YOLO与小目标作斗争。现在,我们看到了这种趋势的逆转。通过新的多尺度预测,可以看到YOLOv3具有相对较高的 $AP_S$性能。然而,它在中型和大型物体上的性能相对较差。需要更多的调研才能弄清真相。
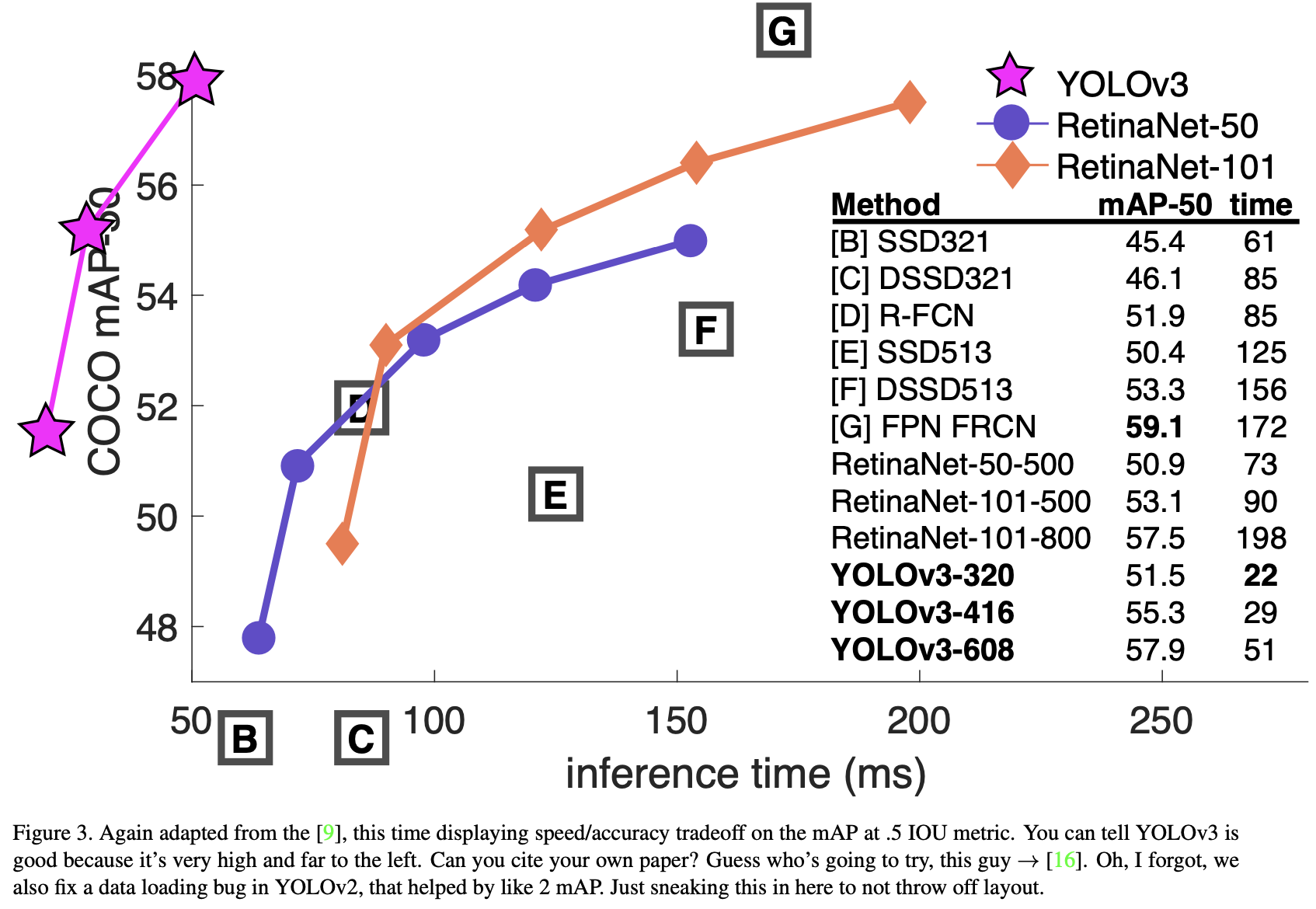
当绘制 $AP_{50}$ 指标的准确性与速度(见图3)时,YOLOv3比其他检测系统有显著的好处。也就是说,它更快、更好。
Conclusion
YOLOv3是一个很好的检测器。它速度快,准确。在0.5到0.95 IOU指标之间的COCO平均AP上,它并不那么好。但它对0.5 IOU的旧检测指标非常好。
无论如何,我们为什么要切换指标?原始的COCO论文只是有这句神秘的句子:“一旦评估服务器完成,将添加完整的评估指标”。Russakovsky等人报告说,人类很难区分0.3和0.5的 IoU! 训练人们视觉上将 IoU 为 0.3 的边界框与 IoU 为 0.5 的边界框区分开来是非常困难的。如果人类很难分辨出区别,这有多重要?
但也许一个更好的问题是:“既然我们有了这些检测器,我们该怎么办?”做这项研究的很多人都在 Google 和 Facebook。 我想至少我们知道这项技术掌握在好人手中,绝对不会用于收获你的个人信息并将其出售给……等等,你是说这正是它所用的??哦。
好吧,其他大量资助视觉研究的人是军队,他们从未做过任何可怕的事情,比如用新技术杀死很多人,哦,等等……
我有很多希望,大多数使用计算机视觉的人只是用它做快乐的好事,比如数国家公园里的斑马数量,或者在猫在房子里徘徊时跟踪它们。 但计算机视觉已经受到质疑,作为研究人员,我们至少有责任考虑我们的工作可能造成的伤害,并想办法对其进行破坏。我们欠世界这么多。
最后,不要@我。(因为我终于退出了推特)。
-
Previous
【深度学习】FPN:Feature Pyramid Networks for Object Detection -
Next
【深度学习】YSLAO: You Should Look at All Objects