Abstract
图像恢复任务要求在恢复图像时在空间细节和 high-level 的 contextualized 信息之间取得复杂的平衡。
这篇文章提出了一种新的 synergistic 设计,可以最优地平衡这些竞争目标。
这篇文章主要提议是一个多阶段的架构,逐步学习退化输入的恢复函数,从而将整个恢复过程分解为更易于管理的步骤。
具体地说,模型首先学习使用编码器-解码器架构的 contextualized 特征,然后将它们与保留局部信息的高分辨率分支结合起来。
在每个阶段,引入一种新的逐像素自适应设计,利用 in-situ supervised attention 来重新加权局部特征。
在这种多阶段架构中,一个关键组件是不同阶段之间的信息交换。
为此,这篇文章提出了一种 two-faceted 的方法,即信息不仅从早期到后期依次交换,而且特征处理块之间也存在横向连接,以避免信息的丢失。
由此产生的紧密相连的多阶段架构,被称为MPRNet,在包括图像解算、去模糊和去噪在内的一系列任务的10个数据集上提供了强大的性能提升。
Multi-Stage Progressive Restoration
图2所示的图像恢复框架包含三个逐步恢复图像的阶段。前两个阶段是基于编码器-解码器子网络学习广泛的上下文信息,由于大的感受野。由于图像恢复是位置敏感的任务(需要从输入到输出的像素到像素的对应),因此最后阶段采用一个子网络来操作原始输入图像分辨率(不需要任何降采样操作),从而在最终输出图像中保留所需的精细纹理。
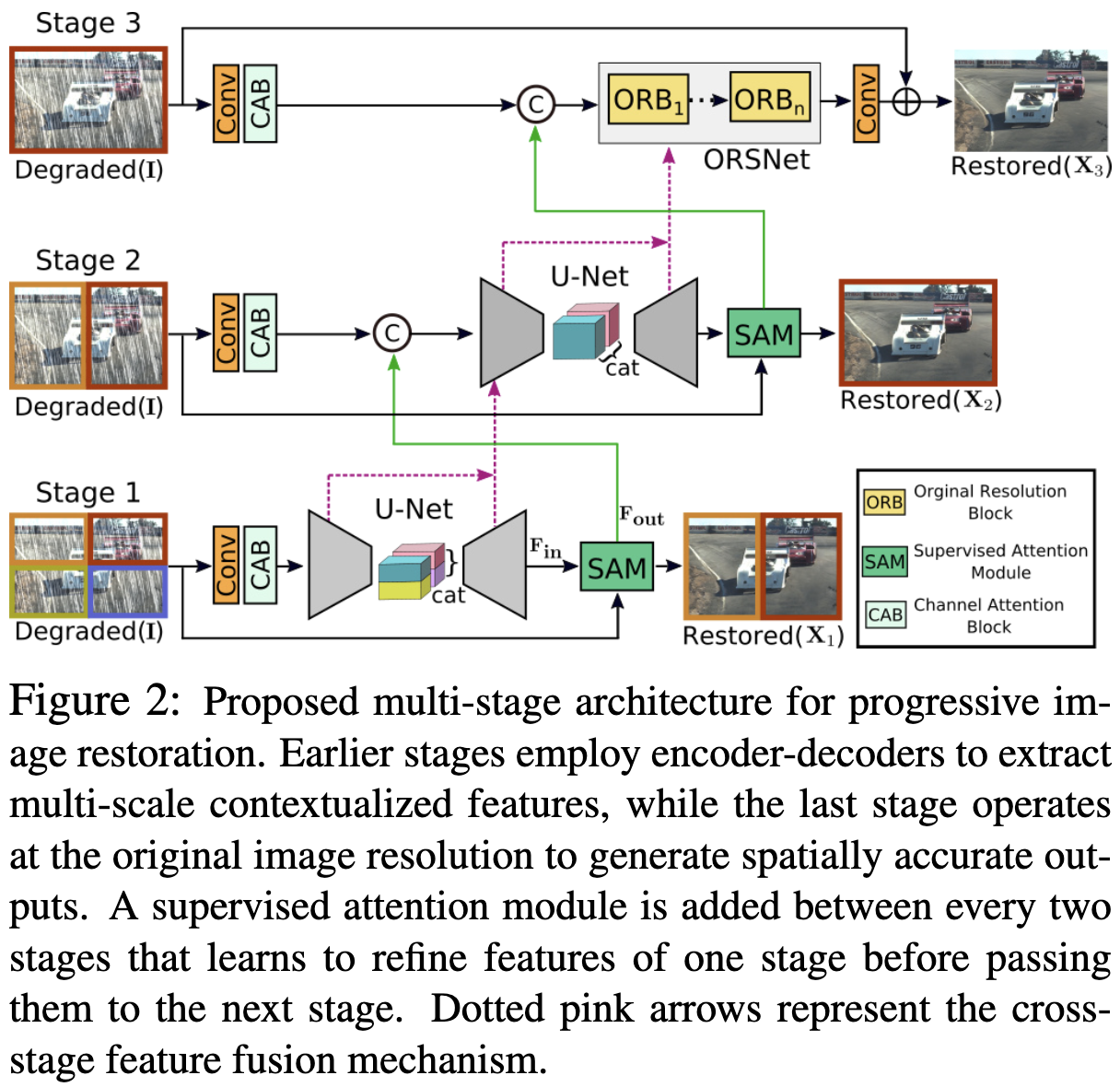
相比于简单地将多个阶段串联起来,作者在每两个阶段之间加入一个 supervised attention 模块。在真实图像的监督下,该模块在将前一阶段的特征图传递到下一阶段之前将其重新缩放。此外,作者还引入了一种跨阶段特征融合机制,早期子网络的中间多尺度上下文化特征有助于巩固后一子网络的中间特征。
