论文部分

Abstract
我们提出空间自适应规范化, 它是网络中的一个简单但是有效的层, 对给定一个语义布局输入, 合成真实感的图像。之前的方式直接将语义布局作为输入送入深度网络, 然后被堆叠起来的卷积层,规范化层和非线性层处理。我们展示了这不是最好的方法因为规范化层倾向于“洗去”语义信息。为了解决这个问题, 我们提出使用输入布局通过空间自适应的,可学习的变换来调整规范化层中的激活。 在几个有挑战性的数据集上的实验展示了, 不管是视觉上的保真度还是对输入的对齐, 我们提出的方式比现存的方式都具有优势。最后,我们的模型允许用户控制语义和风格。
1. Introduction
条件图像合成是指根据某些输入数据生成照片级真实的图像的任务。开创性工作通过缝合单个图像中的片段(比如图像类比)或使用图像集合来计算输出图像。最近的方法使用神经网络直接学习映射。后一种方法更快,并且不需要外部图像数据库。我们对条件图像合成的一种特定形式感兴趣,该形式将语义分割掩膜转换为照片级真实的图像。这种形式具有广泛的应用,例如内容生成和图像编辑。 我们将此形式称为语义图像合成。在这篇文章中,我们展示了,通过堆叠卷积,规范化和非线性层构建的常规网络体系结构充其量是次优的,因为它们的规范化层往往会“洗掉”输入语义掩码中包含的信息。为了解决这个问题, 我们提出了空间自适应规范化, 一个条件规范化层, 该条件规范化层使用输入的语义布局通过空间自适应,可学习的变换来调整激活,并可以在整个网络中有效传播语义信息。
我们对包括COCO-Stuff,ADE20K和Cityscapes在内的几个具有挑战性的数据集进行了实验。 我们表明,借助我们的空间自适应规范化层,与几种最新方法相比,一个压缩的的网络可以合成更好的结果。此外, 一个拓展的研究展示了针对语义图像合成任务的几种变体,我们提出的规范化层的有效性。最后,我们的方法支持多形式和风格引导的图像合成,从而实现可控的多样化输出,如图1所示。
2. Related Work
深度生成模型可以学习合成图像。最近的方法包括生成对抗网络(GAN)和变分自编码器(VAE)。我们的工作建立在GAN的基础上,但目标是条件图像合成任务。GAN由生成器和判决器组成,其中生成器的目标是生成真实图像,使判决器无法分辨合成图像与真实图像。
条件图像合成存在很多种形式,它们的不同在于输入数据的类型不同。例如,类别条件模型学习在给定类别标签的情况下合成图像。研究人员探索了各种基于文本生成图像的模型。另一种广泛使用的形式是基于条件GAN类型的图像到图像翻译, 其中输入和输出均为图像。与早期的非参数方法相比,基于学习的方法通常在测试期间运行速度更快,并产生更真实的结果。 在这项工作中,我们专注于将分割掩膜转换为相片般真实的图像。我们假设训练数据集包含注册的分割掩膜和图像。通过提出的空间自适应规范化,与领先的方法相比,我们的压缩型网络可获得更好的结果。
无条件规范化层是现代深度网络中的重要组成部分,可以发现在各种分类器中, 包括Inception-v2网络中的批次规范化(BatchNorm)等。其它流行的规范化层包括实例规范化(InstanceNorm),层规范化,组规范化和权重规范化。我们将这些规范化层标记为无条件的,因为与下面讨论的条件规范化层相比,它们不依赖外部数据。
