Abstract
这篇文章介绍了基于多视图 RGB 的3D目标检测作为端到端优化问题的任务。
为了解决这个问题,作者提出了ImVoxelNet,这是一种基于 posed monocular 或多视图 RGB 图像的3D目标检测的新型全卷积方法。
在训练和推理过程中,每个多视图输入中的单目图像数量可能会发生变化;事实上,每个多视图输入的弹幕图像数量可能都不一样。
ImVoxelNet成功处理室内和室外场景,使其成为通用的。
具体来说,在所有接受 RGB 图像的方法中,它在 KITTI(单目)和 nuScenes(多视图)基准测试上实现了最先进的汽车检测结果。
此外,它超过了 SUN RGB-D 数据集上现有的基于 RGB 的 3D 目标检测方法。
在ScanNet上,ImVoxelNet为多视图3D目标检测设定了新的基准。
Proposed Method
该方法接受一组任意大小的RGB输入和相机位姿。首先,使用二维卷积主干从给定的图像中提取特征。然后,将获得的图像特征投影到3D voxel volume。对于每个 voxel,来自多个图像的投影特征通过简单的按元素平均聚合。接下来,具有指定特征的 voxel volume 传递给称为 neck 的3D卷积网络。 neck 的输出作为最后几个卷积层(head)的输入,这些卷积层预测了每个先验框的边界框特征。生成的边界框被参数化为 $(x, y, z, w, h, l, \theta)$, 其中 $(x, y, z)$ 是中心位置的坐标, $(w, h, l)$ 是宽高长, $\theta$ 是在 z 轴上的旋转角。该方法的一般方案如图1所示。
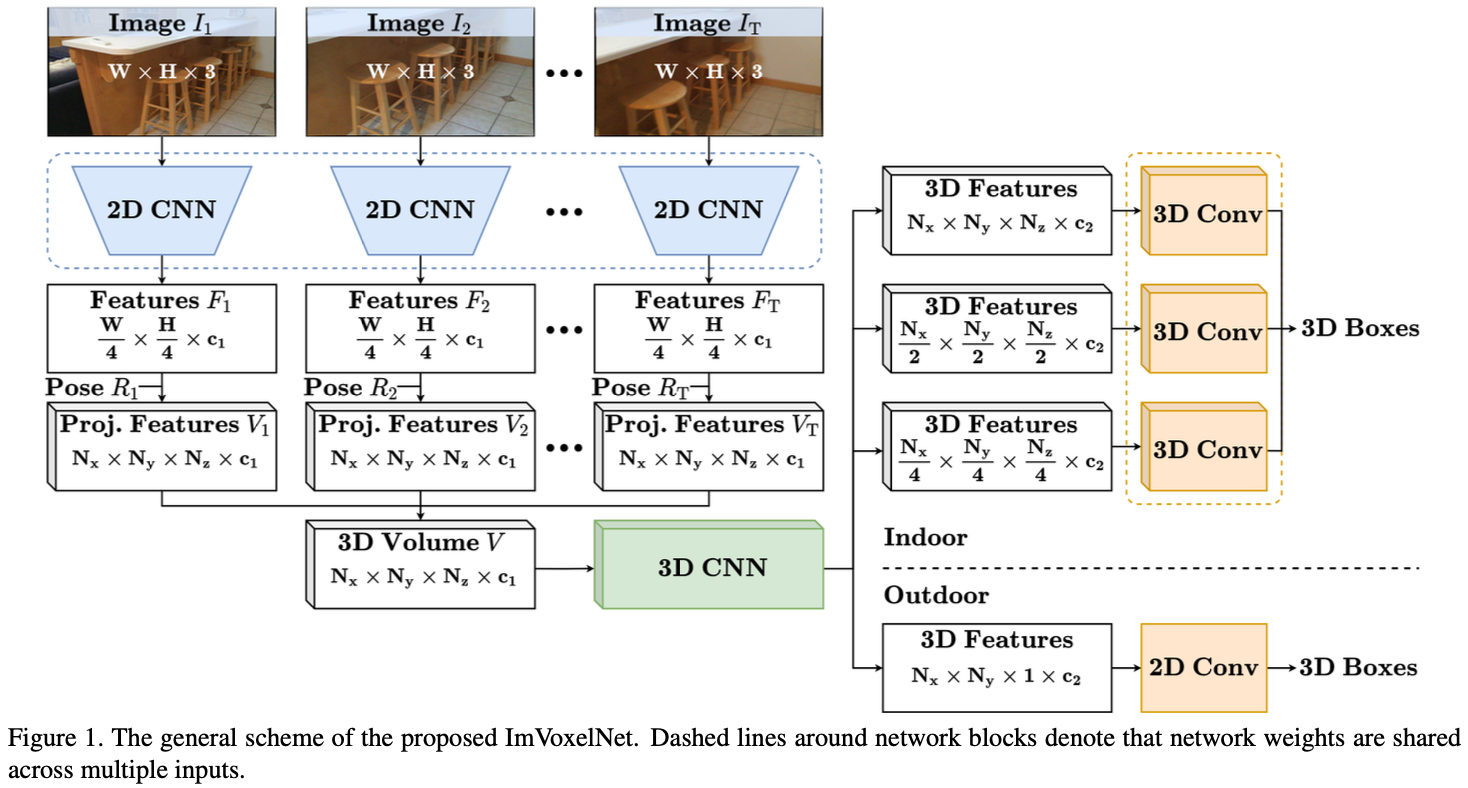
[26, 13] 提出了2D特征投影和3D neck 网络。 首先,作者简要概述这些步骤。然后,作者介绍了一种专为室内检测设计的新型多尺度3D head。
3D Volume Construction
令 $I_t \in \mathbb{R}^{W \times H \times 3}$ 作为一组 $T$ 个图像的第 $t$ 个图像。这里 $T > 1$ 对应多视角输入的情况, $T = 1$ 对应单视角输入的情况。和[26]一样,我们首先使用一个预训练的 2D 主干网络提取 2D 特征。
3D Feature Extraction
Detection Heads
Outdoor Head
Indoor Head
Extra 2D Head
Conclusion
这篇文章将基于多视图RGB的3D目标检测作为端到端优化问题。
为了解决这个问题,这篇文章提出了ImVoxelNet,这是一种针对给定单目或多视图RGB输入的3D目标检测的新的全卷积方法。
在训练和推理期间,ImVoxelNet接受具有任意数量视图的多视图输入。
此外,该方法可以接受单目输入(被视为多视图输入的特殊情况)。
该方法在单目KITTI基准和多视图nuScenes基准测试的户外汽车检测方面取得了最先进的结果。
此外,它在室内的 SUN RGB-D 数据集上超过了现有的3D目标检测方法。
对于ScanNet数据集,ImVoxelNet为室内多视图3D目标检测设定了新的基准。
总体而言,ImVoxelNet成功地处理了室内和室外数据,这使得它具有通用性。
-
Previous
【深度学习】DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection -
Next
【深度学习】From compressive sampling to compressive tasking: retrieving semantics in compressed domain with low bandwidth