尽管 MPRNet 堆叠了多个 stage, 但是每个 stage 都能够和输入图像交互。与最近的恢复方法[70,88]类似,作者在输入图像上采用多patch的层次结构,将图像分割成不重叠的patch: stage-1分为4个patch, stage-2分为2个patch,最后一阶段的原始图像,如图2所示。
Complementary Feature Processing
现有的用于图像恢复的单阶段cnn通常使用以下架构设计之一:
- 编码器-解码器
- 单尺度特征流程
编码器-解码器网络[7,13,43,65]首先将输入逐步映射到低分辨率的表示,然后逐步应用反向映射恢复原来的分辨率。虽然这些模型有效地编码了多尺度信息,但由于重复使用降采样操作,容易牺牲空间细节。相比之下,单尺度特征流程的方法在生成具有精细空间细节的图像时是可靠的[6,18,93,97]。然而,由于感受野有限,它们的输出在语义上的鲁棒性较差。这表明了前面提到的架构设计选择的内在局限性,即能够生成空间上准确或上下文上可靠的输出,但不能同时生成两者。为了充分利用这两种设计的优点,这篇文章提出了一个多阶段的框架,其中早期阶段包括编码器-解码器网络,最后阶段使用一个基于原始输入分辨率的网络。
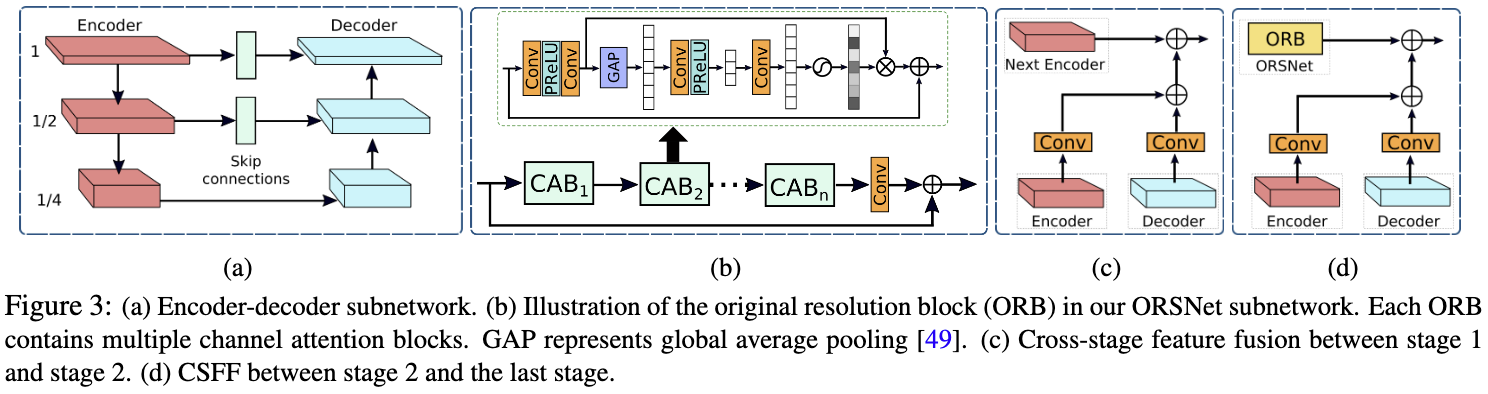
Encoder-Decoder Subnetwork. 图3a显示了编码器-解码器子网络的结构,它基于标准U-Net[65],具有以下组件: a) 首先,加入通道注意力块(CAB)[95],提取每个尺度上的特征(CAB见图3b)。 b) 对U-Net跳跃连接处的特征图进行CAB处理。 c) 使用双线性上采样和卷积层,而不是使用转置卷积来提高解码器特征的空间分辨率。这有助于减少由于转置卷积[55]在输出图像中经常出现的棋盘伪影。
