Abstract
今天,视觉识别系统在机器人应用中仍然很少使用。
也许其中一个主要原因是缺乏模仿此类场景的基准。
这篇文章利用自动驾驶平台,为stereo、光流、visual odometry /SLAM和3D目标检测等任务开发了具有挑战性的新基准。
记录平台配备了四台高分辨率摄像机、一台 Velodyne 激光扫描仪和最先进的定位系统。
我们的基准包括389个 stereo 和光流图像对,39.2公里长的 visual odometry 序列,以及在杂乱场景中捕获的200多万个3D目标注释(每张图像最多可见15辆车和30名行人)。
最先进的算法结果表明,在Middlebury等既定数据集中排名靠前的方法在转移到现实世界之外时表现低于平均水平。
作者的目标是通过为计算机视觉社区提供具有新的具有挑战性的基准来减少这种偏差。
Challenges and Methodology
Ground Truth
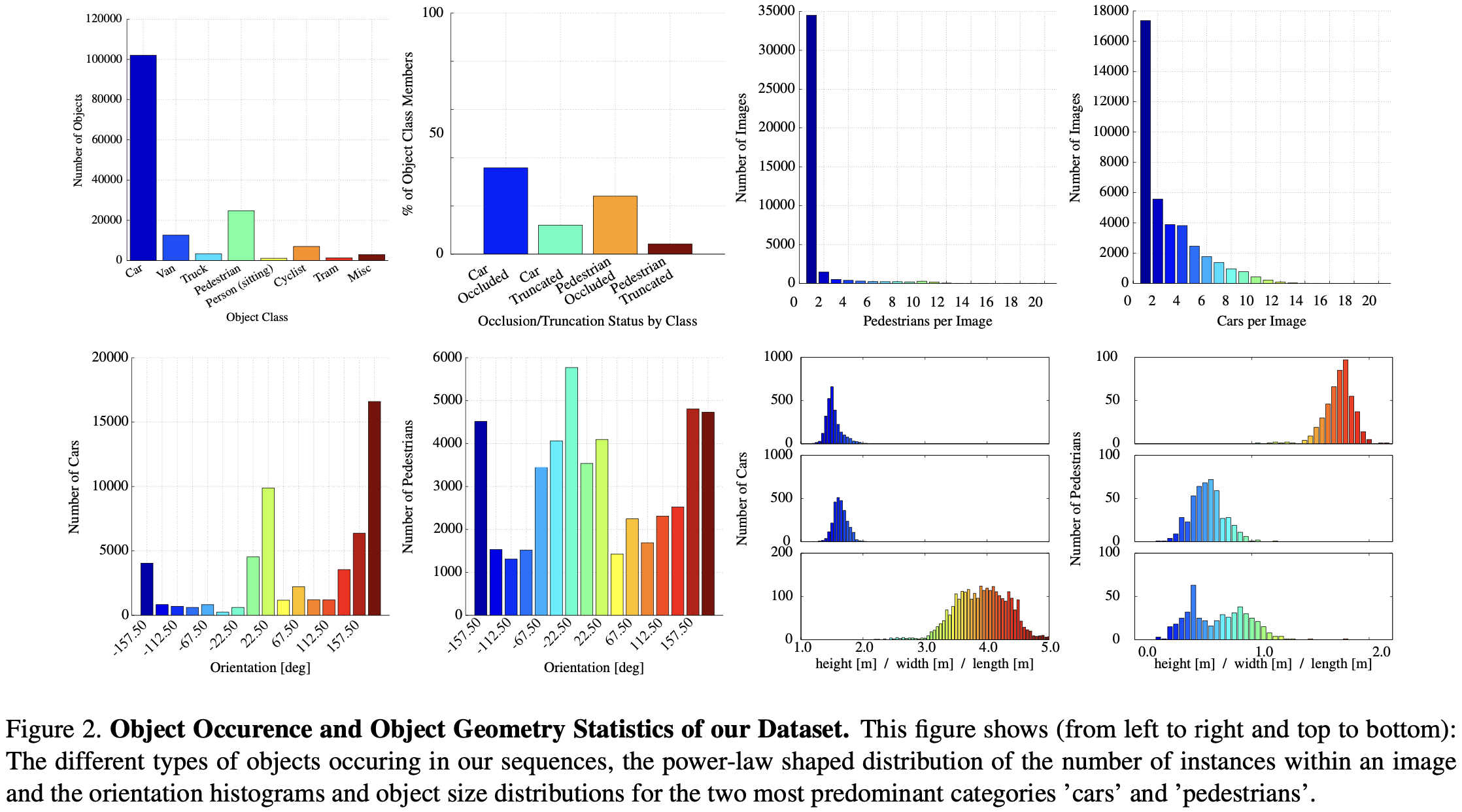
为了生成3D目标的标签,我们聘请了一组标注员,并要求他们以3D边界框的形式为汽车、面包车、卡车、电车、行人和非机动车等物体分配 tracks。与大多数现有的标记不同,我们不依赖在线众包来执行标注。为了实现这一目标,作者创建了一个特殊的目的标注工具,该工具显示3D激光点以及相机图像,以提高标注的质量。与[16]类似,我们要求标注员将每个边界框附加标记为可见、半遮挡、完全遮挡或截断。标注的统计数据如图2所示。
Evaluation Metrics
我们使用一套不同的指标来评估最先进的方法。
我们的3D目标检测和方向估计基准分为三个部分:首先,我们使用[16]中描述的平均精度(AP)指标来评估经典的2D目标检测。检测被迭代分配给标签,从最大的重叠开始,通过 IoU 衡量。我们要求真阳性重叠50%以上,并将同一目标的多次检测视为假阳性。我们使用一种新措施来评估联合检测物体并估计其3D方向,我们称之为平均方向相似性(AOS)。
Conclusion
作者对现有方法有了新的了解,作者希望提出的基准将补充其他基准,帮助减少对几乎没有训练样本或测试样本的数据集的过拟合,并有助于开发在实践中运行良好的算法。
由于作者记录的数据提供的信息比迄今为止汇编到基准中的信息要多,作者打算逐渐增加它们的困难度。
此外,作者还计划将具有 loop-closure 功能、目标跟踪、分割、从运动结构和3D场景理解的视觉SLAM纳入评估框架。
-
Previous
【深度学习】DAIR-V2X Project -
Next
【深度学习】VoxelNet:End-to-End Learning for Point Cloud Based 3D Object Detection