条件规范化层包括条件批处理规范化(Conditional BatchNorm)和自适应实例规范化(AdaIN)。 两者都首先在风格转换任务中使用,然后在各种视觉任务中采用。与早期的规范化技术不同,条件规范化层需要外部数据,并且通常如下操作。首先,将层激活标准化为零均值和单位方差。然后,规范化后的激活通过使用学习到的仿射变换调整激活进行去规范化, 仿射变换的参数从外部数据中推断得到。对于风格迁移任务, 仿射变换参数用于用于控制输出的全局风格, 因此在整个空间上是协调一致的。 相反,我们提出的规范化层应用了一种空间变化的仿射变换,使其适合于语义掩膜的图像合成。 Wang等人 提出了一种与图像超分辨率密切相关的方法。 这两种方法都建立在基于语义输入的空间自适应调节层上。 它们的目的是将语义信息纳入超分辨率,但我们的目标是设计一个用于风格和语义分离的生成器。我们专注于提供在调整规范化的激活背景下的语义信息。我们使用不同尺度下的语义信息,这可以完成从粗糙到细致的生成。
3. Semantic Image Synthesis
用$m \in L^{H \times W}$一个语义分割掩膜,其中$L$是一个整数的集合表示语义的标签, $H$和$W$是图像的高和宽。我们的目的是学习一个映射函数,可以将输入分割掩膜m转换为具有真实感的图像。
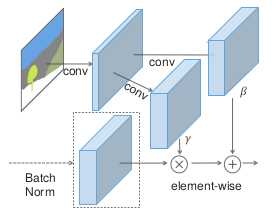
Figure 2: 在SPADE中, mask首先被投影到一个 embedding 空间中, 然后卷积产生参数 $\gamma$ 和 $\beta$。 和先前的条件规范化方式不同,$\gamma$ 和 $\beta$ 不是向量, 而是有空间维度的tensor。 $\gamma$ 和 $\beta$ 按元素乘和加到规范化后的激活上。
空间自适应反规范化。 用$h^i$表示一批N个样本的深度卷积网络的第i层的激活。 用$C^i$表示第i层中通道的数量。用$H^i$和$W^i$表示第i层激活映射的高和宽。 我们提出一种新的条件规范化方式叫做空间自适应反规范化(SPADE)。与BatchNorm相似, 激活进行通道级别的规范化,然后使用学习到的放缩和偏置因子调整。图2展示了SPADE的设计。激活在某一节点使用SPADE规范化计算公式为$(n \in N, c \in C^i, y \in H^i, x \in W^i)$:
\[\gamma_{c, y, x}(m) \frac{h_{n, c, y, x}^i - \mu_c^i}{\sigma_c^i} + \beta_{c, y, x}^i \tag 1\]其中$h_{n, c, y, x}^i$是该节点规范化之前的激活, $\mu_c^i$和$\sigma_c^i$是激活在通道c中的均值和标准差:
\[\mu_c^i = \frac{1}{NH^iW^i} \sum_{n, y, x} h_{n, c, y, x}^i \tag 2\] \[\sigma_c^i = \sqrt{\frac{1}{NH^iW^i}\sum_{n, y, x}((h_{n, c, y, x}^i)^2 - (\mu_c^i)^2)} \tag 3\]在(1)中的变量$\gamma_{c, y, x}^i(m)$和$\beta_{c, y, x}^i(m)$是规范化层学习到的调节参数。相比于BatchNorm, 它们依赖于输入分割掩膜,并分别随位置(y,x)而变化。我们使用符号$\gamma_{c, y, x}^i$和$\beta_{c, y, x}^i$表示在第i层激活映射节点(c, y, x)将m转化为放缩和偏置值的函数。 我们使用简单的两层卷积网络执行函数$\gamma_{c, y, x}^i$和$\beta_{c, y, x}^i$, 它的设计在附录中。