Original Resolution Subnetwork. 为了保持从输入图像到输出图像的精细细节,在最后阶段引入了原始分辨率子网络(ORSNet)(见图2)。ORSNet不采用任何降采样操作,生成空间丰富的高分辨率特征。它由多个原始分辨率块(ORB)组成,每个ORB进一步包含CAB。ORB的原理图如图3b所示。
Cross-stage Feature Fusion
所提出的框架在两个编码器-解码器之间(见图3c)和编码器-解码器与ORSNet之间(见图3d)引入了CSFF模块。请注意,在将一个阶段的特征传播到下一个阶段进行聚合之前,首先使用 1x1 卷积对其进行细化。CSFF 有几个优点:a) 它减少了编码器-解码器中由于反复使用上采样和下采样操作而造成的信息丢失, 从而增强了网络的鲁棒性。 b) 一个阶段的多尺度特征有助于丰富下一个阶段的特征。 c) 网络优化过程变得更加稳定,因为它简化了信息的流动,从而允许在整体架构中添加几个阶段。
Supervised Attention Module
最近的图像恢复多阶段网络[70,88]直接在每一阶段预测一张图像,然后将其传递到连续的下一阶段。进而,作者在每两个阶段之间引入一个 supervise attention 模块,这有助于实现显著的性能增益。SAM的原理图如图4所示,它的贡献是有两点:a) 首先,它提供了对每一阶段的渐进式图像恢复有用的真实监督信号。 b) 在局部监督预测的帮助下,生成 attention map 来抑制当前阶段信息较少的特征,只允许有用的特征传播到下一阶段。
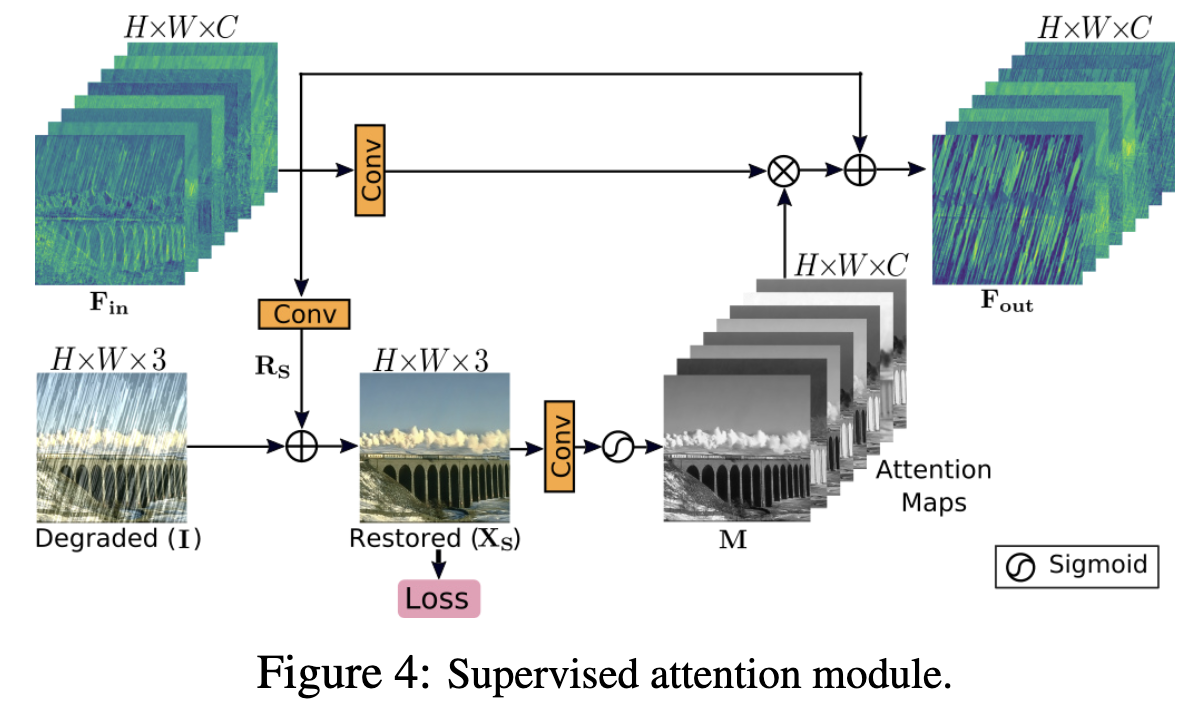
如图4所示,SAM将传入的前一阶段特征 $F_{in} \in \mathbb{R}^{H \times W \times C}$ 进行简单的 $1 \times 1$ 卷积生成残差图像 $R_S \in \mathbb{R}^{H \times W \times 3}$,其中 $H \times W$ 表示空间维数,$C$ 为通道数。