Abstract
这篇文章提出了一种简单而高效的无先验框实例分割,称为CenterMask,它添加了一个新的空间注意力引导掩码(SAG-Mask)分支,以与Mask R-CNN[9]可以相比的无先验框单阶段物体探测器(FCOS [33])。
SAG-Mask 分支插入 FCOS 目标检测器,使用空间注意力图预测每个检测到的边界框上的分割 mask,这有助于关注信息像素并抑制噪声。
作者还提出了一种改进的骨干网络 VoVNetV2,具有两种有效的策略:(1)残差连接以缓解更大的 VoVNet 的优化问题[19 ]和(2)effective Squeeze-Excitation (eSE) 处理原始 SE 的通道信息丢失问题。
通过 SAG-Mask 和 VoVNetV2,作者设计了 CenterMask 和 CenterMask-Lite 各种大小的模型。
使用相同的ResNet-101-FPN主干,CenterMask 达到38.3%,以更快的速度超过了之前所有最先进的方法。
CenterMask
在本节中,首先,我们回顾了无先验框目标检测器FCOS[33],这是 CenterMask 的基本目标检测部分。
接下来,作者展示了 CenterMask 的原型,并描述了提出的空间注意力引导 mask 分支(SAG-Mask)如何设计为插入 FCOS 检测器。
最后,提出了一个更高效的骨干网络VoVNetV2,以提高 CenterMask 在准确性和速度方面的性能。
FCOS
FCOS 是一个无先验框和无提议的目标检测器,以逐像素预测方式进行检测,就像 FCN 一样。Faster R-CNN、YOLO 和 RetinaNet 等几乎最先进的物体探测器使用预定义先验框的概念,该先验框需要在训练中进行详细的参数调优和与框 IoU 相关的复杂计算。没有先验框,FCOS 在特征图级别的每个空间位置直接预测4D向量和类别标签。如图2所示,4D向量将边界框的四面的相对偏移量嵌入到位置(例如左、右、顶部和底部)。此外,FCOS引入了中心度分支来预测像素与其相应边界框中心的偏差,从而提高了检测性能。为了避免对先验框进行复杂的计算,FCOS 降低了内存/计算成本,但也优于基于先验框的物体检测器。由于FCOS 的效率和良好的性能,作者设计了基于FCOS 的物体探测器的所提出的 CenterMask。
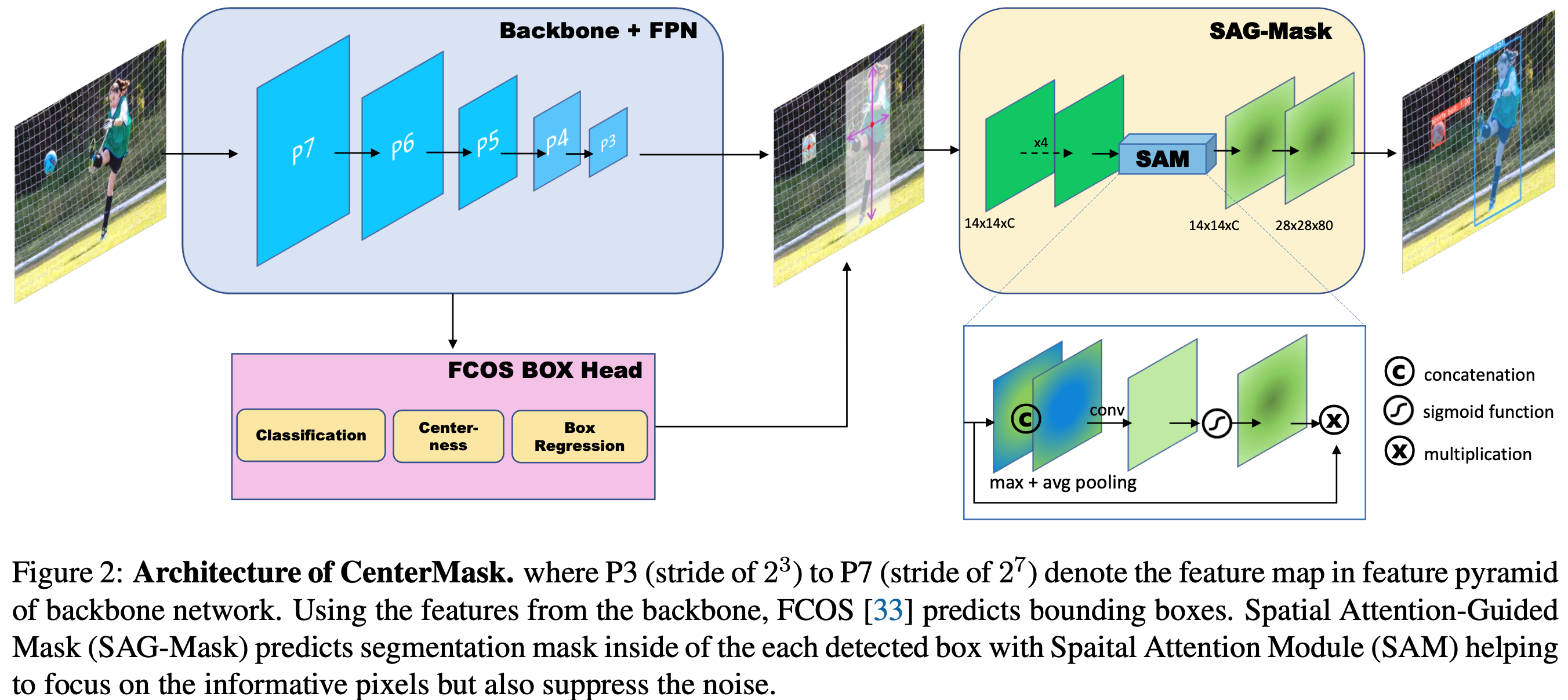
Architecture
