Abstract
点云中的目标检测是自动驾驶等许多机器人应用的一个重要方面。
这篇文章考虑了将点云编码为适合下游检测流程的格式的问题。
最近的文献表明,有两种类型的编码器;固定编码器往往速度快,但牺牲了准确性,而从数据中学习的编码器更准确,但速度更慢。
在这项工作中,作者提出了PointPillars,这是一种新的编码器,它利用 PointNets 来学习以 vertical columns (pillars) 组织的点云的表示。
虽然编码特征可以与任何标准的2D卷积检测架构一起使用,但作者进一步提出了一个精益的下游网络。
广泛的实验表明,PointPillars在速度和准确性方面都远远优于以前的编码器。
尽管只使用激光雷达,但在3D和鸟瞰 KITTI 基准方面,所提出的完整检测流程也明显超过了最先进的水平,即使在融合方法中也是如此。
这种检测性能是在 62 Hz下运行时实现的:运行时提高了2-4倍。
该方法的更快版本与 105 Hz的最新技术相匹配。
这些基准表明,PointPillars是用于点云中目标检测的合适编码。
PointPillars Network
PointPillars接受点云作为汽车、行人和非机动车的输入和估计定向3D边界框。它分为三个主要阶段(图2):(1)将点云转换为稀疏伪图像的特征编码器网络;(2)将伪图像处理为高级表示的二维卷积骨干;以及(3)检测和回归3D框的检测头。
Pointcloud to Pseudo-Image
要应用二维卷积架构,我们首先将点云转换为伪图像。
| 我们用 $l$ 表示点云中的一个点,坐标为 $x、y、z$ 和反射率 $r$ 。作为第一步,点云在 $x-y$ 平面上被离散成均匀间隔的网格,创建一组具有 $ | P | = B$ 的 pillars $P$ 。请注意,不需要超参数来控制 $z$ 维中的 binning。然后用 $x_c、y_c、z_c、x_p$ 和 $y_p$ 增强每个 pillar 中的点,其中 $c$ 下标表示与 pillar 中所有点的算术平均值的距离,$p$ 下标表示 pillar $x、y$ 中心的偏移量。增强激光雷达点 $l$ 现在是 $D = 9$ 维。 |