残差图像加上退化输入图像 $I$ 得到复原图像 $X_S \in \mathbb{R}^{H \times W \times 3}$。 对于这个预测的图像 $X_S$,用ground truth图像提供了显式监督。接下来,使用 $1 \times 1$ 卷积加上 sigmoid激活从图像 $X_S$ 生成逐像素的 attention mask $M \in \mathbb{R}^{H \times W \times C}$。然后,这些 mask 被用来重新校准转换后的局部特征 $F_{in}$(通过 $1\times1$ 卷积得到),使得注意力引导的特征添加到恒等映射路径。最后,由SAM产生的注意力增强特征表示 $F_{out}$, 被传递到下一阶段进行进一步处理。
Conclusion
在这项工作中提出了一种多阶段的图像恢复架构,通过在每个阶段注入监督,逐步改善退化的输入。
作者设计制定了指导原则,要求在多个阶段进行互补的特征处理,并在它们之间进行灵活的信息交换。
为此,作者提出了 contextually-enriched 和 spatially accurate 阶段,以统一编码不同的特征集。
为了确保交互阶段之间的协同作用,作者提出了跨阶段的特征融合和注意力引导的早期到后期输出交换。
模型在众多基准数据集上获得了显著的性能提升。
此外,模型在模型大小方面是轻量级的,在运行时方面是高效的,这对于资源有限的设备来说非常有用。
-
Previous
【深度学习】MIRNetv2:Learning Enriched Features for Fast Image Restoration and Enhancement -
Next
【深度学习】HINet: Half Instance Normalization Network for Image Restoration