事实上,SPADE是现有的几个规范化层的一个泛化。 首先,用图像类标签代替分割掩码m,使调节参数在空间上不变(比如$\gamma_{c, y_1, x_1}^i \equiv \gamma_{c, y_2, x_2}^i$ 和 $\beta_{c, y_1, x_1}^i \equiv \beta_{c, y_2, x_2}$ , 对任意的\(y_1, y_2 \in \{1, 2, ..., H^i\}\)以及\(x_1, x_2 \in \{1, 2, ..., W^i\}\)), 我们实现了条件BatchNorm的形式。 事实上,对于任何空间不变的条件数据,我们的方法退化为条件批处理规范。 同样,我们可以通过用真实图像代替m来实现AdaIN,使调节参数在空间上不变,并设置N=1。 由于调节参数自适应于输入的分割掩膜,所提出的SPADE更适合于语义图像的合成。
SPADE生成器。 使用SPADE,没有必要将分割映射馈送到生成器的第一层,因为学习的调节参数已经编码了足够的关于标签布局的信息。因此,我们放弃了生成器的编码器部分,这在最近的结构中是常用的。 这种简化形成了一个更轻量级的网络。 此外,与现有的类条件生成器类似,新的生成器可以以随机向量作为输入,从而为多模态合成提供了一种简单而自然的方式。
图4展示了我们生成器的结构, 它在上采样层中使用了几个ResNet块。使用SPADE学习所有规范化层的参数。因为每个残差块操作在不同的尺度, 我们下采样语义掩膜去匹配空间分辨率。
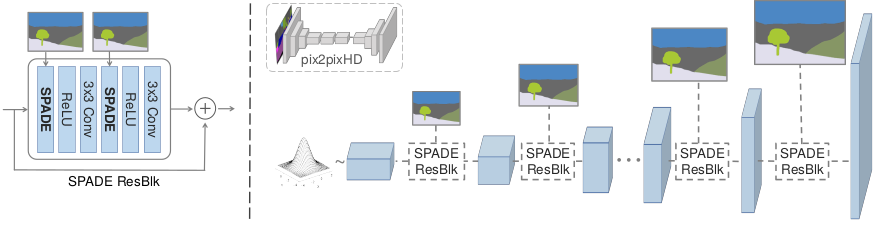
Figure 4:
我们用pix2pixHD中使用的相同的多尺度判决器和损失函数来训练生成器,但我们用hinge loss代替最小平方损失。 我们测试了最近在无条件GAN中使用的几个基于ResNet的判决器,但观察到相似的结果,代价是更高的GPU内存需求。 在判决器中添加SPADE也会产生相似的表现。 对于损失函数,我们观察到删除pix2pixHD损失函数中的任何损失项都会导致损害生成的结果。、
为什么SPADE更有效? 一个简短的答案是,它可以更好地保存语义信息,相比于常见的规范化层。 具体来说,虽然归一化层,如实例规范化,是几乎所有最先进的条件图像合成模型中必不可少的部分,但它们往往会洗掉语义信息,当应用于均匀或平坦的分割掩膜。
让我们考虑一个简单的模块,首先将卷积应用于分割掩膜,然后进行规范化。此外,让我们假设一个带有单个标签的分割掩膜作为模块的输入(例如,所有的像素都是同样的标签,比如天空或者草地)。 在此设置下,卷积输出再次是均匀的,不同的标签具有不同的均匀值。 现在,在我们将实例规范化应用于输出之后,无论给输入什么样的语义标签,规范化激活都将成为所有零。因此,语义信息完全丢失。 只要网络对语义掩膜应用卷积,然后规范化, 这一限制适用于广泛的生成器结构,包括pix2pixHD及其变体,这些结构在所有中间层连接语义掩膜。 在图3中,我们经验性地证明了这正是pix2pixHD的情况。 由于分割掩膜一般由几个均匀区域组成,因此在应用规范化时出现了信息丢失问题。
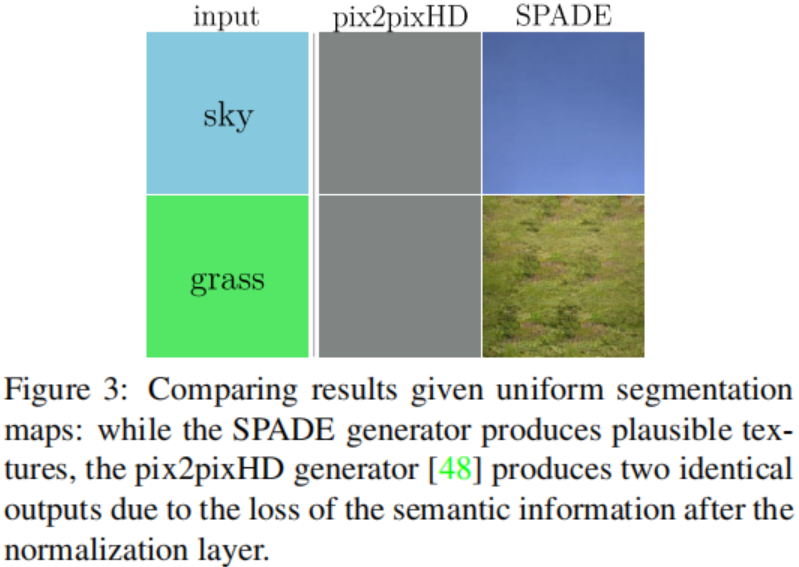
相反,SPADE发生器中的分割掩膜是通过空间自适应调节而不进行规范化的。 只有来自前一层的激活被规范化。 因此,SPADE生成器可以更好地保存语义信息。 它在不丢失语义输入信息的情况下,还保留规范化的好处。
多模态合成: 利用随机向量作为生成器的输入,为多模态合成提供了一种简单的方法。 也就是说,可以附加一个编码器,将真实图像处理成一个随机向量,然后将其馈送到生成器。 编码器和生成器形成VAE,其中编码器试图捕获图像的风格,而生成器通过SPADEs将编码风格和分割掩膜信息结合在一起进行重建原始图像。 编码器还在测试时充当风格引导网络,以捕获目标图像的风格,如图1所示。 对于训练,我们增加了KL-散度损失项。