图2显示了 CenterMask 的整体架构。CenterMask由三部分组成:(1)用于特征提取的骨干,(2)FCOS 检测头,以及(3)mask head。 masking objects 的过程包括从 FCOS box head 检测目标,然后以逐像素的方式预测裁剪区域内的分割 mask。
Adaptive RoI Assignment Function
在FCOS box head 预测目标提议后,CenterMask 使用与 Mask R-CNN 相同的预测框区域预测分割 mask。
由于RoIs是从特征金字塔网络(FPN)中不同级别的特征图预测的,因此提取特征的 RoI Align 应根据 RoI 比例分配到不同尺度的特征图尺度。
具体来说,大尺度的 RoI 必须分配到更高的特征级别,反之亦然。
基于 Mask R-CNN 的两阶段检测器使用 FPN 中的方程1来确定要分配的特征图。
\[k = \lfloor k_0 + \log_2 \sqrt{wh} / 224 \rfloor \tag{1}\]其中 $k_0$ 是 4 , $w, h$ 是每个 RoI 的宽和高。然而,等式 1 不适合基于 CenterMask 的单阶段检测器,原因有二。
首先,等式 1 中两阶段检测器和单阶段检测器使用的特征层级不一样。两阶段检测器使用特征层级 P2 到 P5。 而单阶段检测器使用 P3 到 P7, 其具有更大的感受野和更低的分辨率。
此外,等式1中的典型ImageNet预训练尺寸224是硬编码的,不适应特征尺度变化。例如,当输入维度为 $1024 \times 1024$,RoI的面积为 $224^2$ 时,RoI 被分配到相对较高的特征 P4,因为其相对于输入维度的面积较小,从而减少了小目标的 AP。
因此,作者将等式2定义为适用于基于 CenterMask 的单阶段检测器的新 RoI 分配函数。
\(k = \lceil k_{max} - \log_2 A_{input} / A_{RoI} \rceil \tag{2}\) 其中 $k_{max}$ 是主干特征图的最后的层级(例如 7), $A_{input}$ 和 $A_{RoI}$ 分别是输入图像和 RoI 的区域。在等式1中没有 canonical size 224的情况下,方程2可以根据 input/RoI 面积的比率自适应地分配 RoI 池化尺度。如果 $k$ 低于最小层级(例如P3),k被阶段在最小层级。