由于点云稀疏,这组 pillars 大多是空的,而非空 pillars 通常点也很少。例如,在 $0.16^2 m^2$ 处,HDL-64E Velodyne 激光雷达的点云具有 6k-9k 非空 pillars ,通常在KITTI中使用的范围内,稀疏度约为97%。这种稀疏性是通过限制每个样本的非空 pillars 数量(P)和每个 pillars 的点数(N)来发掘的,以创建一个大小为 $(D、P、N)$ 的稠密张量。如果样本或 pillar 包含太多数据,无法适应此张量,则数据是随机的。相反,如果样本或 pillar 的数据太少,无法填充张量,则应用零填充。
接下来,我们使用 PointNet 的简化版本,对于每个点,应用一个线性层,然后 BatchNorm[10] 和 ReLU[19]来生成 $(C,P,N)$ 大小的张量。接下来是对通道进行最大操作,以创建大小$(C,P)$ 的输出张量。请注意,线性层可以公式化为跨张量的 $1 \times 1$ 卷积,从而实现非常高效的计算。
一旦编码,这些特征将分散到原始 pillar 位置,以创建一个尺寸 $(C、H、W)$ 的伪图像,其中 $H$ 和 $W$ 表示画布的高度和宽度。
Backbone
我们使用与[31]相似的骨干,结构如图2所示。主干有两个子网络:一个自上而下的网络以越来越小的空间分辨率产生特征,另一个网络对自上而下的特征进行上采样和拼接。自上而下的主干可以由一系列块 $Block(S,L,F)$ 组成。每个块的步长为 $S$(相对于原始输入伪图像)。块具有带有 $F$ 输出通道的$L$ $3 \times 3$ 2D卷积层,每个通道后跟 BatchNorm 和 ReLU。
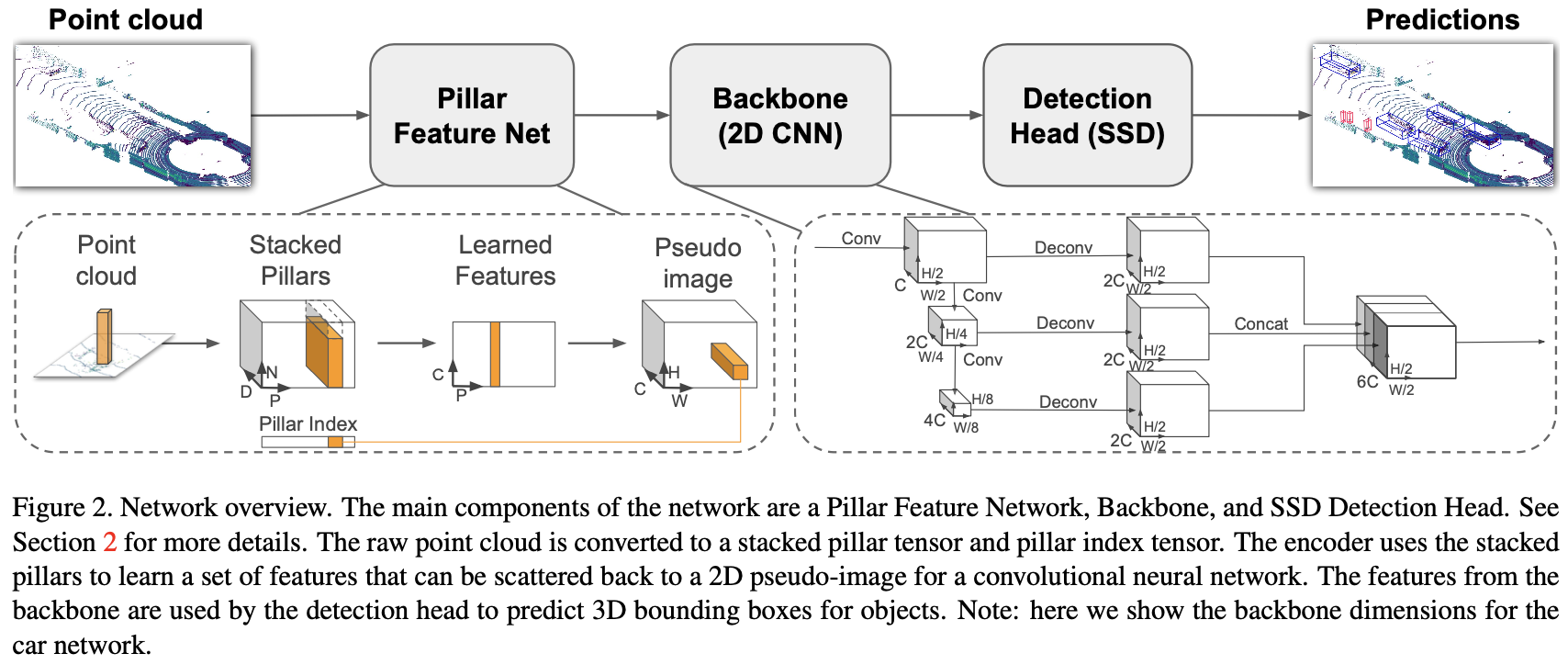 每个自上而下的块的最终特征通过上采样和拼接进行组合。
每个自上而下的块的最终特征通过上采样和拼接进行组合。
Detection Head
在这篇文章中,作者使用 Single Shot Detector (SSD) [18]设置来执行 3D 目标检测。与SSD类似,作者使用2D IoU将先验框框与真值匹配[4]。没有使用边界框高度和高度进行匹配;相反,给定2D匹配,height 和 elevation 成为额外的回归目标。
-
Previous
【深度学习】SECOND: Sparsely Embedded Convolutional Detection -
Next
【深度学习】Stable Diffusion:High-Resolution Image Synthesis with Latent Diffusion Models